Regressionsvoraussetzung: Keine starke Multikollinearität
Arndt Regorz, Dipl. Kfm. & M.Sc. Psychologie, 20.08.2021
Es ist eine der Voraussetzungen der multiplen Regressionsanalyse (also einer Regression mit mehr als einem Prädiktor), dass zwischen den Prädiktoren keine starke Multikollinearität vorliegt. Diese Voraussetzung sollten Sie prüfen, wenn Sie im Rahmen Ihrer Bachelorarbeit oder Masterarbeit eine multiple Regression durchführen wollen.
Inhalt
- Was bedeutet Multikollinearität?
- Warum ist Multikollinearität ein Problem bei der Regression?
- Was sind die Konsequenzen von starker Multikollinearität?
- Was sind mögliche Ursachen für Multikollinearität?
- Wie diagnostiziert man Multikollinearität?
- Aufruf in SPSS
- Aufruf in R
- Was kann man tun, wenn starke Multikollinearität vorliegt?
- Quellen
1. Was bedeutet Multikollinearität?
Multikollinearität bedeutet, dass (mindestens) ein Prädiktor durch einen oder mehrere andere Prädiktoren zusammen im Wesentlichen vorhergesagt werden kann.
Beispiel:
Sie haben die drei Prädiktoren (auf Basis von Items mit Likert-Skalierung), die Sie getrennt in eine Regression einschließen (was man wie hier aus guten Gründen so nicht machen würde):
X1: „Mir geht es gut“
X2: „Ich fühle mich gut“
X3: „Ich bin optimistisch hinsichtlich der Zukunft“
Die ersten beiden Prädiktoren messen vermutlich fast genau das gleiche. Wenn man von einer Person den Wert auf der Variable X1 kennt, dann kann man wahrscheinlich meistens auch den Wert auf der Variable X2 vorhersagen. Und das führt zu statistischen Problemen.
2. Warum ist Multikollinearität ein Problem bei der Regression?
Bei der multiplen Regression wird bei der Bestimmung des Regressionsgewichts für einen Prädiktor die gemeinsame Varianz mit den anderen Prädiktoren herausgerechnet („auspartialisiert“), sowohl aus dem Prädiktor als auch aus dem Kriterium.
In folgendem Diagramm mit zwei Prädiktoren sollen Überschneidungen jeweils gemeinsame Varianz darstellen. Für die Berechnung des Regressionsgewichts für X1 ist nur der farbige Teil relevant, der nicht mit dem anderen Prädiktor X2 im Modell zusammenhängt.
Dabei wird die gemeinsame Varianz von X1 und Y nach Auspartialisierung von X2 genommen (Schnittmenge, im Diagramm mit „G“ gekennzeichnet) und zur Varianz von X1 nach Auspartialisierung von X2 ins Verhältnis gesetzt (im Diagramm rot markiert):
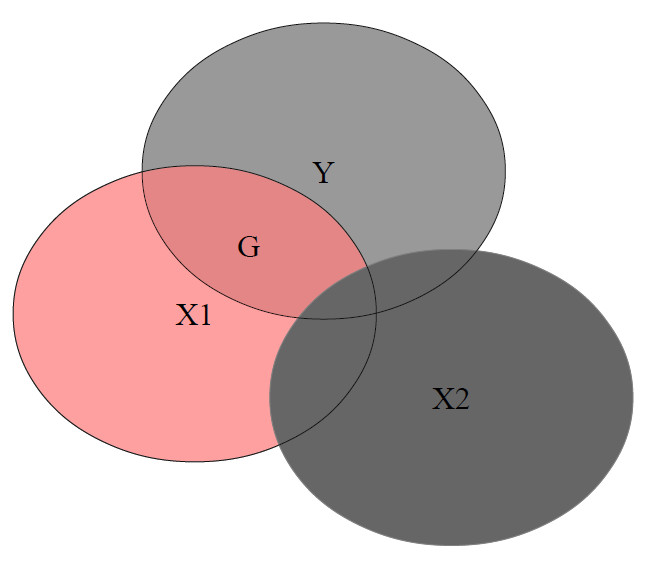
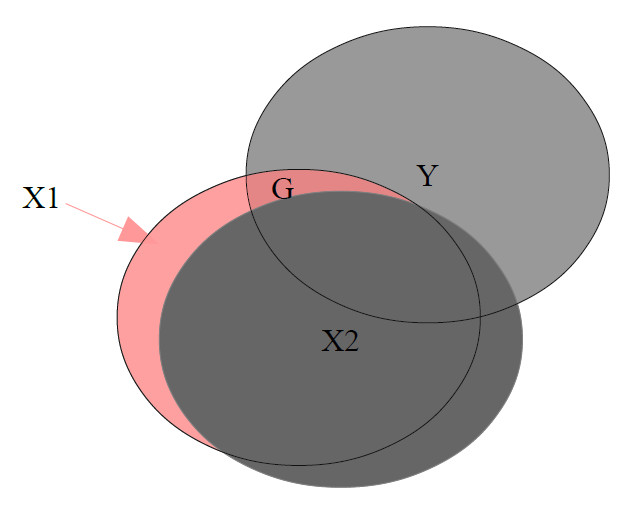
Wenn jetzt Multikollinearität vorliegt, dann wird ein Großteil des Zusammenhangs zwischen dem Prädiktor X1 und dem Kriterium Y gar nicht für die Schätzung des Regressionsgewichts berücksichtigt, weil es durch die Überlappung mit dem anderen Prädiktor auspartialisiert wird. Das sehen wir im folgenden Beispiel. Der für die Berechnung verwendete Teil (farbig) gibt nur einen geringen Teil des Zusammenhangs zwischen X1 und Y wieder. Entsprechend instabil und wenig repräsentativ ist die resultierende Parameterschätzung:
<
3. Was sind die Konsequenzen von starker Multikollinearität?
Starke Multikollinearität führt zu höheren Standardfehlern für die einzelnen Prädiktoren und damit dazu, dass es schwieriger wird, einen signifikanten Effekt zu finden. Und sie führt zu wenig zuverlässigen Parameterschätzungen. Im Extremfall kann es sogar zu numerischen Problemen kommen, bei denen die Parameterschätzung nicht richtig funktioniert.
Es kann also zu einer Situation kommen, in der das Gesamtmodell der Regression (und der dazu gehörige F-Test) hoch signifikant ist, weil die Prädiktoren zusammen das Kriterium gut erklären, und gleichzeitig kein einziger Prädiktor für sich (mit t-Test geprüft) signifikant wird, weil es dort zu den Schätzproblemen durch Multikollinearität kommt.
4. Was sind mögliche Ursachen für Multikollinearität?
Zu problematischer Multikollinearität kann es aus verschiedenen Gründen kommen:
- Es werden mehrere Prädiktoren eingeschlossen, von denen mindestens zwei im Grunde inhaltlich das Gleiche messen (siehe das Beispiel aus der Glücksforschung von oben).
- Fehler bei der Modellspezifikation bei einem kategorialen Prädiktor mit k Stufen, wenn dort der Einschluss von k Dummyvariablen (statt korrekterweise k-1) erfolgt.
- Einschluss eines Prädiktor, der lediglich die Kombination zweier anderer im Modell enthaltener Prädiktoren ist (z.B. Arbeitszeit, Freizeit, Gesamtzeit[=Arbeitszeit + Freizeit])
- Moderierte Regression: Hier wird neben den einzelnen Prädiktoren auch ein Produktterm mit eingeschlossen.
- Polynomiale Regression: Hier wird neben X auch X2 usw. mit eingeschlossen.
5. Wie diagnostiziert man Multikollinearität?
Für die Diagnose gibt es zwei – inhaltlich äquivalente – Kennzahlen, die Toleranz und den Varianz-Inflationsfaktor (VIF). Dabei ist die Toleranz genau der Kehrwert des VIF, so dass die Betrachtung einer der beiden Kennzahlen inhaltlich völlig ausreicht (und der vereinzelt in Journal-Artikeln zu findende Bericht beider Kennzahlen nebeneinander m.E. wenig sinnvoll ist).
Für die Interpretation dieser Kennzahlen sind folgende Infos wichtig:
- VIF und Toleranz liegen bei 1.00, wenn keine Multikollinearität vorliegt.
- VIF wird größer bei zunehmender Multikollinearität.
- Toleranz wird kleiner bei zunehmender Multikollinearität (weil es der Kehrwert vom VIF ist)
- Als Faustregel für eine problematische Multikollinearität wird häufig ein VIF > 10.00 bzw. eine Toleranz < .10 angesehen. Es gibt in der Literatur aber auch abweichende Schwellenwerte (z.B. Toleranz < .20 oder .25).
Die Verwendung pauschaler Schwellenwerte wird in der Literatur aber auch kritisiert (O’Brien, 2007), so dass bei einem VIF > 10.00 ggf. unter Berufung auf derartige Quellen eine Regression dennoch durchgeführt bzw. interpretiert werden könnte.
6. Aufruf in SPSS
Beim Aufruf der Regression über das Menü setzen Sie im Regressions-Unterfenster „Statistiken“ einfach einen Haken bei „Kollinearitätsdiagnose“.
Beim Aufruf über die SPSS-Syntax fügen sie lediglich die im Folgenden fett gedruckten Elemente ein (hier ein Beispiel mit den zwei Prädiktoren x1 und x2 und dem Kriterium y):
REGRESSION
/MISSING LISTWISE
/STATISTICS COEFF OUTS R ANOVA COLLIN TOL
/CRITERIA=PIN(.05) POUT(.10)
/NOORIGIN
/DEPENDENT y
/METHOD=ENTER x1 x2.
Sie bekommen dann in der Tabelle der Regressionskoeffizienten zwei zusätzliche Spalten mit den Werten für Toleranz und VIF.
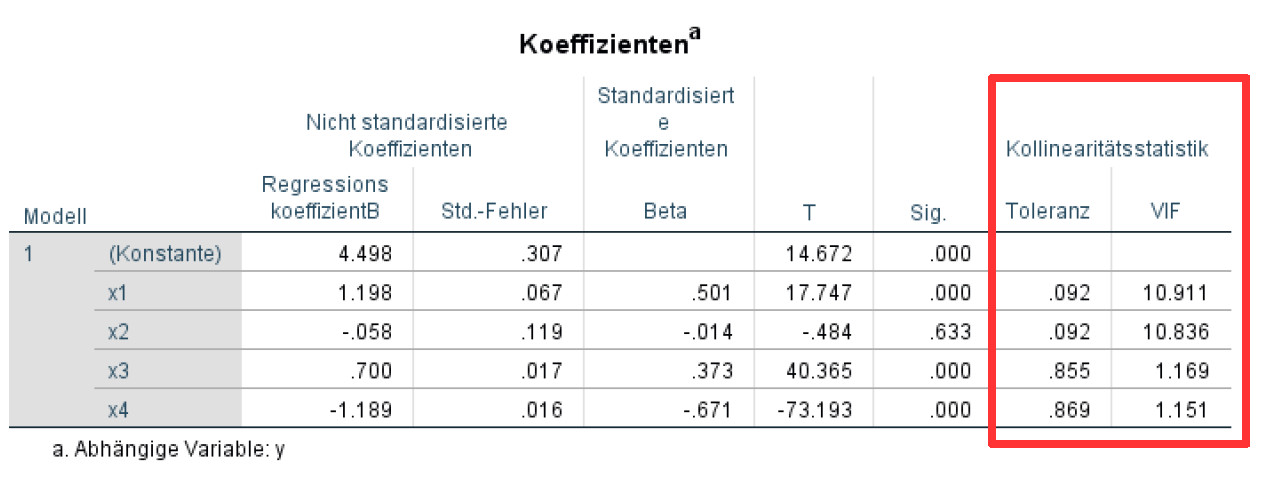
Zusätzlich bekommen Sie eine Tabelle „Kollinearitätsdiagnose“. Die ist vor allem dann hilfreich, wenn mehr als zwei Prädiktoren jeweils einen VIF von größer als 10 aufweisen. Dann kann man dort nämlich näher analysieren, wo genau die Multikollinearitätsprobleme vorliegen. So ist es z.B. bei vier Prädiktoren mit zu hohen VIFs möglich, dass es ein gemeinsames Problem mit allen vier Prädiktoren gibt, oder dass es zwei getrennte Probleme mit je zwei Prädiktoren gibt. Wie Sie diese Tabelle interpretieren, können Sie hier nachlesen: SPSS-Tabelle "Kollinearitätsdiagnose" bei Regression interpretieren
7. Aufruf in R
Die Basis für die folgende Ausreißerdiagnostik ist jeweils ein geschätztes Regressionsmodell, also z.B. als Ergebnis so eines Aufrufs:
reg.fit <- lm(AV ~ UV1 + UV2 + UV3, data=mein.datensatz)
Für die Diagnose wird jeweils das R-Package olsrr verwendet. Dieses muss wie jedes Package einmalig installiert werden (install.packages) und dann jeweils mit library geladen werden.
VIF und Toleranz
library(olsrr)
ols_vif_tol(reg.fit)
8. Was kann man tun, wenn starke Multikollinearität vorliegt?
Es gibt verschiedene Optionen, mit denen man Multikollinearitätsprobleme beheben kann:
- Einsatz linearer Strukturgleichungsmodelle (SEM)
- Zusammenfassung von Prädiktoren zu einer Skala (Basis dafür ist i.d.R. eine exploratorische Faktorenanalyse)
- Durchführung einer PCA und Verwendung deren Ergebnisse als Prädiktoren
- Wenn es Fehler bei der Modellspezifizierung sind (wegen so vieler Dummyvariablen wie Stufen der kategorialen Variable oder wegen Einschlusses einer Variable, die nur die Kombination anderer Variablen ist): Korrektur der Modellspezifikation.
- Wenn die Multikollinearität an den Besonderheiten des Modells liegt (Moderatorprüfung oder polynomiale Regression): Ggf. Ridge-Regression oder verwandte Verfahren, wobei deren Eignung für Hypothesentests strittig ist und es teilweise primär als exploratorisches Verfahren gesehen wird.
Gerade bei Multikollinearität im Zusammenhang mit dem Hypothesentest bei einer Moderation oder einer polynomialen Regression gibt es allerdings aus meiner Sicht häufig keine wirklich gute Lösung für das Problem. Es bleibt dann, die mit der Multikollinearität verbundene Ungenauigkeit hinzunehmen und als Einschränkung der eigenen Ergebnisse im Diskussionsteil der Arbeit zu diskutieren. Bzw. auf den Artikel von O’Brien (2007) zu verweisen.
Die mitunter bei einer Moderation für Multikollinearität diskutierte Lösung, den Moderator zu zentrieren, funktioniert als Mittel gegen Multikollinearität leider nicht, auch wenn man sie noch in älteren Beiträgen als Vorschlag findet. Zwar verschwinden mit der Zentrierung häufig die zu hohen VIFs. Aber das Schätzproblem ändert sich dadurch leider nicht. Wenn Sie das einmal selbst ausprobieren, werden Sie feststellen, dass mit der Zentrierung des Moderators (oder auch von Prädiktor und Moderator) sowohl das Regressionsgewicht für den Interaktionsterm als auch dessen Standardfehler, Teststatistik und p-Wert sich nicht verändern. (Eine Zentrierung eines metrischen Moderators ist aber durchaus sinnvoll, allerdings aus anderen Gründen: Sie erleichtert die Interpretation der Regressionsgewichte bei Vorliegen einer Interaktion.)
9. Quellen
Baltes-Götz, B. (2018). Mediator-und Moderatoranalysemit SPSS und PROCESS [Lecture Notes]. Universität Trier. https://www.uni-trier.de/fileadmin/urt/doku/medmodreg/medmodreg.pdf
Baltes-Götz, B. (2019). Lineare Regressionsanalyse mit SPSS [Lecture Notes]. Universität Trier. https://www.uni-trier.de/fileadmin/urt/doku/linreg/linreg.pdf
Deviant, S. (2015). Multicollinearity: Definition, causes, examples . Statistics How To. https://www.statisticshowto.datasciencecentral.com/multicollinearity/
Eid, M., Gollwitzer, M., & Schmitt, M. (2013). Statistik und Forschungsmethoden. Beltz.
Field, A. (2013). Discovering statistics using IBM SPSS statistics: And sex and drugs and rock 'n' roll (4th edition). SAGE.
Hebbali, A. (2020). Package 'olsrr'. CRAN. https://cran.r-project.org/web/packages/olsrr/olsrr.pdf
O’Brien, R. M. (2007). A caution regarding rules of thumb for variance inflation factors. Quality & Quantity, 41, 673-690. 10.1007/s11135-006-9018-6
Price, B. (1977). Ridge regression: Application to nonexperimental data. Psychological Bulletin, 84, 759.
Weitere Tutorials zu Regressionsvoraussetzungen:
- Normalverteilung
- Homoskedastizität
- Linearität
- Unkorreliertheit der Fehler bzw. Residuen
- Geeignete Skaleneigenschaften
- Keine starken Ausreißer