Mehrebenenanalyse mit R (HLM mit R)
– Voraussetzungen prüfen
Arndt Regorz, Dipl. Kfm. & MSc. Psychologie, 19.05.2022
In diesem Tutorial werden Sie lernen, wie Sie bei der Mehrebenenanalyse Voraussetzungen prüfen können (Hierarchical Linear Modeling: Assumptions Check). Die Mehrebenenanalyse, auch HLM oder linear mixed effects model genannt, ist im Wesentlichen ein Regressionsmodell, so dass deren Voraussetzungen auch stark denen der multiplen Regression ähneln. Allerdings führt die Mehrebenenstruktur dazu, dass man einige der Voraussetzungen auf verschiedenen Analyseebenen prüfen muss.
INHALT
- Prüfung auf Ebene 1 (Normalverteilung, Homoskedastizität, Ausreißer)
- Prüfung auf Ebene 2 (Normalverteilung, Homoskedastizität, Ausreißer)
- Weitere Voraussetzungen (Linearität, Abwesenheit von Multikollinearität)
- Vollständiger R-Code
- Literatur
Dieses Tutorial zeigt auf Basis eines Beispiels aus Kapitel 2 von Hox et al. (2017), wie Sie Voraussetzungen der Mehrebenenanalyse mit R prüfen können. Die Modellschätzung wird in meinem Basistutorial zur Mehrebenenanalyse mit R erklärt und basiert hier auf dem lme4-Modul. Allerdings ist der gleiche Code auch anwendbar, wenn Sie stattdessen das nlme-Modul für Ihre Mehrebenenanalyse verwenden.
Zunächst laden wir die benötigten Module:
library(lme4) # Eigentliche HLM-Schätzung
library(lmerTest) # p-Werte für HLM-Schätzung
library(HLMdiag) # Residuen der HLM-Schätzung
library(ggplot2) # Grafiken
library(dplyr) # Datenaufbereitung
library(lmtest) # für Rainbow-Test wg. Linearität
library(jtools) # für VIF wg. Multikollinearität
Dann schätzen wir das Modell, in diesem Fall ein Modell mit einer Random Slope, für Extraversion. Näheres zum Beispieldatensatz (inklusive Link zu den Daten, damit Sie selbst die Berechnung nachbauen können, siehe das Basistutorial zum lme4 Package).
# Modellschätzung Random Slope nur Extraversion
random_slopes <- lmer(popular ~ 1 + sex + extrav + texp + (1+extrav|class),
data=popular2, REML=F)
summary(random_slopes)
Die Ergebnisse dieses Modells dürfen wir aber nur interpretieren, wenn die Voraussetzungen für das Verfahren gegeben sind. Das werden wir jetzt in mehreren Schritten prüfen.
1. Prüfung auf Ebene 1 (Normalverteilung, Homoskedastizität, Ausreißer)
Zunächst prüfen wir die Residuen auf Level 1, also auf der untersten Ebene des Modells (im Beispiel die Ebene der Schülerinnen und Schüler). Mit diesem Befehl können wir aus dem gefitteten Objekt (random_slopes) die Residuen herauslesen:
l1_residuen <- hlm_resid(random_slopes, level=1) # Funktion aus HLMdiag-Package
head(l1_residuen)

Die Warnmeldung, die Sie im Beispiel erhalten (hier nicht abgedruckt), wird noch weiter unten erläutert.
Wir sehen im Dataframe der Residuen, dass es dort verschiedene Typen von Residuen gibt. Wir werden hier zwei verwenden. Zum einen verwenden wir die normalen Residuen, die sich als Ergebnis der ML-Schätzung des Mehrebenenmodells ergeben, .resid (den Punkt vor dem Namen des Residuums vergissst man am Anfang leicht, das ist eine häufige Fehlerquelle). Diese haben jedoch den Nachteil, dass sich in ihnen Einflüsse auf Level 1 und Einflüsse auf Level 2 miteinander vermischen können.
Deshalb nutze wir noch eine zweite Art von Residuen, die Least-Squares-Residuen (LS-Residuen), .ls.resid (wiederum: Punkte beachten bei der Schreibweise). Die LS-Residuen entstehen dadurch, dass in jeder Gruppe (also jeder Level 2-Einheit) gesondert eine normale Regression durchgeführt wird und deren Residuen gespeichert werden. Damit ist sichergestellt, dass wirklich nur die Level 1 Einflüsse in die Residuen eingehen. Allerdings setzt der Einsatz der LS-Residuen voraus, dass die einzelnen Gruppen groß genug sind im Verhältnis zur Anzahl der Prädiktoren – bei sehr kleinen Gruppen kann es hier zu Schätzproblem mit den Residuen kommen, daher die Warnmeldung für die LS-Residuen oben beim Abruf der Residuen.
Aufgrund der Warnmeldung habe ich die Analyse der Residuen doppelt ausgeführt, einmal mit den LS-Residuen und einmal mit den normalen Residuen.
Überprüfung der LS-Residuen
Normalverteilung Mehrebenenanalyse
Die Normalverteilung können wir mit einem Histogramm der Residuen prüfen:
ggplot(data = l1_residuen, aes(.ls.resid)) +
geom_histogram(aes(y = ..density..), bins=10) +
stat_function(fun = dnorm,
args = list(mean = mean(l1_residuen$.ls.resid),
sd = sd(l1_residuen$.ls.resid)), size=2)
Das Histogramm sieht hier gut (im Sinne von Normalverteilung) aus:
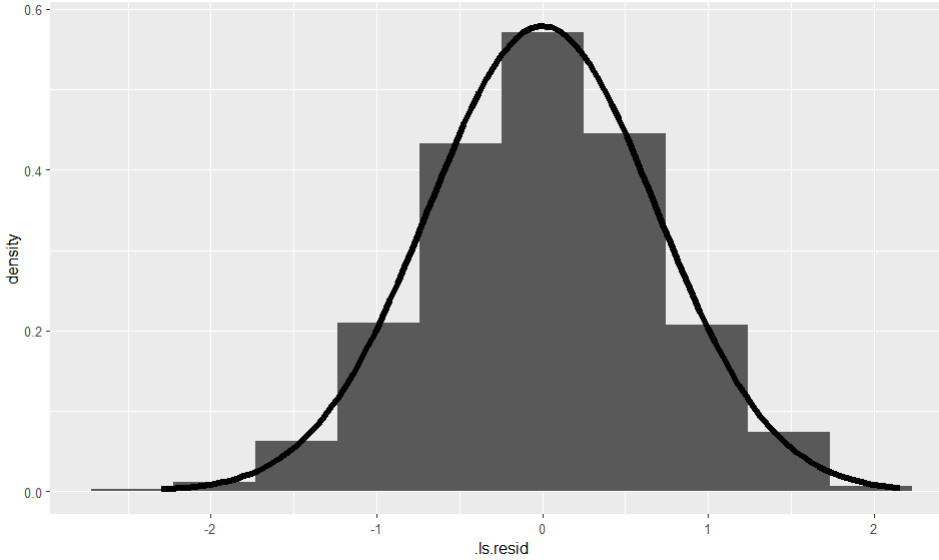
Außerdem wäre prinzipiell der Shapiro-Wilk Test der Residuen möglich, wobei dieser bei sehr großen Stichproben schon bei kleinen Abweichungen von der Normalverteilung signifikant werden kann.
shapiro.test(l1_residuen$.ls.resid)
Hier ist der Test mit p = .462 nicht signifikant trotz sehr großer Stichprobe, die Normalverteilungsannahme ist also erfüllt.
Homoskedastizität Mehrebenenanalyse
Die Homoskedastizität können wir in einem Streudiagramm aus vorhergesagten Werten und Residuen prüfen.
ggplot(data=l1_residuen, aes(x=.ls.fitted, y=.ls.resid)) +
geom_point()
Das Ergebnis:
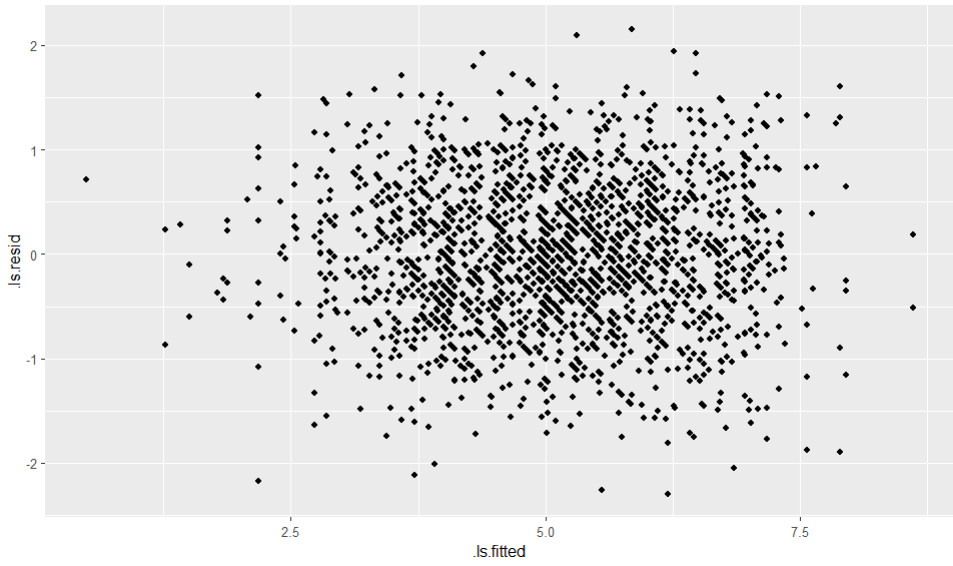
Das Ergebnis ist hier eine unsystematische Punktwolke, was für die Erfüllung der Homoskedastizitätsannahme spricht. Ein sogenannter liegender Trichter wäre ein mögliches Gegenbeispiel, also eine nach rechts oder nach links immer stärker werdende Streuung der Residuen.
Außerdem könnte man noch mit einer ANOVA prüfen, ob sich die Varianz der Absolutwerte der Residuen zwischen den verschiedenen Level 2 Einheiten signifikant unterscheidet.
res_vergleich <- transmute(l1_residuen, res_abs = abs(.ls.resid), class)
attach(res_vergleich)
summary(aov(res_abs ~ as.factor(class)))
detach(res_vergleich)
Das Ergebnis wäre im Beispieldatensatz hochsignifikant (p < .001), würde also gegen die Annahme der Varianzgleichheit in den Gruppen sprechen. Allerdings nehme ich bei einer so großen Stichprobe dieses Ergebnis nicht so ernst, denn bei N = 2000 ist das schon rein per Zufallsschwankung fast zu erwarten.
Ausreißer Mehrebenenanalyse
Hier betrachte ich zunächst einen Boxplot der Residuen.
ggplot(data = l1_residuen, aes(y= .ls.resid)) + theme_gray() + geom_boxplot()
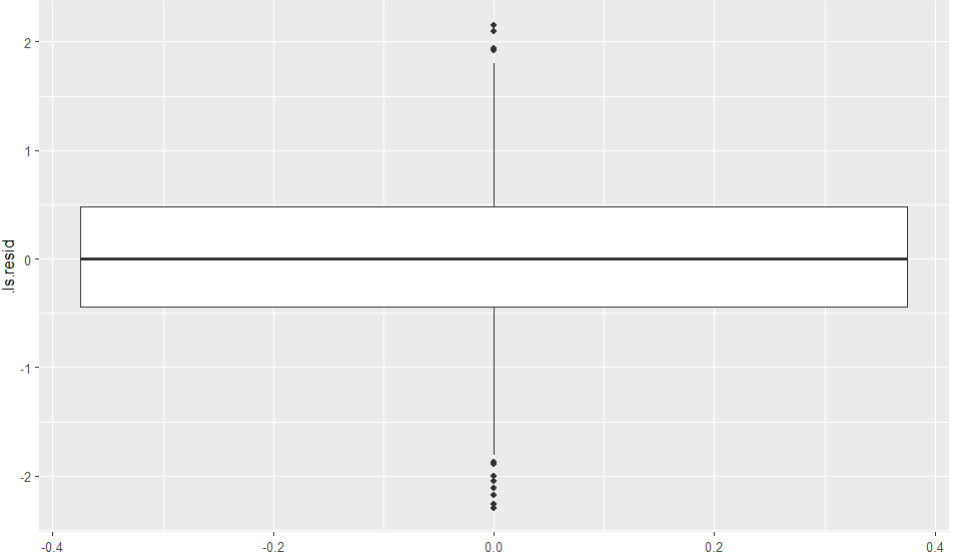
Es gibt einige Ausreißer, aber bei N = 2000 ist das auch zu erwarten.
Zudem kann man noch Boxplots je Gruppe betrachten:
ggplot(data = l1_residuen, aes( x= .ls.resid, y= as.factor(class))) + theme_gray() + geom_boxplot()
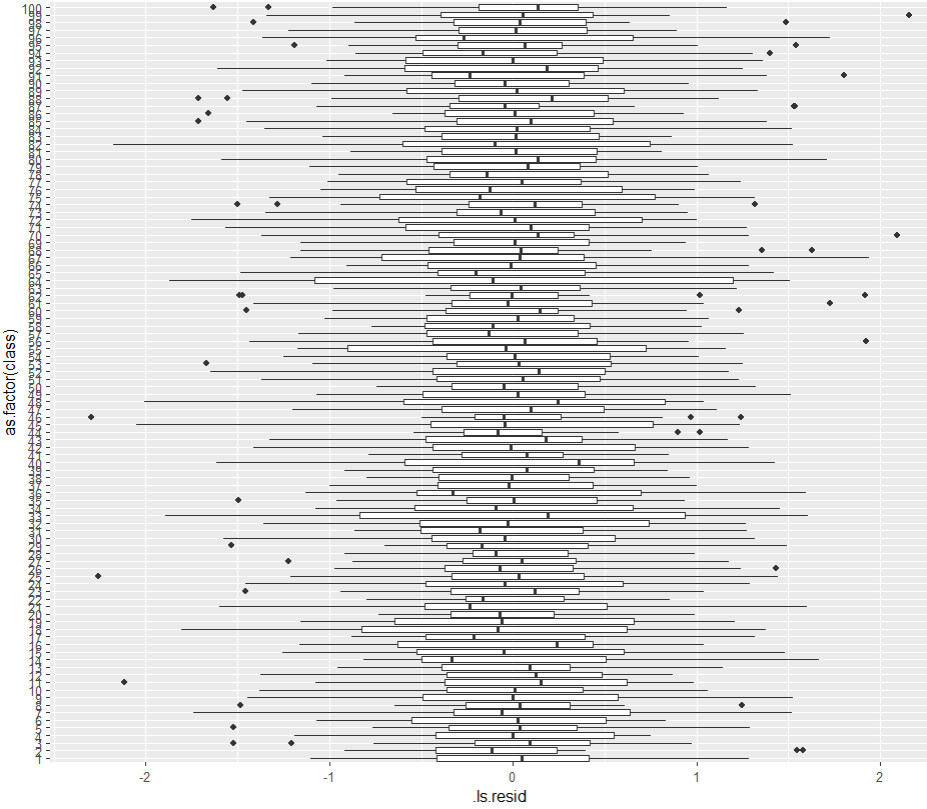
Aus meiner Sicht keine großen Auffälligkeiten, die Ausreißer verteilen sich relativ gleichmäßig über die Gruppen und es sind für mich auch keine extremen Unterschiede in der Schwankungsbreite zwischen den Gruppen erkennbar (siehe Homoskedastizität).
Überprüfung der gewöhnlichen Residuen
Hier ist der gleiche Code für die Überprüfung der gewöhnlichen Residuen (also nicht getrennt pro Gruppe ermittelt, sondern als Ergebnis der Schätzung für die Mehrebenenanalyse), wobei ich auf den erneuten Aufruf der ANOVA für die Varianzgleichheit zwischen den Gruppen verzichtet habe:
# NV
ggplot(data = l1_residuen, aes(.resid)) +
geom_histogram(aes(y = ..density..), bins=10) +
stat_function(fun = dnorm,
args = list(mean = mean(l1_residuen$.resid),
sd = sd(l1_residuen$.resid)), size=2)
shapiro.test(l1_residuen$.resid)
# Homoskedastizität
ggplot(data=l1_residuen, aes(x=.fitted, y=.resid)) +
geom_point()
# Ausreißer
ggplot(data = l1_residuen, aes(y= .resid)) + theme_gray() + geom_boxplot()
ggplot(data = l1_residuen, aes(x= .resid, y= as.factor(class))) + theme_gray() + geom_boxplot()
Auf den Abdruck der Ergebnisse verzichte ich hier, Grafiken und Test führen in diesem Beispiel im Wesentlichen zu den gleichen Schlussfolgerungen wie vorher bei den LS-Residuen.
2. Prüfung auf Ebene 2 (Normalverteilung, Homoskedastizität, Ausreißer)
Neben den Residuen auf Level 2 haben wir bei der Mehrebenenanalyse auch Zufallsterme auf Level 2, in unserem Beispiel ein Random Intercept und eine Random Slope. Auch für diese müssen die Regressionsvoraussetzungen geprüft werden.
Zunächst rufen wir die Level 2 Residuen ab (wobei ich auf den Abruf von LS-Residuen hier verzichte, da diese auf Level 2 weniger geeignet sind).
l2_residuen <- hlm_resid(random_slopes, level="class",
include.ls = FALSE) # Funktion aus HLMdiag-Package
head(l2_residuen)

Zunächst prüfen wir das Random Intercept, anschließend die Random Slope (bzw. ggf. auch mehrere Random Slopes, wenn Sie in Ihren Daten mehr als eine Slope mit Zufallseffekten geschätzt haben). Wir prüfen auf Normalverteilung, Homoskedastizität und auf Ausreißer.
Normalverteilung Random Intercept
Der Aufruf ist ähnlich wie bei Level 1, nur dass wir jetzt die Random Effects für das Intercept analysieren, .ranef.intercept:
ggplot(data = l2_residuen, aes(.ranef.intercept)) +
geom_histogram(aes(y = ..density..), bins=10) + stat_function(fun = dnorm,
args = list(mean = mean(l2_residuen$.ranef.intercept),
sd = sd(l2_residuen$.ranef.intercept)), size=2)
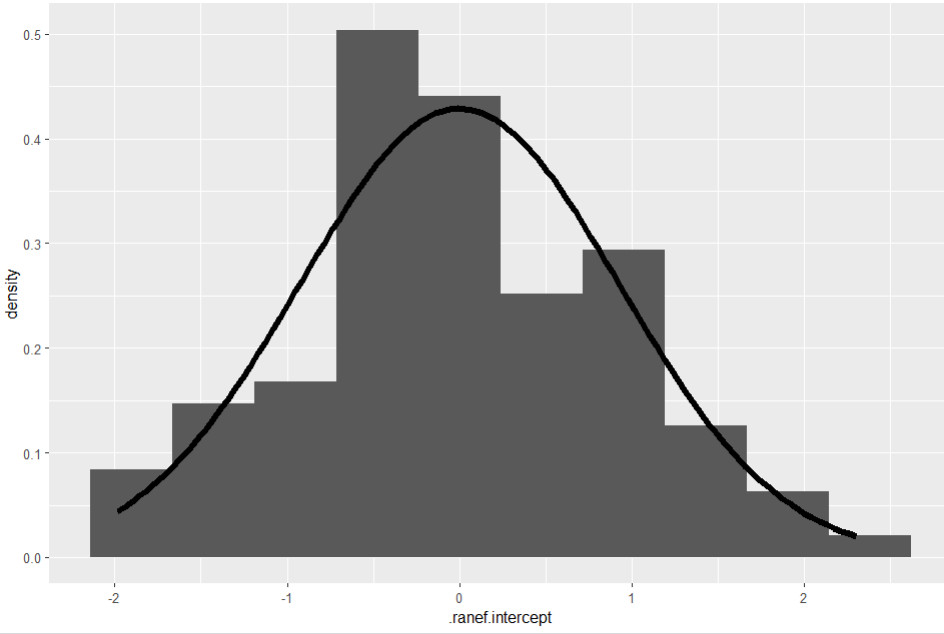
Das Bild sieht nicht mehr ganz so schön symmetrisch auf wie bei den Level 1 Residuen, wobei hier auch die Stichprobengröße (= Anzahl der Level 2 Einheiten, 100) kleiner ist als auf Level 1 (N=2000). Allerdings ist bei der Prüfung der Normalverteilung nicht so wichtig, was sich im Zentrum der Verteilung abspielt. Relevant sind vorwiegend die Ränder der Verteilung, ein Problem würde sich hier in sog. fat tails zeigen, also in Residuen an den Rändern der Verteilung, die deutlich mehr sind als bei Normalverteilung zu erwarten. Das ist hier nicht der Fall.
Zusätzlich können wir noch den Shapiro-Wilk-Test durchführen:
shapiro.test(l2_residuen$.ranef.intercept)
Ein Ergebnis von p = .445 deutet auf keine Verletzung der Normalverteilung hin.
Homoskedastizität Random Intercept
Zunächst berechnen wir auf Basis der Parameterschätzung für Intercept und Level 2 Prädiktor(en) vorhergesagte Level 2 Werte (hier im Code müssen Sie jeweils die Schätzergebnisse für Ihr Modell eintragen):
l2_residuen <- mutate(l2_residuen, pred = 0.7377 + 0.09087 * texp)
Anschließend betrachten wir ein Streudiagramm der vorhergesagten Level 2 Werte und der Random Intercepts:
ggplot(data=l2_residuen, aes(x=pred, y=.ranef.intercept)) +
geom_point()
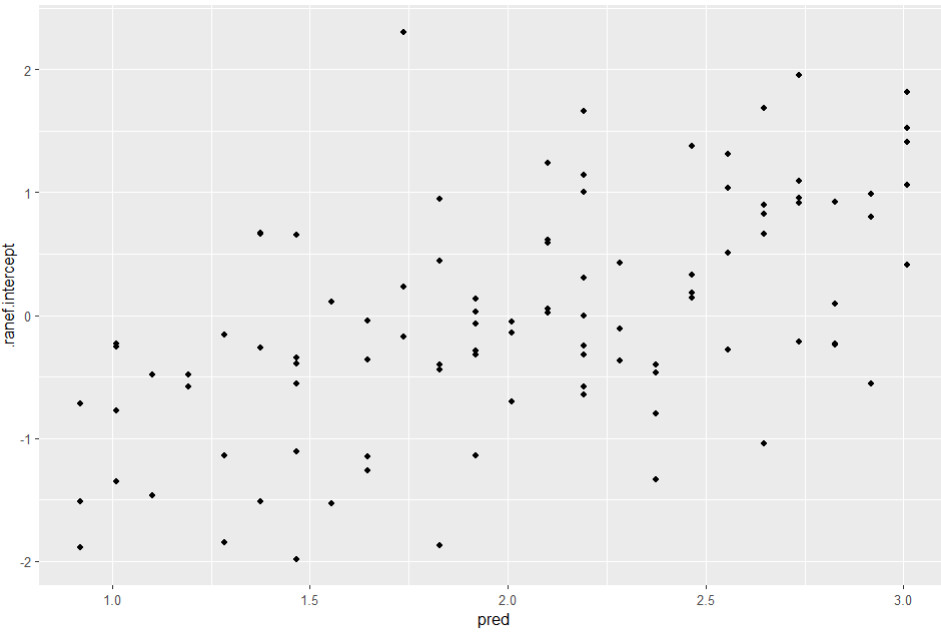
Hier erscheint die Streuung der Level 2 Residuen (= Random Intercepts) für alle vorhergesagten Intercepts vergleichbar zu sein, also kein Anzeichen auf Heteroskedastizität.
Allerdings sehen wir einen deutlichen Trend in den Residuen. Das kann darauf hindeuten, dass das Modell nicht korrekt spezifiziert ist. In diesem Fall ist es vermutlich eine fehlende Cross-Level-Interaktion (Berufserfahrung x Extraversion). Nach deren Aufnahme würde bei den Beispieldaten der Trend in den Residuen verschwinden (hier nicht abgedruckt).
Ausreißer Random Intercept
Auf Ausreißer untersuchen wir die Random Intercepts mit einem Boxplot:
ggplot(data = l2_residuen, aes(y= .ranef.intercept)) + theme_gray() + geom_boxplot()
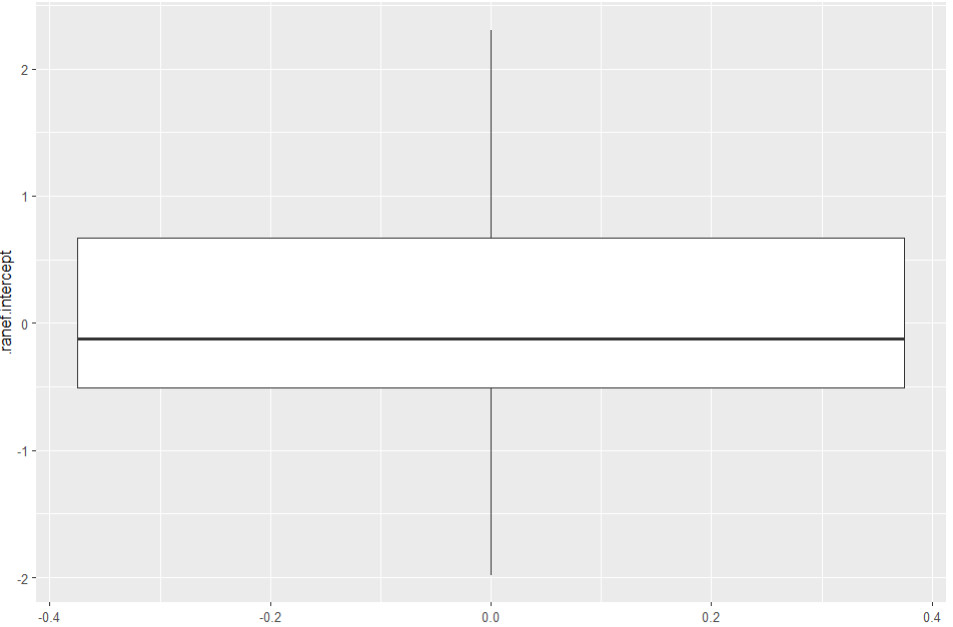
Wir sehen keinen einzigen Ausreißer.
Die gleichen Auswertungen rufen wir auch auf für die Random Slope:
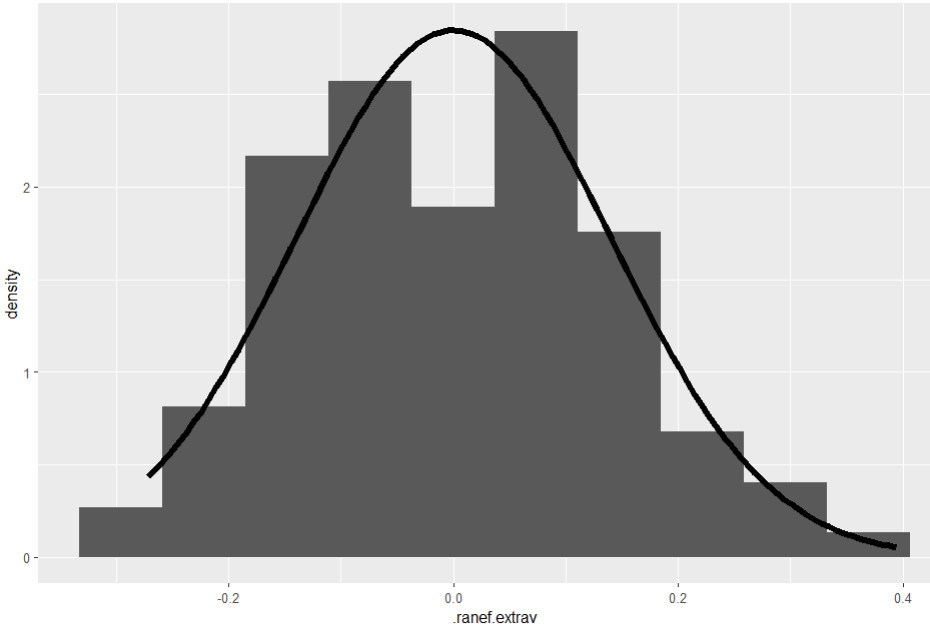
Normalverteilung Random Slope
ggplot(data = l2_residuen, aes(.ranef.extrav)) +
geom_histogram(aes(y = ..density..), bins=10)
+ stat_function(fun = dnorm,
args = list(mean = mean(l2_residuen$.ranef.extrav),
sd = sd(l2_residuen$.ranef.extrav)), size=2)
shapiro.test(l2_residuen$.ranef.extrav)
Wieder deuten die Ergebnisse eher auf eine Erfüllung der Normalverteilung hin:
Homoskedastizität Random Slope
# Streudiagramm vorhergesagte Werte und Random Slope
ggplot(data=l2_residuen, aes(x=pred, y=.ranef.extrav)) +
geom_point()
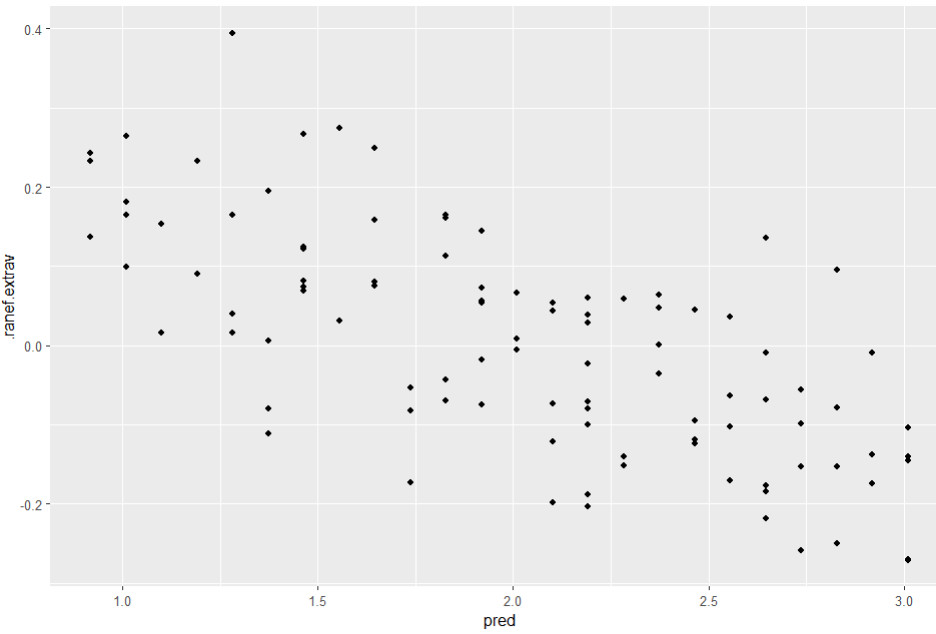
Hier sehen wir keine Anzeichen für Heteroskedastizität (aber wiederum Anzeichen auf ein nicht korrekt spezifiziertes Modell).
Ausreißer Random Slope
Hier rufen wir wieder einen Boxplot auf:
ggplot(data = l2_residuen, aes(y= .ranef.extrav)) +
theme_gray() + geom_boxplot()
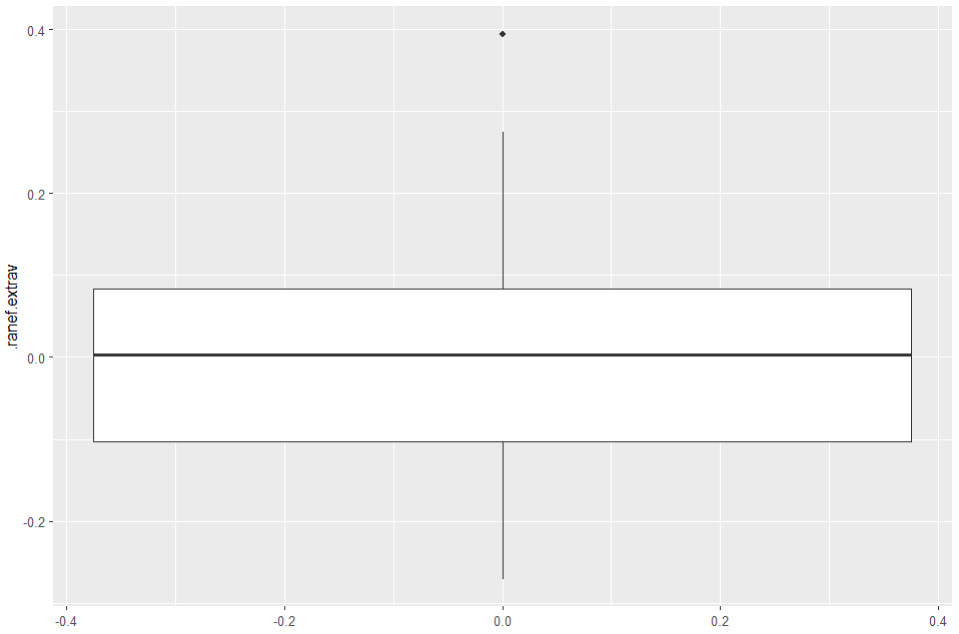
Hier sehen wir einen Ausreißer. Eine Gruppe hat also eine Random Slope, die massiv von den anderen abweicht (hier knapp 0.4). Gruppen, die bei den Random Effects dahingehend auffällig sind, würde ich später genauer analysieren. Die Gruppennummer könnten wir hier einfach so abrufen:
filter(l2_residuen, .ranef.extrav > 0.3) # aus dplyr-Package

Es handelt sich um die Klasse 31; diese könnte man sich im Anschluss noch genauer ansehen.
3. Weitere Voraussetzungen (Linearität, Abwesenheit von Multikollinearität)
Weitere typische Regressionsvoraussetzungen sind Linearität und die Abwesenheit starker Multikollinearität.
Linearität
Die Linearität können wir mit Streudiagrammen prüfen (jeweils einer der kontinuierlichen Prädiktoren und die Kriteriumsvariable.
ggplot(data=popular2, aes(x=extrav, y=popular)) +
geom_point() + geom_smooth()
ggplot(data=popular2, aes(x=texp, y=popular)) +
geom_point() + geom_smooth()
Für Extraversion zeigt sich ein (fast) linearer Zusammenhang:
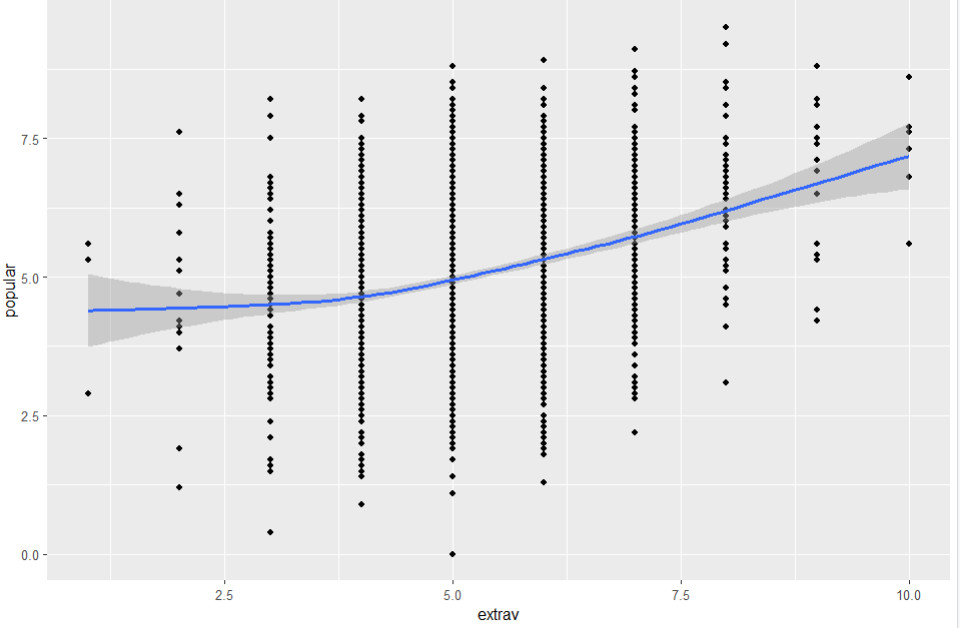
Für Berufserfahrung der Lehrkraft zeigt sich eine Schlangenlinie, die nicht auf einen systematisch nicht-linearen Zusammenhang hindeutet:
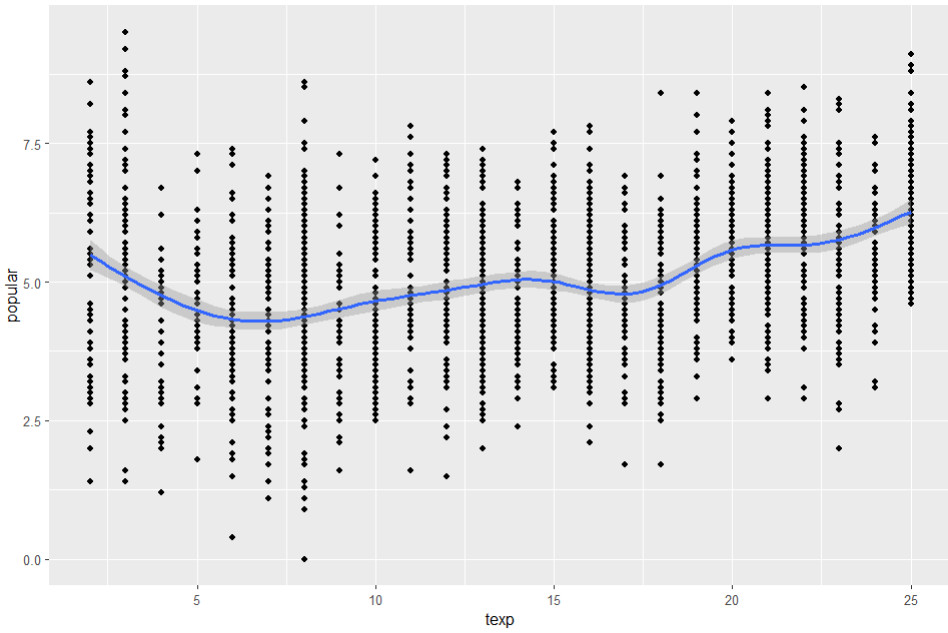
Zusätzlich könnte man noch über den Rainbow-Test einen Hypothesentest auf Linearität durchführen (mit den üblichen Einschränkungen: Hypothesentests auf Verletzung von Voraussetzungen können in großen Stichproben bereits bei sehr geringfügigen Verletzungen signifikant werden):
attach(popular2)
raintest(popular ~ sex + extrav + texp) # aus lmtest-Package
detach(popular2)
Der p-Wert von .657 zeigt keine Abweichung von der Linearität an.
Multikollinearität
Die Abwesenheit starker Multikollinearität können wir über die VIF (Varianzinflationsfaktoren) prüfen, die man anfordern kann, wenn man mit den Prädiktoren eine gewöhnliche multiple Regression durchführt.
ols_reg <- lm(popular ~ sex + extrav + texp, data = popular2 )
summ(ols_reg, vifs=TRUE, digits=3) # aus jtools-Package
VIFs über 10 werden als problematisch angesehen; hier die Werte von 1.022 bis 1.195 sind völlig unproblematisch.
4. Vollständiger R-Code
library(lme4) # Eigentliche HLM-Schätzung
library(lmerTest) # p-Werte für HLM-Schätzung
library(HLMdiag) # Residuen der HLM-Schätzung
library(ggplot2) # Grafiken
library(dplyr) # Datenaufbereitung
library(lmtest) # für Rainbow-Test wg. Linearität
library(jtools) # für VIF wg. Multikollinearität
head(popular2, 5)
# Modellschätzung Random Slope nur Extraversion
random_slopes <- lmer(popular ~ 1 + sex + extrav + texp
+ (1+extrav|class), data=popular2, REML=F)
summary(random_slopes)
# A. Level 1 Residuen
l1_residuen <- hlm_resid(random_slopes, level=1)
# Funktion aus HLMdiag-Package
head(l1_residuen)
# Variante 1: LS-Residuen
# Vorteil: unverzerrt durch Level 2
# Voraussetzung: ausreichend große Gruppen/Cluster
# NV
ggplot(data = l1_residuen, aes(.ls.resid)) +
geom_histogram(aes(y = ..density..), bins=10) +
stat_function(fun = dnorm,
args = list(mean = mean(l1_residuen$.ls.resid),
sd = sd(l1_residuen$.ls.resid)), size=2)
shapiro.test(l1_residuen$.ls.resid)
# Homoskedastizität
ggplot(data=l1_residuen, aes(x=.ls.fitted, y=.ls.resid)) +
geom_point()
# Gleichheit der Residuen in den verschiedenen Level 2 Einheiten
# ANOVA der absoluten Residuen
res_vergleich <- transmute(l1_residuen, res_abs = abs(.ls.resid), class)
attach(res_vergleich)
summary(aov(res_abs ~ as.factor(class)))
detach(res_vergleich)
# Ausreißer
ggplot(data = l1_residuen, aes(y= .ls.resid)) + theme_gray()
+ geom_boxplot()
ggplot(data = l1_residuen, aes( x= .ls.resid, y= as.factor(class))) +
theme_gray() + geom_boxplot()
# Variante 2: ML-Residuen
# Nachteil: verzerrt durch Level 2
# Vorteil: funktioniert auch bei kleinen Gruppen/Clustern
# NV
ggplot(data = l1_residuen, aes(.resid)) +
geom_histogram(aes(y = ..density..), bins=10) +
stat_function(fun = dnorm,
args = list(mean = mean(l1_residuen$.resid),
sd = sd(l1_residuen$.resid)), size=2)
shapiro.test(l1_residuen$.resid)
# Homoskedastizität
ggplot(data=l1_residuen, aes(x=.fitted, y=.resid)) +
geom_point()
# Ausreißer
ggplot(data = l1_residuen, aes(y= .resid)) + theme_gray() +
geom_boxplot()
ggplot(data = l1_residuen, aes(x= .resid, y= as.factor(class))) +
theme_gray() + geom_boxplot()
# B. Level 2 Residuen
l2_residuen <- hlm_resid(random_slopes, level="class",
include.ls = FALSE) # Funktion aus HLMdiag-Package
head(l2_residuen)
# 1. Random Intercept
# Normalverteilung
ggplot(data = l2_residuen, aes(.ranef.intercept)) +
geom_histogram(aes(y = ..density..), bins=10) +
stat_function(fun = dnorm,
args = list(mean = mean(l2_residuen$.ranef.intercept),
sd = sd(l2_residuen$.ranef.intercept)), size=2)
shapiro.test(l2_residuen$.ranef.intercept)
# Homoskedastizität
# Vorhergesagte L2 Werte berechnen
# Die Formel dafür muss jeweils auf Basis Ihrer Fixed Effects neu aufgestellt werden!
l2_residuen <- mutate(l2_residuen, pred = 0.7377 + 0.09087 * texp)
# Streudiagramm vorhergesagte Werte und Random Intercept
ggplot(data=l2_residuen, aes(x=pred, y=.ranef.intercept)) +
geom_point()
# Ausreißer
ggplot(data = l2_residuen, aes(y= .ranef.intercept)) +
theme_gray() + geom_boxplot()
# 2. Random Slope Extraversion
# Normalverteilung
ggplot(data = l2_residuen, aes(.ranef.extrav)) +
geom_histogram(aes(y = ..density..), bins=10) +
stat_function(fun = dnorm,
args = list(mean = mean(l2_residuen$.ranef.extrav),
sd = sd(l2_residuen$.ranef.extrav)), size=2)
shapiro.test(l2_residuen$.ranef.extrav)
# Homoskedastizität
# Streudiagramm vorhergesagte Werte und Random Slope
ggplot(data=l2_residuen, aes(x=pred, y=.ranef.extrav)) +
geom_point()
# Ausreißer
ggplot(data = l2_residuen, aes(y= .ranef.extrav)) +
theme_gray() + geom_boxplot()
filter(l2_residuen, .ranef.extrav > 0.3) # aus dplyr-Package
# C. Linearität
# Graphischer Test auf Linearität
ggplot(data=popular2, aes(x=extrav, y=popular)) +
geom_point() + geom_smooth()
ggplot(data=popular2, aes(x=texp, y=popular)) +
geom_point() + geom_smooth()
# (mit Variable sex nicht, da binär)
#Rainbow-Test auf Linearität
attach(popular2)
raintest(popular ~ sex + extrav + texp) # aus lmtest-Package
detach(popular2)
# D. Multikollinearität
ols_reg <- lm(popular ~ sex + extrav + texp, data = popular2 )
summ(ols_reg, vifs=TRUE, digits=3) # aus jtools-Package
5. Literatur
Hox, J. J., Moerbeek, M., & Van de Schoot, R. (2017). Multilevel analysis: Techniques and applications (3rd edition). Routledge.
Weitere Tutorials zur Mehrebenenanalyse mit R
- Mehrebenenanalyse (mit R) 1: Grundlagen mit lme4
- Mehrebenenanalyse (mit R) 3: Zentrierung
- Mehrebenenanalyse (mit R) 4: p-Values Random Effects ermitteln
- Mehrebenenanalyse (mit R) 5: Ergebnisse berichten
- Mehrebenenanalyse (mit R) 6: Robuste Schätzung
- Mehrebenenanalyse (mit R) 7: Grundlagen mit nlme
- Formeln Mehrebenenanalyse verstehen: Videotutorial mit graphischer Erklärung der Formeln einer Mehrebenenanalyse (nicht R-spezifisch)