Regressionsvoraussetzung: Normalverteilung der Residuen
Arndt Regorz, Dipl. Kfm. & M.Sc. Psychologie, 20.08.2021
Eine der Voraussetzungen für eine einfache oder multiple Regression ist die Normalverteilung. Dieses Tutorial erklärt, was die Voraussetzung bedeutet, was die Folgen bei einer Verletzung sind, wie man diese Regressionsannahme prüfen kann und welche Alternativen es gibt, wenn sich bei der Prüfung Auffälligkeiten zeigen.
Inhalt
- Video-Tutorial
- Was bedeutet diese Voraussetzung?
- Folgen bei Verletzung der Normalverteilungsannahme
- Prüfung der Normalverteilung der Residuen (inkl. Umsetzung mit SPSS)
- Aufruf Prüfung der Normalverteilung mit R
- Alternativen, falls die Voraussetzung verletzt ist
- Quellen
1. Video-Tutorial
(Hinweis: Mit Anklicken des Videos wird ein Angebot des Anbieters YouTube genutzt.)
2. Was bedeutet diese Voraussetzung?
Da über die Bedeutung dieser Regressionsvoraussetzung viele falsche Annnahmen kursieren, wollen wir zunächst einmal ansehen, was diese Voraussetzung nicht bedeutet:
Es geht nicht um die Normalverteilung der verschiedenen Prädiktoren (unabhängige Variablen). Diese müssen ausdrücklich nicht normalverteilt sein - was man z.B. auch schon daran sehen kann, dass bei der multiplen Regression ohne Probleme binäre Prädiktorvariablen eingeschlossen werden können, wie z.B. das Geschlecht (m/w). Und eine binäre Variable ist nicht normalverteilt.
Es geht bei der Normalverteilung auch nicht darum, dass die Kriteriumsvariable (abhängige Variable) normalverteilt ist. Auch diese muss durchaus nicht normalverteilt sein für die Hypothesentest der einfachen oder multiplen Regression.
Was muss denn jetzt normalverteilt sein?
Die Normalverteilungsannahme betrifft die Fehler (Residuen), also die Unterschiede zwischen der modellierten Regressionsgerade und den tatsächlichen Werten.
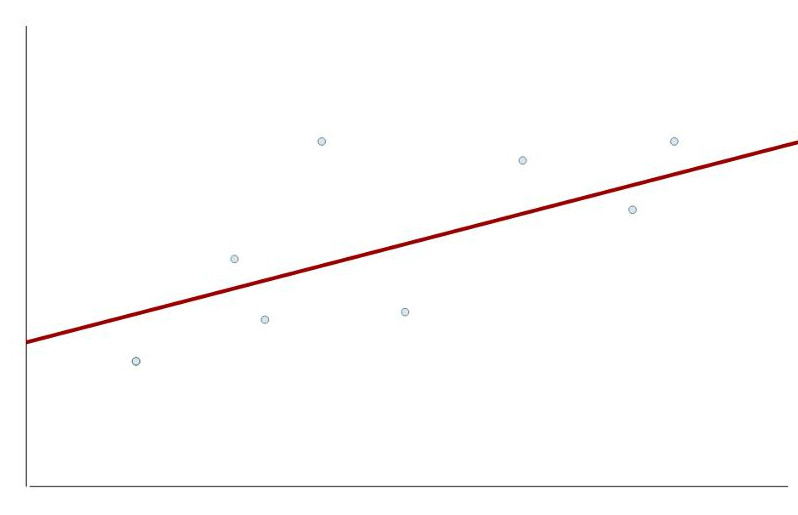
In der Realität erklärt ein lineare Regressionsmodell nie perfekt alle Beobachtungen. Damit entstehen Abweichungen zwischen den vorhergesagten Werte (in der Grafik oben auf der roten Linie) und den tatsächlichen Werten (in der Grafik die Punkte). Und diese Abweichungen (Residuen) sollten normalverteilt sein.
Hier muss man noch ein wenig präzisieren: Die Regressionsannahme ist, dass in der Population die Fehler normalverteilt sind. Es ist also durchaus möglich, dass diese Annahme erfüllt ist, auch wenn es in der konkreten Stichprobe mäßige Abweichungen von der Normalverteilung der geschätzten Fehler (Residuen) gibt.
3. Folgen bei Verletzung der Normalverteilungsannahme
Wenn die Normalverteilungsannahme verletzt ist, kann dennoch eine gute Schätzung der Regressionsparameter resultieren. Jedoch sind dann die Hypothesentests nicht mehr zuverlässig: also insbesondere die Tests der verschiedenen Regressionsgewichte, ob diese sich signifikant von Null unterscheiden. Genauer gesagt: Eine Verletzung der Normalverteilungsannahme kann zu falschen Standardfehlern führen, diese wiederum zu falschen Teststatistiken und diese dann zu falschen p-Werten und damit falschen Hypothesentestergebnissen.
Wenn Sie also nicht nur eine Regressionsgerade schätzen wollen, sondern auch für einzelne Prädiktoren testen möchten, ob diese einen signifikanten Einfluss haben, dann müssen Sie diese Regressionsvoraussetzung beachten.
4. Prüfung der Normalverteilung der Residuen
Wie oben dargelegt geht es um die Normalverteilung der Residuen. Und Residuen (tatsächliche Werte – vorhergesagte Werte) kann man erst ermitteln, wenn man die Regression bereits durchgeführt hat. Daraus ergibt sich direkt eine Erkenntnis: Die häufig praktizierte Prüfung der Prädiktoren und des Kriteriums einer Regression auf Normalverteilung (über Histogramm, Schiefe und Kurtosis, Testverfahren usw.) bringt hier nichts. Man kann die Normalverteilungsvoraussetzung erst prüfen, nachdem man die Regression schon durchgeführt hat: weil man erst dann die Residuen berechnen kann.
Und man kann immer nur die geschätzten Residuen in der Stichprobe prüfen, nicht die „wahren“ Fehler in der Grundgesamtheit. Insofern sind bei allen folgenden Prüfungen dieser Annahme leichte Abweichungen von der Normalverteilung der Residuen in der Stichprobe nicht zwingend ein Beweis für eine Verletzung der Annahme in der Grundgesamtheit.
Wie man die Normalverteilung testet, dafür gibt es mehrere Methoden mit unterschiedlichen Vor- und Nachteilen:
- Histogramm
- PP-Plot/QQ-Plot
- Signifikanztests
- Schiefe und Kurtosis
Histogramm der Residuen
Die erste (und von mir bevorzugte) Möglichkeit zur Prüfung der Normalverteilung der Residuen ist, ein Histogramm der Residuen zu erstellen und so die tatsächliche Verteilung der Residuen zu vergleichen mit der theoretischen Verteilung bei Gültigkeit der Normalverteilungsannahme.
In SPSS kann man dies im Unterdialog „Diagramme“ im Aufruf der linearen Regression auswählen:
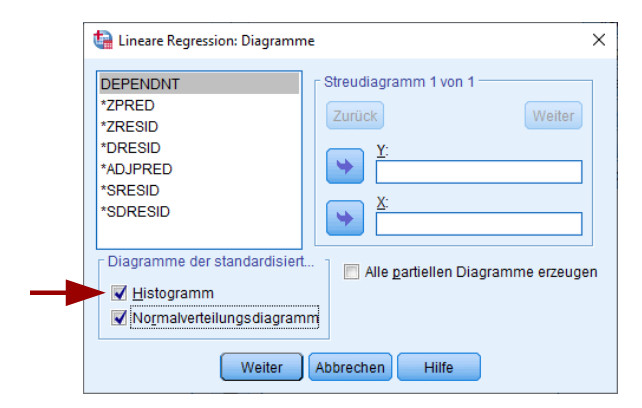
Als Ergebnis erhält man das Histogramm der standardisierten Residuen, wobei darüber die theoretische Verteilung bei perfekter Normalverteilung gelegt wird.
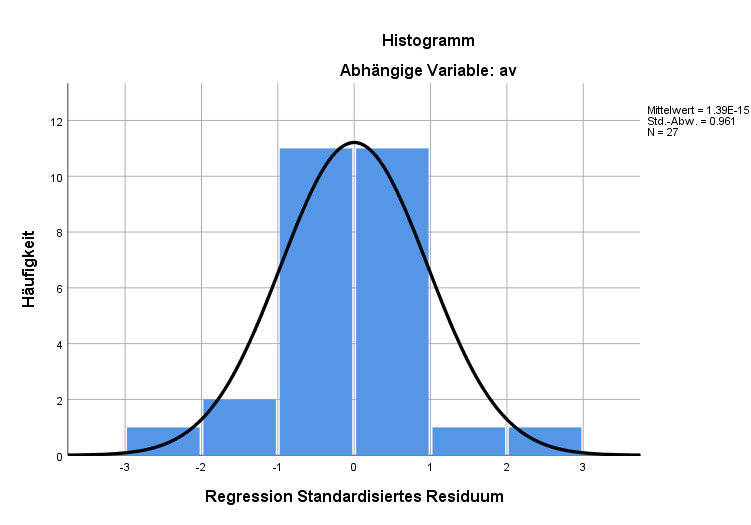
Gerade bei kleinen Stichproben (hier N = 27) wird man selten ein perfektes Bild einer Normalverteilung bekommen. Im Beispiel oben lag in der Grundgesamtheit tatsächlich eine Normalverteilung der Fehlerterme vor, aber die konkrete Stichprobe weicht dann doch ein wenig davon ab. Das ist völlig normal so, in diesem Histogramm gibt es für mich keine Hinweise auf eine Verletzung der Normalverteilung.
Generell ist bei der Interpretation der Histogramme wichtig, welche Verletzungen der Normalverteilungsannahme besonders problematisch sind für den Hypothesentest bei einer Regression: Dies sind sogenannte fat tails; damit ist gemeint, wenn die äußersten Ränder der Verteilung ganz rechts und ganz links im Histogramm deutlich stärker ausgeprägt sind als in der Normalverteilungskurve. Es sind vor allem solche Fälle, die zu einem fälschlicherweise signifikanten Hypothesentest führen können, auch wenn gar kein Zusammenhang in der Grundgesamtheit vorliegt. Wenn sich in der Mitte der Verteilung eine Abweichung von der Normalverteilung ergibt, hat das viel weniger Konsequenzen.
Der Nachteil einer solchen visuellen Prüfung der Normalverteilung ist, dass es sehr subjektiv ist, ab wann man von einer Verletzung der Normalverteilungsannahme ausgeht.
PP-Plot/QQ-Plot
Eine zweite, ebenso visuelle Prüfung auf die Normalverteilung sind PP-Plots und QQ-Plots. Beide sehr ähnlichen Verfahren vergleichen die tatsächliche Verteilung der Residuen mit der theoretisch bei Normalverteilung zu erwartenden. Der Unterschied ist nur, dass PP-Plots auf kumulierten Wahrscheinlichkeiten basieren, QQ-Plots auf Quantilen. Die Interpretation ist aber vergleichbar, hier werde ich es an einem PP-Plot verdeutlichen.
Den Aufruf aus SPSS erhält man aus dem gleichen Dialog wie das Histogramm:
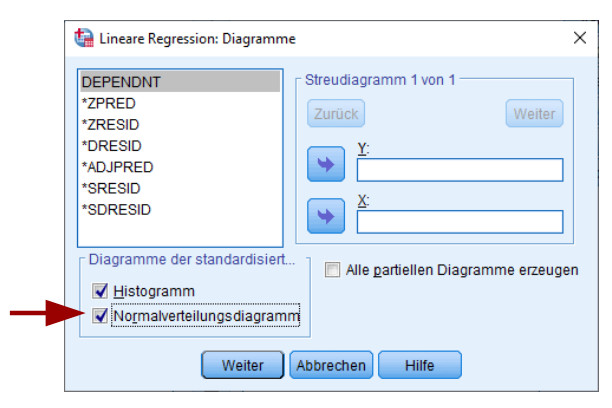
Auf der X-Achse sind die tatsächlich beobachteten kumulierten Wahrscheinlichkeiten der standardisierten Residuen aufgetragen, auf der Y-Achse die theoretischen bei Gültigkeit der Normalverteilung.
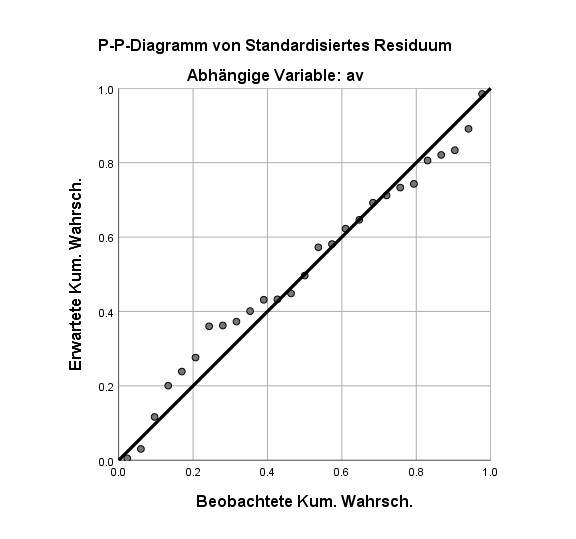
Im Falle einer Normalverteilung der Residuen liegen die Beobachtungen sehr nahe an der diagonalen Linie, bei größeren Abweichungen spricht dies gegen eine Normalverteilung. Auch hier gilt, dass primär die Ränder der Verteilung (Bereich ganz links, Bereich ganz rechts) von Bedeutung sind. Allerdings finde ich da die Interpretation der Histogramme etwas einfacher, dort sieht man direkt, ob der (problematische) Fall von fat tails vorliegt.
Der Nachteil dieses Verfahrens ist der Gleiche wie beim Histogramm: Die Interpretation ist subjektiv.
Signifikanztests
Neben den graphischen Tests oben gibt es auch Signifikanztests, mit denen geprüft werden kann, ob die Verteilung der Residuen signifikant von einer Normalverteilung abweicht. Die beiden wichtigsten sind der Kolmogorov-Smirnov-Test (kurz: K-S-Test) und der Shapiro-Wilk-Test. Beide Tests haben als Nullhypothese die Annahme, dass eine Normalverteilung vorliegt. Insofern sind hier jeweils signifikante Ergebnisse ein schlechtes Zeichen, weil sie auf Abweichungen von der Normalverteilung hindeuten.
Um diese Tests mit SPSS durchzuführen, müssen zunächst die Regressionsresiduen gespeichert werden. Dies erfolgt im Rahmen der linearen Regression in der Dialogbox „Speichern“
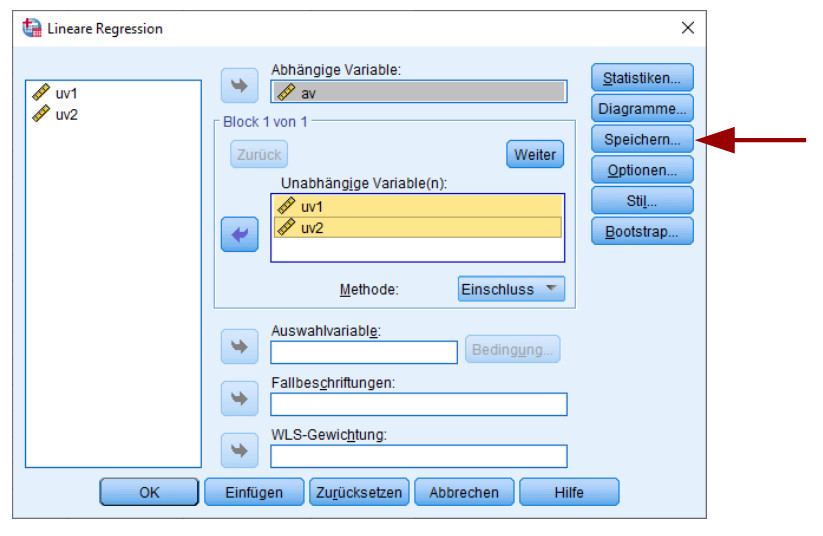
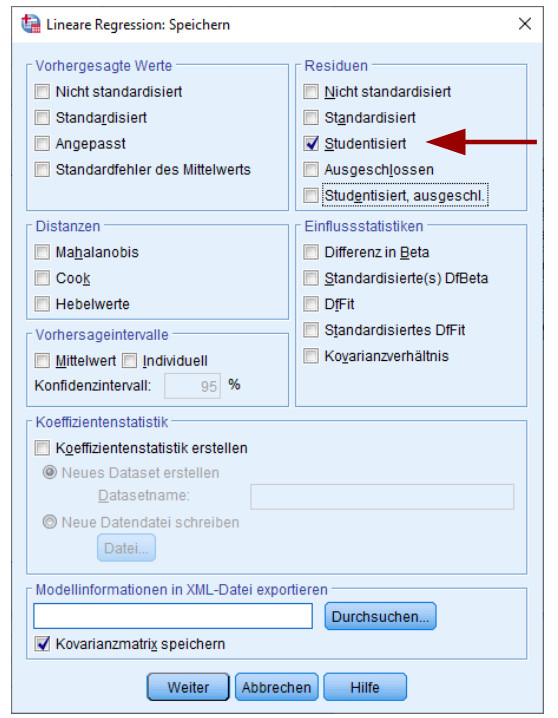
Damit erhält man eine neue Datenspalte im eigenen Datensatz, nämlich die gespeicherten Residuen. Diese kann man dann bei den deskriptiven Daten unter „Explorative Datenanalyse“ auf Normalverteilung testen, und zwar in der Dialogbox „Diagramme“.
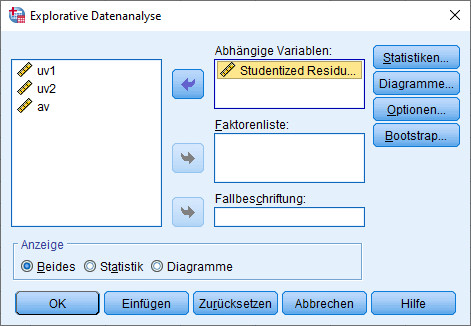
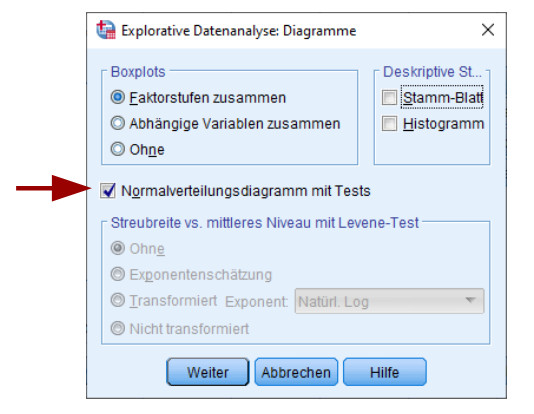
Als Ergebnis erhält man neben einem QQ-Diagramm eine kleine Tabelle mit den Ergebnissen von K-S-Test und Shapiro-Wilk-Test:

In unserem Beispiel sind beide Tests also nicht signifikant, was für die Annahme der Normalverteilung spricht.
Auf den ersten Blick erscheint diese Art der Prüfung auf Normalverteilung die beste Wahl zu sein, weil sie zu einem eindeutigen Ergebnis führt (zumindest meistens: manchmal haben K-S-Test und Shapiro-Wilk-Test unterschiedliche Ergebnisse – in dem Fall würde ich wohl ein bisschen mehr dem Shapiro-Wilk-Test vertrauen). Die Verwendung dieser beiden Tests hat jedoch recht gravierende Nachteile.
Bei sehr kleinen Stichproben reicht die Teststärke (Power) der beiden Tests häufig nicht aus, um Abweichungen zur Normalverteilung festzustellen. Man erhält dann u.U. kein signifikantes Testergebnis, obwohl die Residuen nicht normalverteilt sind. Bei sehr großen Stichproben hingegen werden bereits kleine und triviale Abweichungen von der Normalverteilung (die gar keine Probleme bei den Hypothesentests auslösen würden) signifikant.
Und das ist genau das Muster, was wir eigentlich nicht gebrauchen können. Bei kleinen Stichproben ist nämlich die Normalverteilungsannahme deutlich wichtiger (Stichwort: Zentraler Grenzwertsatz – dazu kommen wir noch später bei den Alternativen bei verletzter Annahme) als bei großen Stichproben. Also genau dann, wenn es für uns am wichtigsten ist, können wir uns auf die Ergebnisse von K-S-Test und Shapiro-Wilk-Test leider nicht verlassen.
Daher rate ich dringend davon ab, sich ausschließlich auf diese Hypothesentests zur Normalverteilung zu stützten. Aber sie können eine gute Ergänzung sein:
Wenn in kleinen Stichproben einer oder beide Tests signifikant wird trotz der geringen Teststärke, können Sie sich ziemlich sicher sein, dass Sie hier ein Problem mit der Verteilung haben. Wenn in großen Stichproben beide Tests nicht signifikant werden, dann wissen Sie, dass Sie dort kein Problem haben. Nur für die beiden anderen Fälle (kleine Stichprobe & nicht signifikant; große Stichprobe & signifikant) können Sie sich nicht darauf verlassen und sollten weitere Prüfungen auf die Normalverteilung vornehmen, z.B. mit den o.g. visuellen Tests.
Schiefe und Kurtosis
Eine weitere, nicht-visuelle Prüfung auf Normalverteilung ist die Betrachtung von Schiefe und Kurtosis. Dies sind weitere (neben Mittelwert und Varianz) Kenngrößen einer Verteilung und wenn man diese für die Verteilung der Residuen ermittelt, kann man sie vergleichen mit den Kenngrößen, die bei einer Normalverteilung zu erwarten wären.
Auch hierfür müssen Sie in SPSS erst einmal die Residuen speichern in der Dialogbox „Speichern“ der linearen Regression.
Anschließend führen Sie mit den Residuen eine explorative Datenanalyse durch:
Als Ergebnis bekommen Sie zahlreiche Kennwerte für die von Ihnen untersuchten Residuen, unter anderem Schiefe und Kurtosis (sowie die dazu gehörigen Standardfehler).
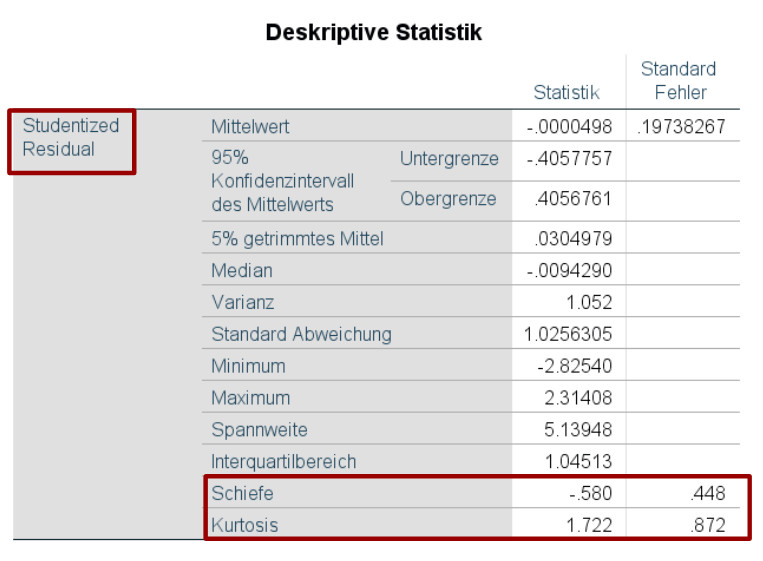
Die Schiefe einer Normalverteilung liegt bei 0. Für die Kurtosis ist bei SPSS eine Besonderheit zu berücksichtigen: An sich weist eine Normalverteilung eine Kurtosis von 3 auf. Jedoch zieht SPSS von der Kurtosis genau diese 3 ab, so dass bei der Kurtosis nach SPSS die Normalverteilung einen Wert von 0 für die Kurtosis aufweist.
Allerdings gibt es in der Literatur unterschiedliche Angaben, bis zu welchen Werten für Schiefe und Kurtosis von einer Einhaltung der Normalverteilungsvoraussetzung ausgegangen werden kann. Als Cut-Off-Werte werden in der Literatur dabei sehr unterschiedliche Grenze genannt, von |Schiefe| < 1 und |Kurtosis| < 3 bis hin zu |Schiefe| < 2 und |Kurtosis| < 7.
Das o.g. Beispiel mit einer Schiefe von –0.58 und einer Kurtosis von 1.72 (nach SPSS-Berechnung) spricht jedoch für eine Normalverteilung auf Basis der vorgenannten verschiedenen Cut-Off-Werte.
Neben dieser Orientierung an Cut-Off-Werten kann man mit Hilfe der auch in der explorativen Datenanalyse ausgewiesenen Standardfehler von Schiefe und Kurtosis einen Parametertest konstruieren. Diese Option nutze ich jedoch nie – wenn ich einen Parametertest auf Normalverteilung durchführen möchte, dann fordere ich lieber direkt den Shapiro-Wilk-Test an.
5. Aufruf Prüfung der Normalverteilung mit R
Die Basis für die folgende Diagnostik ist jeweils ein geschätztes Regressionsmodell, also z.B. als Ergebnis so eines Aufrufs:
reg.fit <- lm(AV ~ UV1 + UV2 + UV3, data=mein.datensatz)
Für die Diagnose werden die R-Packages olsrr und moments verwendet. Diese müssen wie jedes Package einmalig installiert werden (install.packages) und dann jeweils mit library geladen werden.
Histogramm der Residuen
library(olsrr)
ols_plot_resid_hist(reg.fit)
QQ-Plot
library(olsrr)
ols_plot_resid_qq(reg.fit)
Shapiro-Wilk-Test auf Normalverteilung
shapiro.test(reg.fit$residuals)
Schiefe und Kurtosis (mit moments-Package)
library(moments)
skewness(reg.fit$residuals)
kurtosis(reg.fit$residuals)
(Bei R bedeutet die Normalverteilung eine Schiefe von 0 und, anders als bei SPSS, richtigerweise eine Kurtosis von 3.)
Signifikanztests für Schiefe und Kurtosis
library(moments)
agostino.test(reg.fit$residuals)
anscombe.test(reg.fit$residuals)
6. Alternativen, falls die Voraussetzung verletzt ist
Wenn man aufgrund der o.g. Prüfung zum Ergebnis kommt, dass die Normalverteilungsannahme nicht erfüllt ist, dann stehen verschiedene Alternativen für die eigene Regressionsanalyse zur Verfügung:
Bootstrapping
Bootstrapping ist ein nicht-parametrisches Verfahren, mit dem man die Regressionsgewichte auch dann zuverlässig auf Signifikanz testen kann, wenn die Residuen nicht normalverteilt sind. Voraussetzung dafür ist eine hinreichend große Stichprobe, ab ca. N >= 50 kann man dieses Verfahren benutzen. Das ist aus meiner Sicht die optimale Lösung für dieses Problem.
Wie das geht, ist in meinem folgenden Tutorial beschrieben: Bootstrapping bei Regression
Zentraler Grenzwertsatz
Der Zentrale Grenzwertsatz besagt, dass die entsprechend standardisierte Summe unabhängiger, identisch verteilter Zufallsvariablen für ausreichend große Stichproben gegen die Standardnormalverteilung konvergiert. Und aus diesem Grenzwertsatz kann man für die Regressionsanalyse ableiten, dass für hinreichend große Stichproben eine Verletzung der Normalverteilungsannahme kein Problem ist.
In dieser Aussage steckt ein offensichtliches Problem: Wann ist eine Stichprobe hinreichend groß, dass man sich auf den Zentralen Grenzwertsatz verlassen kann? Dazu gibt es sehr unterschiedliche Meinungen.
Teilweise findet man in der Literatur als entscheidenden Wert N > 30. Diese Angaben sind jedoch als veraltete anzusehen; sie wurden vor langer Zeit mit relativ gutartigen Abweichungen von der Normalverteilung ermittelt und gelten nicht für alle in der Praxis möglichen Verteilungen.
Lumley, Diehr, Emerson und Chen (2002) haben aus einem konkreten Teilgebiet (Gesundheitsökonomie) für verschiedene Datenstrukturen empirisch per Simulation geprüft, ab welchem N man recht sicher davon ausgehen kann, dass auch bei einer verletzten Normalverteilungsannahme die Regression korrekt getestet werden kann. Zwar konnte man schon bei N = 100 häufig zutreffende Ergebnisse erzielen, aber bei extremeren Verteilungen reichte das noch nicht als Stichprobengröße. Für relativ extreme Abweichungen von der Normalverteilung fanden Lumley et al. (2002), dass bereits bei weniger als N = 500 Untersuchungseinheiten der Zentrale Grenzwertsatz griff und die Abweichung der Normalverteilung keine Rolle spielte.
Aus praktischer Sicht spricht für mich daher fast nichts für das Sich-Berufen auf den Zentralen Grenzwertsatz. Denn wenn man stattdessen mit Bootstrapping arbeitet, ist man auf jeden Fall auf der sicheren Seite. Und bei Stichproben mit N < 50, für die man Bootstrapping nicht anwenden sollte, wäre das Vertrauen auf den Zentralen Grenzwertsatz recht riskant. Aber bei Stichprobengrößen über N = 500 spricht m.E. auch nichts gegen die Berufung auf den Zentralen Grenzwertsatz.
Allerdings ist diese angebliche Grenze von 30 Untersuchungseinheiten für den Zentralen Grenzwertsatz auch so stark bei Prüfern verbreitet, dass es Ihnen durchaus passieren kann, dass Ihr Prüfer/Betreuer darauf verweist und daher gar kein Problem mit der Normalverteilung sieht. Der Prüfer hat immer recht (auch wenn er nicht recht hat); in diesem speziellen Fall kann es dann durchaus Sinn machen, nicht dagegen anzukämpfen und sich auf den Grenzwertsatz zu berufen (eine entsprechende Literaturquelle zum Beleg vorausgesetzt).
Datentransformation
Für Stichproben ab ca. 50 Untersuchungseinheiten steht mit Bootstrapping (s.o.) eine einfache und stabile Alternative zur Verfügung. Doch was macht man bei kleineren Stichproben, wenn man eine Verletzung der Normalverteilung feststellt bzw. vermutet? Dann ist auch der Zentrale Grenzwertsatz keine Lösung.
Hier gibt es noch die Möglichkeit, Prädiktor(en) und/oder Kriterium so zu transformieren, dass bei Durchführung der Regression mit den transformierten Variablen die daraus errechneten Residuen normalverteilt sind. Das ist allerdings von Durchführung und vor allem auch Interpretation um einiges schwieriger als die Verwendung von Bootstrapping.
Die wohl mächtigste Datentransformation für derartige Problemstellungen ist die Box-Cox-Transformation. Im unten aufgeführten Artikel von Osborne (2010) wird demonstriert, wie man diese mit SPSS einsetzen kann.
7. Quellen
Field, A. (2013). Discovering statistics using IBM SPSS statistics: And sex and drugs and rock 'n' roll (4th edition). SAGE.
Gujarati, D. (2009). Basic Econometrics (4th edition). Tata McGraw-Hill.
Hebbali, A. (2020). Package 'olsrr'. CRAN. https://cran.r-project.org/web/packages/olsrr/olsrr.pdf
Komsta, L. (1995). Package 'moments'. CRAN. https://cran.r-project.org/web/packages/moments/moments.pdf
Lumley, T., Diehr, P., Emerson, S., & Chen, L. (2002). The importance of the normality assumption in large public health data sets. Annual review of public health, 23 (1), 151-169. https://www.annualreviews.org/doi/full/10.1146/annurev.publhealth.23.100901.140546
MRC Cognition and Brain Sciences Unit (2018). Testing normality including skewness and kurtosis. http://imaging.mrc-cbu.cam.ac.uk/statswiki/FAQ/Simon
Osborne, J. (2010). Improving your data transformations: Applying the Box-Cox transformation. Practical Assessment, Research, and Evaluation, 15(1), 12. https://scholarworks.umass.edu/cgi/viewcontent.cgi?article=1238&context=pare
Weitere Tutorials zu Regressionsvoraussetzungen:
- Homoskedastizität
- Linearität
- Keine starke Multikollinearität
- Unkorreliertheit der Fehler bzw. Residuen
- Geeignete Skaleneigenschaften
- Keine starken Ausreißer