Regressionsvoraussetzungen: Homoskedastizität (Varianzhomogenität)
Arndt Regorz, Dipl. Kfm. & M.Sc. Psychologie, Stand: 20.08.2021
Eine der Voraussetzungen der Regressionsanalyse ist Homoskedastizität (Gegenteil: Heteroskedastizität) der Residuen. Diese Voraussetzung sollten Sie prüfen, wenn Sie eine Regression im Rahmen Ihrer Bachelorarbeit oder Masterarbeit durchführen wollen.
In diesem Tutorial wird genauer beschrieben:
- Was genau ist Homoskedastizität und dessen Gegenteil, Heteroskedastizität?
- Was sind mögliche Ursachen für Heteroskedastizität im Rahmen einer Regression?
- Was sind die Folgen von Heteroskedastizität?
- Wie prüft man, ob Homoskedastizität vorliegt (incl. der Anwendung in SPSS)?
- Aufruf der Prüfung in R
- Mit welchen Verfahren kann man dennoch eine Regression durchführen, wenn Heteroskedastizität vorliegt?
Inhalt
- Video-Tutorial
- Was ist Homoskedastizität?
- Mögliche Ursachen für Heteroskedastizität
- Folgen von Heteroskedastizität
- Prüfung auf Homoskedastizität
- Aufruf in SPSS
- Aufruf in R
- Alternativen zur gewöhnlichen Regression bei Heteroskedastizität
- Quellen
1. YouTube-Video-Tutorial
(Hinweis: Mit Anklicken des Videos wird ein Angebot des Anbieters YouTube genutzt.)
Inhaltlicher Korrekturhinweis zum Video: Zwar kann man mit Bootstrapping Probleme durch Heteroskedastizität in der Regel reduzieren, sie je nach Boostrapping-Verfahren jedoch nicht völlig beseitigen. Insofern sollten Sie auch beim Einsatz von Boostrapping die Homoskedastizitätseigenschaft überprüfen.
2. Was ist Homoskedastizität?
Homoskedastizität ist vergleichbar mit dem, was im Rahmen der Varianzanalyse als Varianzhomogenität bezeichnet wird. Es bedeutet also, dass Varianzen gleich sein müssen.
Doch zunächst einmal: welche Varianzen sollen bei der Regression gleich sein?
Es geht nicht um die Varianzen der unabhängigen Variablen X1, X2,...
Es geht nicht um die Varianzen der abhängigen Variable Y.
Sondern: Es geht um die Varianzen der Residuen.
Die Residuen (Abweichungen der Y-Werte zur vorhergesagten Regressionsgerade) sollen also für alle Ausprägungen der unabhängigen Variable/n die gleiche Streuung aufweisen.
Am Beispiel einer einfachen Regression wäre hier sichtbar Homoskedastizität gegeben, da für alle X die Residuen eine vergleichbare Streuung aufweisen:
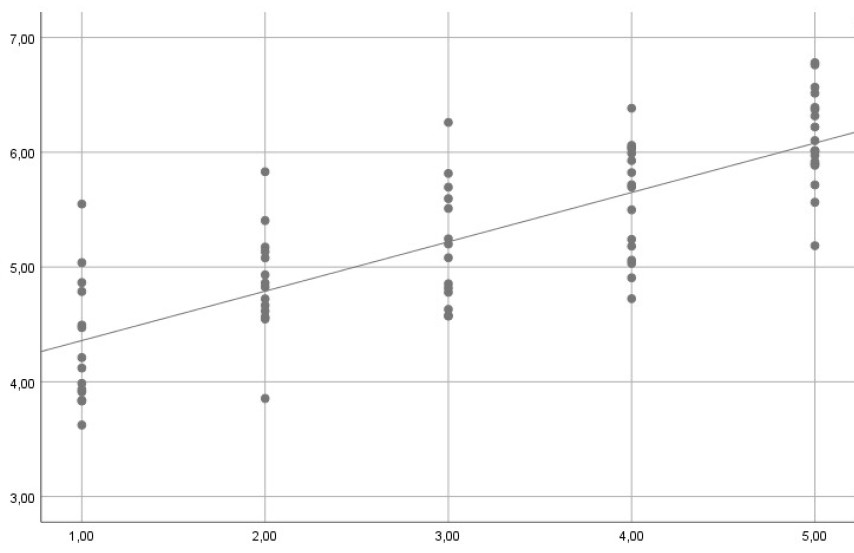
Im folgenden Beispiel hingegen würde Heteroskedastizität vorliegen. Denn hier weisen die Residuen für höhere Werte von X eine stärke Streuung auf:
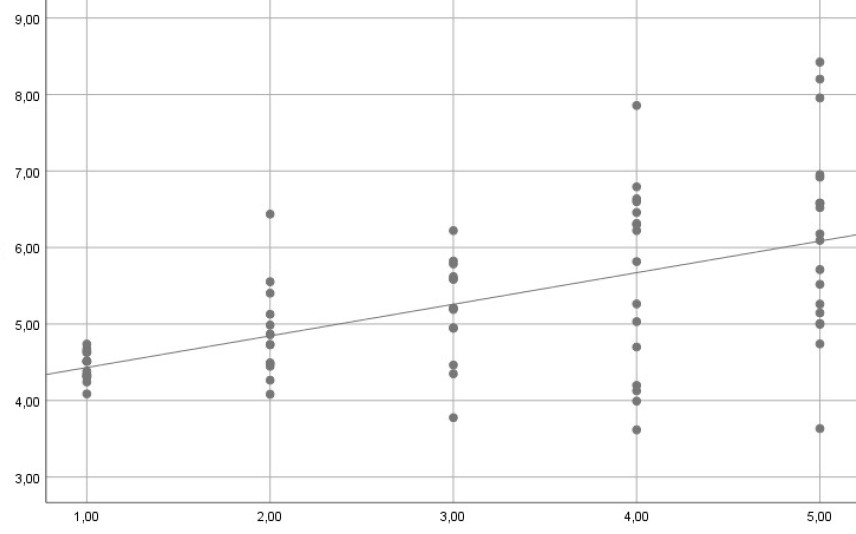
Das sind jeweils Beispiele, in denen für jeden Wert von X mehrere Y-Werte vorliegen. Was aber bedeutet Homoskedastizität, wenn es für jede Ausprägung von X nur einen einzigen Y-Wert gibt? Wie kann man denn für einen einzelnen Wert eine Varianz berechnen – Varianzen beschreiben ja wie Mittelwerte keine einzelnen Beobachtungen, sondern ganze Verteilungen?
Die Eigenschaft der Homoskedastizität bezieht sich nicht primär auf die vorliegende Stichprobe, sondern auf die theoretischen Verhältnisse in der Grundgesamtheit, aus der die Stichprobe gezogen wurde: Es geht um die Varianz der (nicht beobachtbaren) wahren Residuen. Auch wenn in einer konkreten Stichproben für ein X nur ein einziger Y-Wert vorliegt, kann man sich vorstellen, dass die Stichprobenziehung wiederholt wird. Und wenn man z.B. ein Experiment viele tausend Male wiederholt, dann könnte man für jeden X-Wert die Varianz der resultierenden Y-Werte ermitteln. Und diese Varianzen sollen gleich sein.
Da wir jedoch die Grundgesamtheit nicht direkt beobachten können, müssen wir die Stichprobe betrachten, um eine eventuelle Heteroskedastizität zu diagnostizieren. Aber auch dabei geht es immer um eine Aussage über die Grundgesamtheit: Wir betrachten die Stichprobe um abzuschätzen, ob in der Grundgesamtheit die Varianzen homogen sind oder nicht.
3. Was sind mögliche Ursachen für Heteroskedastizität?
Für inhomogene Varianzen gibt es verschiedene mögliche Ursachen. Einige sind nachfolgend aufgeführt:
a) Nicht-linearer Zusammenhang (fehlspezifiziertes Modell)
Wenn der Zusammenhang zwischen unabhängiger Variable und abhängiger Variable nicht linear ist, dann führt dies in der Regel zu unterschiedlichen Varianzen. Im nachfolgenden Beispiel liegt tatsächlich ein quadratischer Zusammenhang vor. Wenn man stattdessen eine Regressionsgerade schätzt, gibt es Bereiche mit relativ geringen Schwankungen der Residuen um den vorhergesagten Wert und Bereiche mit größeren Abweichungen.
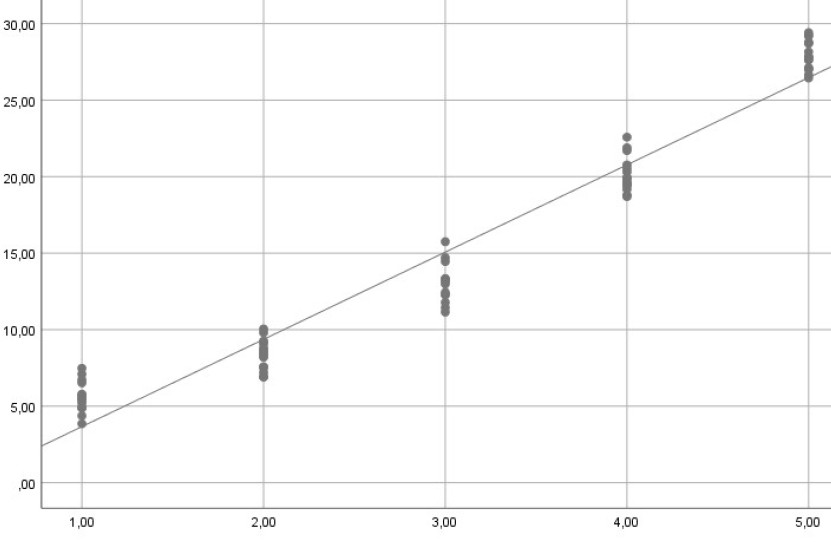
b) Fehlender Prädiktor (fehlspezifiziertes Modell)
Neben einem nicht-linearen Zusammenhang gibt es noch eine zweite Möglichkeit, aufgrund einer Fehlspezifikation des Modells Heteroskedastizität zu erzeugen: wenn ein oder mehrere relevante Prädiktoren fehlen. Die mit nicht aufgenommenen Prädiktoren verbundene Varianz kann in diesem Fall nämlich teilweise im Fehlerterm und damit in den Residuen zum Vorschein kommen, was zu systematischen Schwankungen in der Residualvarianz führen kann.
c) „Scale-Variable“
Ein weiterer häufiger Fall von Heteroskedastizität liegt vor, wenn in Abhängigkeit von einer unabhängigen Variable die Varianz systematisch zunimmt.
Ein Beispiel wäre das verfügbare Einkommen als unabhängige Variable und Konsum als abhängige Variable. Hier ist zu erwarten, dass jemand mit 12.000 Euro verfügbarem Jahreseinkommen eine viel geringere Varianz des jährlichen Konsums aufweist als jemand mit 1,2 Mio. Euro Jahreseinkommen. Dieser Effekt ist vor allem bei Querschnittsdaten relevant.
d) Messfehler
Auch Veränderungen von Messfehlern können eine Ursache für inhomogene Varianzen sein. So wurden im 19. Jahrhundert volkswirtschaftliche Daten mit wesentlich geringerer Genauigkeit gemessen als dies heute im Computerzeitalter möglich ist. Eine entsprechende Zeitreihenanalyse für einen derart langen Zeitraum wird daher vermutlich mit einem Rückgang der Varianzen einher gehen.
4. Was sind die Folgen von Heteroskedastizität?
Auch in diesem Fall ist der Schätzer über die gewöhnliche Regression weiter erwartungstreu (unverzerrt).
Allerdings ist die Schätzung ineffizient, es gibt also u.U. andere Schätzer, die zu einer genaueren Schätzung der Parameter führen. Genauer bedeutet hier, dass die Varianz der Schätzung niedriger ist.
Das Hauptproblem ist jedoch ein anderes: Der übliche Standardfehler der geschätzten Regressionsparameter stimmt nicht mehr. Und damit können auch Signifikanztests zu falschen Ergebnissen führen!
5. Prüfung auf Homoskedastizität
In verschiedenen Fachrichtungen sind unterschiedliche diagnostische Verfahren hierfür verbreitet. In den Wirtschaftswissenschaften (hier insbesondere im Teilgebiet Ökonometrie) werden eher formale Hypothesentests verwendet. In der Psychologie und anderen verwandten Sozialwissenschaften hingegen wird häufig die Betrachtung der Residuen in einem Diagramm zur Diagnose vorgezogen.
Zunächst wird die Diagnose mit einem Residuendiagramm dargestellt.
Hierzu werden auf der x-Achse die standardisierten vorhergesagten Werte (y-dach) und auf der y-Achse die studentisierten Residuen (oder alternativ dazu die ausgelassenen-studentisierten Residuen) abgetragen.
Bei Homoskedastizität sollten die Residuen unsystematisch um ihren Nullpunkt streuen, siehe z.B.:
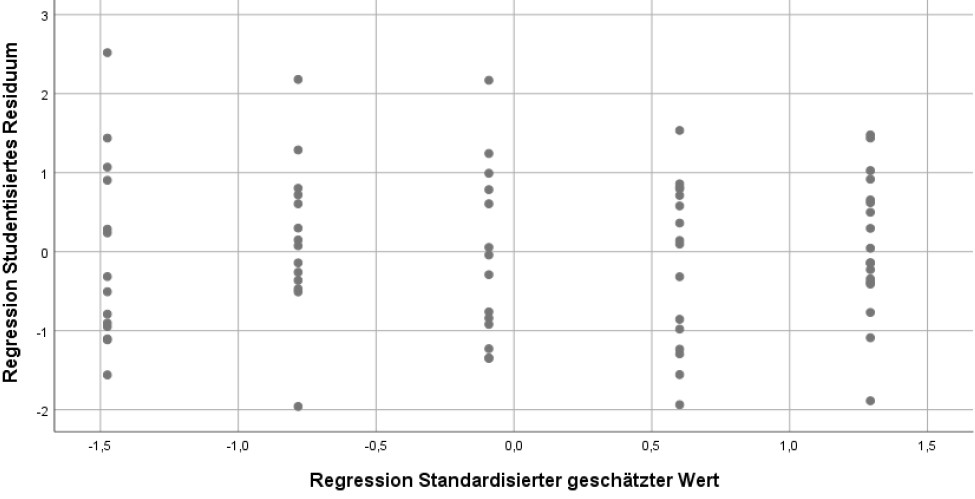
(Dabei darf man sich allerdings nicht durch einzelne Ausreißer irritieren lassen. Der o.g. Datensatz ist tatsächlich mit vollständig homogenen Varianzen erzeugt worden, aber durch Zufallseinflüsse gibt es immer eine gewisse Schwankung der Varianzen zwischen den verschiedenen x-Werten.)
Sobald sich systematische Unterschiede in der Streuung ergeben, ist das ein Warnsignal. Hier wäre beispielsweise ein Streuungsmuster bei ungleichen Varianzen, wie es im Fall einer scale variable auftreten könnte. Typisch dafür ist die Form eines seitlich liegenden Trichters:
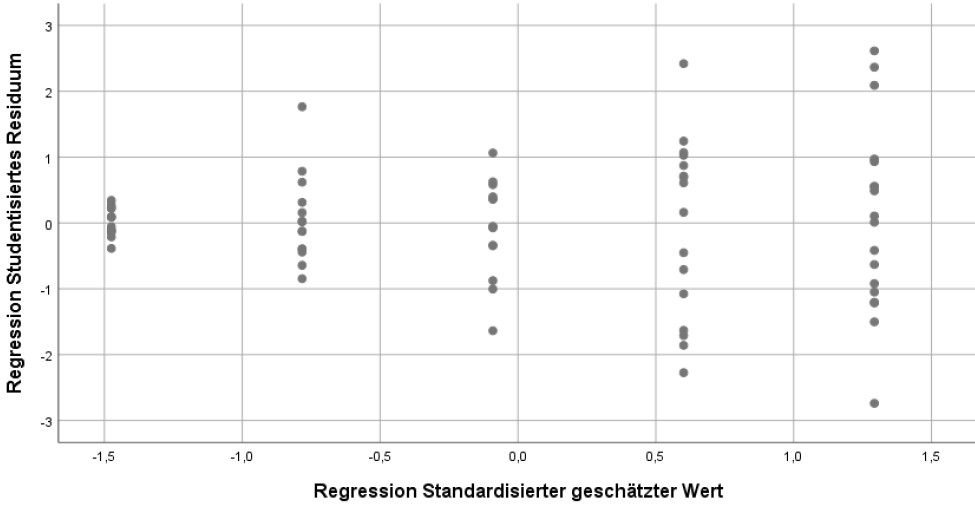
Aber auch andere systematische Muster können auftreten. Hier wäre ein Beispiel für das Streuungsmuster bei einer fehlerhaften Modellspezifikation (tatsächlich quadratischer statt lineare Zusammenhang).
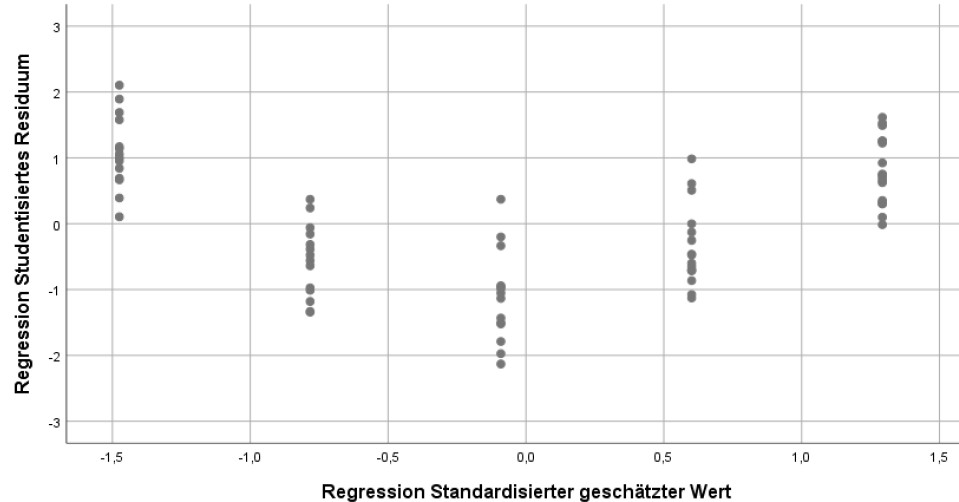
Statt der Residuen werden manchmal auch die quadratischen Residuen auf der y-Achse dargestellt. Damit kann man ebenso ungleiche Varianzen aufdecken, aber um Fehlspezifikationen des Modells zu finden, eignet sich m.E. die vorherige Darstellung besser.
Bei der Betrachtung von Streudiagrammen zur Diagnose kann ein Problem auftreten: Wenn Ihre unabhängige und abhängige Variable nicht kontinuierlich sind, sondern nur aus wenigen unterschiedlichen Ausprägungen besteht. Das tritt dann auf, wenn Sie Skalen mit sehr wenigen Items oder sogar nur einzelne Items als Variablen verwenden. Dann bekommen Sie möglicherweise als Streudiagramm nur ein Gitternetz, aus dem Sie gar nichts sehen können. Hier hilft dann häufig die Technik des "Jittering".
Als Hypothesentests auf Heteroskedastizität kommen insbesondere in Frage:
- Breusch-Pagan-Test
- White-Test
- Goldfeld–Quandt Test
6. Aufruf Heteroskedastizitäts-Diagnostik in SPSS
Sie können die o.g. Diagramme der Residuen ganz einfach bei der Regression mit aufrufen. In der Syntax müssen Sie nur eine Zeile (unten fett) anfügen. In diesem Beispiel ist y die abhängige Variable, x1 und x2 sind die unabhängigen Variablen – diese müssen Sie auf Ihre Variablennamen anpassen.
REGRESSION
/MISSING LISTWISE
/STATISTICS COEFF OUTS R ANOVA
/CRITERIA=PIN(.05) POUT(.10)
/NOORIGIN
/DEPENDENT y
/METHOD=ENTER x1 x2
/SCATTERPLOT=(*SRESID ,*ZPRED).
(Hinweis: Achten Sie bitte darauf, dass der Punkt nur nach der letzten Zeile des Regressionskommandos steht.)
Den Aufruf aus dem Menü finden Sie unter Analysen-Regression-Linear, dann rechts auf „Diagramme“ klicken und *SRESID bei Y und *ZPRED bei X eintragen und auf „OK“ klicken.
Alternativ zu den studentisierten Residuen können auch die ausgelassenen-studentisierten Residuen verwendet werden, die Vorteile für bestimmte Tests in der Ausreißerdiagnostik bieten und für die Diagnostik ebenso geeignet sind. In diesem Fall ersetzen Sie einfach *SRESID durch *SDRESID.
7. Aufruf Heteroskedastizitäts-Diagnostik in R
Die Basis für die folgende Ausreißerdiagnostik ist jeweils ein geschätztes Regressionsmodell, also z.B. als Ergebnis so eines Aufrufs:
reg.fit <- lm(AV ~ UV1 + UV2 + UV3, data=mein.datensatz)
Für die Diagnose wird jeweils das R-Package olsrr verwendet. Dieses muss wie jedes Package einmalig installiert werden (install.packages) und dann jeweils mit library geladen werden.
Streudiagramm Fitted Values und Residuen
library(olsrr)
ols_plot_resid_fit(reg.fit)
Breusch Pagan Test
library(olsrr)
ols_test_breusch_pagan(reg.fit)
8. Alternativen zur gewöhnlichen Regression bei Heteroskedastizität
Bevor wir uns damit beschäftigen, wie Sie auch bei verletzter Voraussetzung die Regression korrekt durchführen können, ein wichtiger Hinweis:
Ungleiche Varianzen können auch ein Indiz für ein fehlspezifiziertes Modell sein. Wenn Sie in so einem Fall Korrekturverfahren für inhomogene Varianzen anwenden, dann ändert das nichts daran, dass Sie möglicherweise ein falsches Modell testen!
Das ist ein bisschen wie mit Schmerzen: Wenn man Schmerzen hat und ein Schmerzmittel nimmt, dann gehen zwar vielleicht die Schmerzen weg. Aber möglicherweise sind die Schmerzen ein Warnsignal auf ein ernsteres Problem, das dabei unbehandelt bleibt.
Insofern sollten Sie immer zuerst prüfen, ob es Anzeichen für ein fehlerhaft aufgestelltes Modell gibt (also eine Verletzung der Linearitätsbedingung), bevor Sie eines der folgenden Korrekturverfahren anwenden. Und bei einem fehlspezifizierten Modell ist der Ausweg, das Modell und den Modelltest entsprechend zu verändern (z.B. polynomiale Regression, nichtlineare Regression, Variablentransformation).
Alternative 1: Bootstrapping
Wenn Sie mindestens N = 50 Beobachtungen für Ihre Regression haben, bietet sich eine Regression mit Bootstrapping als Teil-Lösung an. Das ist ein nonparametrisches Verfahren, das in der Regel die Folgen von Heteroskedastizität reduziert (Baltes-Götz, 2018, pp. 57-58) und als weiteren Vorteil auch ohne die Normalverteilungsannahme auskommt.
Wenn Sie mehr darüber erfahren wollen, dann können Sie in meinem Tutorial „Regression mit Bootstrapping“ sowohl die Grundlagen dieses Verfahrens kennenlernen, als auch die konkrete Umsetzung in SPSS.
Alternative 2: WLS
Beim Weighted-Least-Squares-Verfahren (WLS) werden die einzelnen Beobachtungen anhand ihrer Varianz unterschiedlich gewichtet. Ungenaue Beobachtungen mit hoher Varianz werden von ihrer Bedeutung für die Regressionsschätzung abgewertet, die genaueren Beobachtungen mit niedriger Varianz hingegen werden stärker gewichtet. Das führt zu einer Homogenisierung der Varianzen.
Damit ergeben sich bei diesem Verfahren nicht nur realistischere Standardfehler, sondern außerdem auch effizientere Schätzungen der Regressionsparameter selbst.
Allerdings ist dieses Verfahren deutlich aufwändiger als die anderen hier vorgestellten Alternativen. Der Einsatz von WLS ist aus meiner Sicht primär dann zu empfehlen, wenn es nicht nur um einen Hypothesentest geht, sondern um eine konkrete Vorhersage:
Wenn man nur testen möchte, ob sich z.B. ein Regressionsgewicht signifikant von Null unterscheidet, ist die Präzision der Schätzung für dieses Gewicht nicht so wichtig – entscheidend ist ein korrekter Standardfehler. Dafür sind andere Verfahren in der Regel einfacher umzusetzen.
Wenn man hingegen ein Regressionsmodell aufstellt, um zukünftige Werte vorherzusagen (z.B. Absatzzahlen eines Produktes in einem Unternehmen, Arbeitslosenzahlen in einer Volkswirtschaft etc.), dann kommt es auch auf eine möglichst präzise Schätzung der Regressionsgewichte an. In so einem Fall sollte man m.E. WLS den Vorzug geben.
Alternative 3: Transformationen
Manchmal kann auch durch eine Transformation der Modellvariablen eine Varianzhomogenität herbeigeführt werden. Ein Beispiel dafür wäre die Box-Cox-Transformation.
Alternative 4: Heteroskedastizität adjustierte Standardfehler (HC3, HC4)
Das Hauptproblem bei fehlender Varianzhomogenität sind die falsch berechneten Standardfehler. Diese führen möglicherweise zu falschen Ergebnissen bei den Hypothesentests.
Daher ist eine mögliche Lösung, die Berechnung der Standardfehler entsprechend zu korrigieren. Man verwendet sogenannte robuste Standardfehler. Wie man das in SPSS umsetzt, können Sie hier nachlesen: Robuste Standardfehler bei Heteroskedastizität .
9. Quellen
Baltes-Götz, B. (2018). Lineare Regressionsanalyse mit SPSS. [Rev. 180102]. Retrieved from: https://www.uni-trier.de/fileadmin/urt/doku/linreg/linreg.pdf
Field, A. (2013). Discovering statistics using IBM SPSS statistics: And sex and drugs and rock 'n' roll (4th edition). Los Angeles, CA: SAGE.
Hebbali, A. (2020). Package 'olsrr'. CRAN. https://cran.r-project.org/web/packages/olsrr/olsrr.pdf
Long, J. S., & Ervin, L. H. (2000). Using heteroscedasticity consistent standard errors in the linear regression model. The American Statistician, 54, 217-224. doi:10.1080/00031305.2000.10474549
Sakia, R. M. (1992). The Box-Cox transformation technique: A review. The Statistician, 41, 169-178. doi:10.2307/2348250
Weitere Tutorials zu Regressionsvoraussetzungen:
- Normalverteilung
- Linearität
- Keine starke Multikollinearität
- Unkorreliertheit der Fehler bzw. Residuen
- Geeignete Skaleneigenschaften
- Keine starken Ausreißer