Voraussetzungen Regression: Unkorreliertheit der Fehler bzw. Residuen
Arndt Regorz, Dipl. Kfm. & M.Sc. Psychologie, Stand: 17.08.2020
Eine der Voraussetzungen für den statistischen Test eines Regressionsmodells ist die Unkorreliertheit der Fehler (oder der Residuen), manchmal auch als Unabhängigkeit der Fehler beschrieben. Dieses Tutorial erklärt Ihnen, was das bedeutet, wie Sie das testen können und welche Alternativen Sie bei einer Verletzung der Voraussetzung haben.
Inhalt
- Bedeutung der unkorrelierten Fehler
- Prüfung auf Korrelation der Fehler
- Alternativen bei korrelierten Fehlern
- Quellen
1. Bedeutung der unkorrelierten Fehler
Ein Regressionsmodell kann in der Praxis nie alle Beobachtungen perfekt vorhersagen. Das hat zur Konsequenz, dass einen Unterschied gibt zwischen den vorhergesagten Werten und den tatsächlichen Werten. In der folgenden Grafik liegen die vorhergesagten Werte auf der roten Regressionsgrade, sie unterscheiden sich von den tatsächlich realisierten Werten (Punkte in der Grafik). Im theoretischen Modell spricht man dabei von Fehlern, in der tatsächlichen Stichproben von Residuen (Residuen sind also Schätzwerte für die unbekannten tatsächlichen Fehler - dann wir haben für die vorhergesagten Werte ja nur eine Schätzung aufgrund einer Stichprobe).
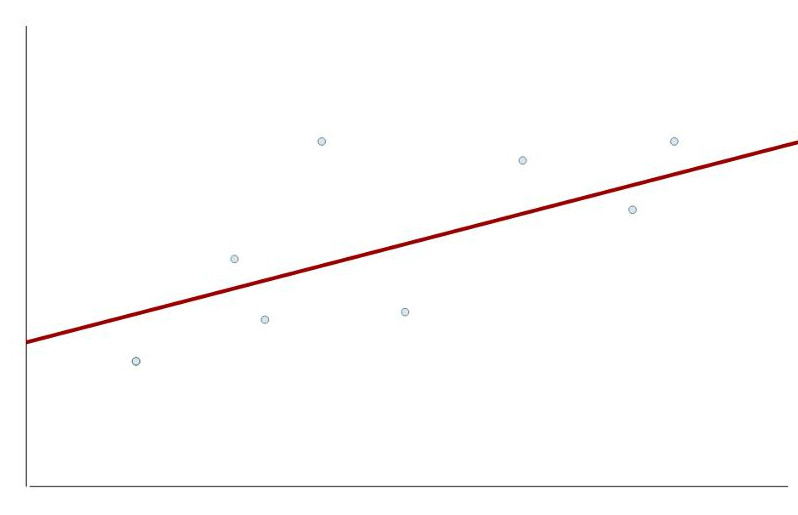
Die Regressionsvoraussetzung ist jetzt, dass die Fehler für verschiedene Beobachtungen nicht miteinander korrelieren (positiv oder negativ). Mit anderen Worten: Wenn man den Fehler für eine konkrete Beobachtungen kennt, dann darf man daraus keine Rückschlüsse ziehen können auf den Fehler für eine andere Beobachtung.
Auf dieser Voraussetzung basieren die Hypothesentests (z.B. die Tests für ein einzelnes Regressionsgewicht); wenn die Voraussetzung verletzt ist, können Sie falsche Ergebnisse in Ihren Tests herausbekommen.
In welchen Situationen kann es nun zu einer Verletzung der Voraussetzung kommen? Hier sind vor allem zwei Fälle praxisrelevant:
Problem 1: Hierarchische Datenstrukturen
In hierarchischen Datenstrukturen (Mehrebenenstrukturen, geclusterte Daten, etc.) haben Sie Daten auf mehreren Hierarchieebenen. Ein einfaches Beispiel wäre die Untersuchung in einer Schule:
- Die erste Ebene sind die Schülerinnen und Schüler.
- Die zweite Ebene sind die Schulklassen.
Alle Schülerinnen und Schüler in einer Klasse haben gewisse Gemeinsamkeiten (gleiche Lehrer, gleiche soziale Dynamik in der Klasse). Das kann dazu führen, dass die Fehler in der Regression miteinander korrelieren. Wenn z.B. aufgrund einer sehr guten Lehrerin alles Schülerinnen und Schüler bessere Leistungen erbringen, als mit dem Modell vorhergesagt (z.B. vorhergesagt durch IQ, sozio-ökonomischem Status, usw.), dann würden die Fehler positiv miteinander korrelieren. Und das führt dazu, dass die Hypothesentests ohne Berücksichtigung dieser Mehrebenenstruktur zu falschen Ergebnissen führen können.
Andere Beispiele für derartige Datenstrukturen wären:
- Mitarbeiter (Ebene 1) aus verschiedenen Unternehmen (Ebene 2)
- Unternehmen (Ebene 1) aus verschiedenen Branchen oder aus verschiedenen Ländern (Ebene 2)
- Geschwister (Ebene 1) aus verschiedenen Familien (Ebene 2)
Neben den o.g. Beispielen mit nur zwei Ebenen sind auch Stichprobenstrukturen mit mehr als zwei Ebenen denkbar, z.B.: Schüler (Ebene 1), Klassen (Ebene 2), Schulen (Ebene 3).
Problem 2: Zeitreihenanalysen
Der zweite häufige Grund für eine Verletzung dieser Voraussetzung sind Zeitreihenanalysen, insbesondere im Bereich der Ökonometrie. Hier besteht häufiger eine Abhängigkeit einer Beobachung von der vorherigen (Autokorrelation).
Damit ist ausdrücklich nicht eine gewöhnliche Längsschnittuntersuchung mit zwei oder drei Messzeitpunkten gemeint, sondern eher ein Modell, in dem Wirtschafts- und Finanzdaten für viele Monate oder Jahre analysiert werden.
2. Prüfung dieser Regressionsvoraussetzung
Die einfachste und gleichzeitig m.E. in der Regel (außer bei Zeitreihen) sinnvollste Prüfung ist die Betrachtung der Stichprobenziehung:
- Besteht eine hierarchische Datenstruktur?
- Wird eine Zeitreihe ausgewertet?
Wenn man beide Fragen mit "nein" beantworten kann, sollte im Regelfall die Voraussetzung erfüllt sein.
Insbesondere für Zeitreihendaten gibt es jedoch auch formale Tests auf Autokorrelation. Der bekannteste dafür ist der Durbin-Watson-Test auf Autokorrelation ersten Grades. Dieser Test prüft, ob der Fehler für einen Wert mit dem Fehler seines Vorgängers zusammenhängt. Und daher macht der Test eigentlich auch nur für geordnete Daten (wie Zeitreihen) Sinn, weil nur dort ein sinnvoller "Vorgänger" bestimmbar ist. Technisch kann man diesen Test jedoch auch für Querschnittsuntersuchungen einsetzen, allerdings mit dem Nachteil, dass sich je nach Sortierung der eigenen Daten das Testergebnis ändern kann. Aber eigentlich ist er für diesen Fall nicht gemacht.
Im SPSS-Regressionsdialog lässt sich der Durbin-Watson-Test leicht aufrufen in der Dialogbox "Statistiken":
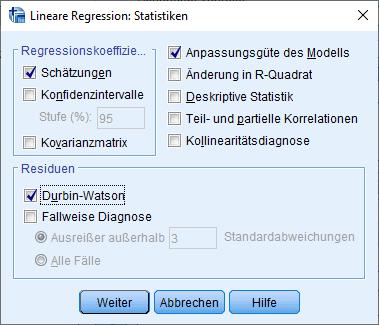
Das Ergebnis bekommt man dann als Teil der Tabelle Modellzusammenfassung:

Der Durbin-Watson-Test kann Werte zwischen 0 und 4 annehmen. Bei perfekt unkorrelierten Residuen nimmt er einen Wert von 2 an, größere Abweichungen von diesem Wert können auf Autokorrelation hindeuten. Dabei gibt es unterchiedliche Meinungen, wann Abweichungen zu groß sind. Werte zwischen 1.5 und 2.5 sollten aber unproblematisch sein.
Fazit: Bei einer normalen Querschnittsuntersuchung ist der Durbin-Watson-Test nicht sehr aussagefähig und insofern m.E. verzichtbar. Aber er schadet auch nicht, denn wenn er auffällige Werte zeigt, könnte das durchaus ein Grund sein, nochmal genauer in die eigene Stichprobenziehung zu sehen. Nur gilt der Umkehrschluss leider nicht: Ein nicht auffälliger Durbin-Watson-Test ist kein hinreichendes Zeichen für die Erfüllung der Regressionsvoraussetzung unkorrelierter Residuen in einer Querschnittsstudie! Sie sollten immer auch Ihre Stichprobenstruktur prüfen.
3. Alternativen bei korrelierten Fehlern
Die Alternativen bei einer Verletzung der Voraussetzungen sind schnell genannt:
Wenn Sie eine hierarchische Datenstruktur haben, dann können Verfahren der Mehrebenenanalyse (hierarchische lineare Modelle, HLM) zum Einsatz kommen oder verschiedene Verfahren der Clusteranalyse.
Wenn Sie in einer Zeitreihenanalyse einer Autokorrelation haben, dann gibt es entsprechende Verfahren der Zeitreihenanalyse.
Für beide Alternativen gilt allerdings: Es sind sehr mächtige und komplexe Verfahren, deren Erklärung jeweils ganze Lehrbücher füllt. Die einfachste Alternative ist bei einer Abschlussarbeit, bereits im Vorfeld derartige Datenstrukturen zu vermeiden, wenn man noch Einfluss auf das eigene Thema hat oder zwischen verschiedenen Themenvorschlägen wählen kann.
4. Quellen
Field, A. (2013). Discovering statistics using IBM SPSS statistics: And sex and drugs and rock 'n' roll (4th edition). SAGE.
Gujarati, D. (2009). Basic Econometrics (4th edition). Tata McGraw-Hill.
Weitere Tutorials zu Regressionsvoraussetzungen:
- Normalverteilung
- Homoskedastizität
- Linearität
- Keine starke Multikollinearität
- Geeignete Skaleneigenschaften
- Keine starken Ausreißer