Tagebuchstudien und intensive longitudinal data (ILD) statistisch auswerten
Arndt Regorz, Dipl. Kfm. & MSc. Psychologie, 27.01.2025
Tagebuchstudien (dairy studies) sind ein beliebtes Erhebungsinstrument für Längsschnittdaten. Hierbei werden in kurzen Abständen relativ viele Messungen interessierender Variablen erhoben.
Der Oberbegriff für ein derartiges Untersuchungsdesign ist intensive longitudinal data (ILD). Neben Tagebuchstudien im engeren Sinne können auch andere Erfasssungsmethoden eine vergleichbare Datenstruktur ergeben, beispielsweise die tägliche oder noch häufigere Erfassung medizinischer Parameter (z.B. Symptome, Biomarker, Medikamentengabe, Behandlungsoutcomes) im Rahmen einer klinischen Studie. Die folgenden Ausführungen zur Analyse von Tagebuchstudien gelten im Wesentlichen sinngemäß neben Tagebuchdaten auch für andere Fälle von intensive longitudinal data.
INHALT
- Einführung zu Tagebuchstudien
- Statistische Herausforderungen
- Analyse mit Mehrebenenmodellen
- Tagebuchstudien für Experimente
- Andere Analyseverfahren
- Literatur
Video
(Hinweis: Mit Anklicken des Videos wird ein Angebot des Anbieters YouTube genutzt.)
1. Einführung zu Tagebuchstudien
In Tagebuchstudien können die Teilnehmenden aufgefordert werden, täglich Tagebücher oder Protokolle zu führen, in denen sie ihre Erfahrungen, Verhaltensweisen oder Gedanken über einen bestimmten Zeitraum hinweg festhalten. Das kann täglich sein, mehrmals täglich zu festgelegten Zeiten oder auch auf Basis von zeitlich zufälligen Anfragen, z.B. über eine Smartphone-App.
Tagebuchdaten liefern eine reichhaltige Quelle für intensive longitudinale Daten. Damit können Schwankungen und Muster in individuellen Erfahrungen erfasst werden. Häufig geht es, anders als in anderen Längsschnittstudien, weniger um zeitliche Trends, sondern mehr um das Zusammenspiel verschiedener Konstrukte im Zeitverlauf.
Einige Beispielfragen, die man mit Tagebuchstudien untersuchen könnte:
- Die Teilnehmenden führen ein tägliches Tagebuch, in dem sie verschiedenen Emotionen im Laufe des Tages festhalten. Ziel: Die Struktur und Dynamik von Emotionen im täglichen Leben zu untersuchen.
- Die Teilnehmenden führen ein Schlaf-Tagebuch, in dem sie Informationen über ihre Schlafmuster, -qualität und eventuelle begleitende psychiatrische Symptome festhalten. Ziel: Die Beziehung zwischen Schlaflosigkeit und Depression zu untersuchen.
- Die Teilnehmenden führen ein tägliches Stress-Tagebuch, in dem sie aufgetretene Stressoren, ihre subjektiven Stressniveaus und von ihnen eingesetzte Bewältigungsstrategien dokumentierten. Ziel: Die täglichen Erfahrungen von Stress zu verstehen und individuelle Unterschiede in den Bewältigungsmechanismen zu erforschen.
2. Statistische Herausforderungen
Bei der Analyse von intensive longitudinal data, z.B. für diary studies, gibt es mehrere Herausforderungen aus statistischer Sicht, die eine Analyse mit einfachen statistischen Verfahren, wie beispielsweise der multiplen Regression, nicht ohne weiteres möglich machen.
Wie die meisten statistischen Standardverfahren geht die multiple Regression von unabhängigen Beobachtungen aus (= Unkorreliertheit der Residuen). Das heißt, dass eine Beobachtung keine besondere Beziehung zu irgendeiner anderen Beobachtung im Datensatz hat.
Diese Annahme ist jedoch bei Daten mit Messwiederholung regelmäßig verletzt, da es in diesem Fall mehrere Beobachtungen von der gleichen Person im Datensatz gibt. Und diese, bzw. deren Residuen, sind in der Regel nicht statistisch unabhängig voneinander. Um diese Verbindung zwischen verschiedenen Beobachtungen der gleichen Person zu modellieren, kann man beispielsweise Verfahren der Mehrebenenanalyse einsetzen.
Aber im Gegensatz zum Standardfall der Mehrebenenanalyse bei Längsschnittdaten gibt es noch eine zweite Besonderheit bei intensiven Längsschnittdaten: Häufig besteht eine zeitliche Korrelationsstruktur der Residuen innerhalb einer Person. Wenn man Längsschnittdaten mit längeren Zeitintervallen auswertet (Beispiel: entwicklungspsychologische Studie über mehrere Jahre mit einer Messung pro Jahre) dann kann man häufig davon ausgehen, dass innerhalb einer Person die Residuen der Beobachtungen im Wesentlichen unkorreliert sind.
Bei intensiven Längsschnittdaten hingegen kann man davon nicht ausgehen. Wenn z.B. bei einer Tagebuchstudie zu Belastung und Stress am Arbeitsplatz mit zweimal täglicher Datenerfassung an irgendeinem Tag vormittags ein Störeinfluss vorliegt (z.B. Streit in der Familie), dann wird dieser Störeinfluss häufig auch noch bei weiteren zeitlich benachbarten Messzeitpunkten eine gewisse Wirkung haben. Das führt in den Daten zu einer Korrelation zwischen den Residuen benachbarter Zeitpunkte innerhalb einer Person, die man modellieren sollte, um zu korrekten Ergebnissen zu kommen. Hierbei gibt es verschiedene Kovarianzstrukturen, die man modellieren kann, z.B. compound symmetry, autoregressive, Toeplitz oder unstructured.
3. Analyse von Tagebuchstudien mit Mehrebenenmodellen
Um die im vorherigen Abschnitt geschilderten statistischen Herausforderungen anzunehmen, eignet sich insbesondere die Mehrebenenanalyse (multilevel modeling) im Längsschnitt. Für diese Klasse von Verfahren gibt es noch eine Reihe anderer Bezeichnungen, die im Wesentlichen synonym sind: Linear mixed effects models, random effects models, hierarchische lineare Modelle, hierarchical linear modeling (HLM).
Die typische Mehrebenenstruktur für Längsschnittdaten (im Vegleich zu einem Querschnitts-Mehrebenenmodell) kann man aus dieser Grafik ersehen:
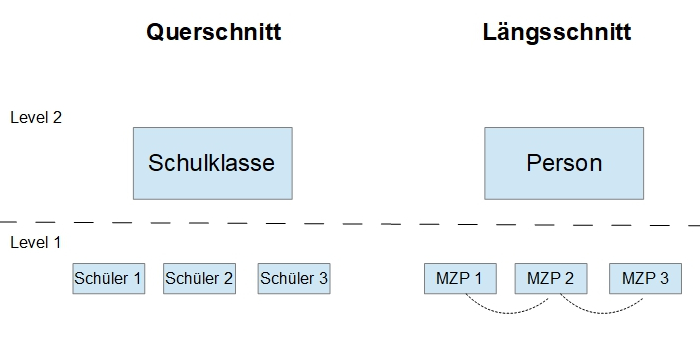
Auf der untersten Ebene, auf Level 1, sind die einzelnen Beobachtungen (= Tagebucheinträge, Messzeitpunkte) und auf der oberen Ebenen, auf Level 2, sind die Personen. Die Verbindungen zwischen den einzelnen Beobachtungen auf Level 1 innerhalb einer Person sollen die Korrelationsstruktur der Level 1 Residuen widerspiegeln.
Die Messzeitpunkte sind also genestet in den Personen. Im Prinzip können noch weitere übergeordnete Ebenen hinzu kommen.
Beispiel:
Im Rahmen einer Psychotherapiestudie soll der Verlauf einer psychischen Erkrankung während der Psychotherapie analysiert werden. Dann wäre die tägliche Messung auf Level 1, die Patientinnen und Patienten auf Level 2 und, bei mehreren Therapeutinnen, die Therapeutin auf Level 3. Auch eine derartige Struktur mit mehr als zwei Ebenen kann grundsätzlich mit Methoden der Mehrebenenanalyse ausgewertet werden. Die weitere Darstellung im Folgenden beschränkt sich jedoch auch Gründen der Übersichtlichkeit auf Designs mit nur zwei Ebenen (Messzeitpunkt auf Level 1 und Person auf Level 2).
Auf den verschiedenen Ebenen können jetzt unterschiedliche Variablen betrachtet werden.
Auf Level 1 ist zum einen als die wesentliche Prädiktorvariable die Zeit angesiedelt. Damit kann man analysieren, wie sich ein Outcome (das auch auf Level 1 gemessen wird) im Zeitablauf verändert – wobei nicht jede Tagebuchstudie an einer derartigen Analyse zeitlicher Trends interessiert ist, manchmal geht es auch nur um das Wechselspiel zwischen verschiedenen Variablen ohne Annahme eines zeitlichen Trends. Weiterhin können auf Level 1 sogenannte time varying covariates betrachtet werden, also Prädiktorvariablen, die sich im Zeitablauf ändern und zu jedem Zeitpunkt erfasst werden.
Auf Level 2 hingegen können time-invariant covariates in die Analyse eingeschlossen werden. Das können Personenvariablen sein, wie z.B. Alter oder Geschlecht. Aber auch die Zugehörigkeit zur Interventionsgruppe oder Kontrollgruppe im Rahmen eines Experiments wäre eine Level 2 Prädiktorvariable (mehr dazu im Folgenden Abschnitt: Tagebuchstudien für Experimente).
Außerdem können auf Level 2 auch die Mittelwerte von time varying covariates eingeschlossen werden, um so analytisch eine Zerlegung zwischen between- und within-Effekten zu erzielen. Prädiktorvariablen haben mitunter auf verschiedenen Ebenen unterschiedliche Einflüsse, sowohl was die Stärke angeht als sogar auch die Richtung (Vorzeichen des Effekts).
Beispiel:
Es wird im Rahmen einer Tagebuchstudie der Zusammenhang zwischen körperlicher Aktivität und Herzfrequenz untersucht. Dann ist zu erwarten, dass auf Level 1 zu Zeitpunkten hoher körperlicher Aktivität auch die Herzfrequenz höher ist (positiver Zusammenhang). Wenn es jedoch um die durchschnittliche körperliche Aktivität einer Person geht (Mittelwert aller Tagebucheinträge zur körperlichen Aktivität einer Person), dann ist auf Level 2 ein negativer Zusammenhang mit der Herzfrequenz zu erwarten – gut trainierte Menschen haben meistens eine geringere durchschnittliche Herzfrequenz.
Derartige unterschiedliche Wirkungen auf Level 1 und auf Level 2 kann man mit der Mehrebenenanalyse auseinander rechnen. Wenn man das nicht macht, erhält man Effektschätzungen, die eine Mischung der Effekte auf verschiedenen Ebenen sind und daher schlecht zu interpretieren sind.
Weiterhin kann man im Rahmen der Mehrebenenanalyse sog. random slopes betrachten. Man kann damit prüfen, ob sich der Effekt von Level 1 Prädiktoren (Zeit und/oder time varying covariates) zwischen verschiedenen Versuchspersonen signifikant unterscheidet.
Und wenn das der Fall sein sollte, kann man mittels einer cross level interaction prüfen, ob Unterschiede in den Level 1 Effekten auf Level 2 Variablen zurückzuführen sind.
Beispiel:
Hat das Geschlecht (Level 2 Prädiktor) einen Einfluss auf Effekte von Level 1 Prädiktoren?
Ein möglicher Ablauf bei der Analyse von Längsschnittdaten als linear mixed effects model wäre, nach einer vorherigen explorativen Datenanalyse (z.B. mit Grafiken):
- Leeres Modell ohne Prädiktoren (unconditional model)
- Einschluss von Zeit als Prädiktor (falls es für die Fragestellung relevant ist)
- Einschluss von time-invariant covariates
- Einschluss von time varying covariates
- Berücksichtigung von random slopes
- Berücksichtigung von cross-level interactions (Moderation von Level 1 Effekten durch Level 2 Variablen, also z.B. Moderation des Effektes der Zeit durch time-invariant covariates)
- Prüfung verschiedener Kovarianzstrukturen der Level 1 Residuen (z.B. Autokorrelation 1. Grades)
Neben den genannten, für Längsschnittdaten spezifischen, Punkten gelten aber auch die anderen Überlegungen, die grundsätzlich beim Einsatz von Mehrebenenmodellen relevant sind, wie z.B. die Auswahl des Analysealgorithmus (ML oder REML), die Zentrierung von Prädiktoren, usw.
In dem vorliegenden Tutorial wird allgemein auf die Auswertung von intensive longitudinal data eingegangen. Die konkrete Umsetzung hängt dann jedoch von der verwendeten Software ab. Dazu habe ich für SPSS und für R jeweils gesonderte Tutorials erstellt:
Längsschnitt-Mehrebenenanalyse mit SPSS:
Tutorial Linear Mixed Effects Model (longitudinal) mit SPSS
Längsschnitt-Mehrebenenanalyse mit R:
Tutorial Linear Mixed Effects Model (longitudinal) mit R
Bei R ist zu beachten, dass nicht alle Packages zur Mehrebenenanalyse in der Lage sind, mit korrelierten Level 1 Residuen umzugehen – das Tutorial stützt sich dort auf das nlme-Package, welches dies Möglichkeit bietet.
Allerdings kann man grundsätzlich auch das lme4-Package für derartige Daten nutzen. Nur muss man dann zusätzlich cluster-robuste Standardfehler einsetzen, z.B. mit dem clubSandwich-Package.
4. Tagebuchstudien für Experimente
Auch Experimente kann man mit Hilfe von intensiven Längsschnittdaten untersuchen. Klassisch untersucht man die Wirkung von Interventionen häufig mit einem Prä-post-Design, bei dem man vor und nach der Intervention die interessierende Outcomevariable erhebt, sowohl in der (oder den) Interventionsgruppe(n) als auch in einer Kontrollgruppe.
Jedoch ist eine einzelne Datenerhebung vor und nach einer Intervention relativ anfällig auf Messfehler. Zudem kann man so nicht den Wirkungsprozess untersuchen, wie sich also die Wirkung der Intervention im Zeitablauf entfaltet. Dafür braucht man weitere Erhebungszeitpunkte.
Wenn man also nach dem Beginn einer Intervention z.B. im Rahmen einer Tagebuchstudie die Outcomevariable erfasst oder auch jenseits von Tagebuchstudien im medizinischen Bereich täglich die Entwicklung eines Outcome nach Beginn einer Medikamentengabe, dann hat man eine Datenstruktur, die man gut mit Methoden für intensive longitudinal data analysieren kann.
Beispiel:
Untersucht werden soll die Wirkung eines Online-Trainingsprogramms zur Stressreduzierung auf den Stress am Arbeitsplatz. Dazu wird unmittelbar vor Beginn der Trainingsmaßnahme sowie anschließend über drei Wochen täglich der Stress im Rahmen einer Tagebuchstudie mit einem Kurzfragebogen zum Stress erfasst.
Wenn man derartige experimentelle Daten mit einer Mehrebenenanalyse auswerten möchte, dann ist die Mitgliedschaft in der Experimental- oder Kontrollgruppe in der Regel ein Level 2 Prädiktor, also eine time-invariant covariate. Und der in erste Linie interessierende Effekt ist die Cross-Level-Interaktion zwischen der Gruppenzugehörigkeit (Level 2) und der Zeit (Level 1). Denn damit kann man prüfen, ob sich der Zeitverlauf des Outcomes zwischen der Interventionsgruppe und der Kontrollgruppe signifikant voneinander unterscheidet.
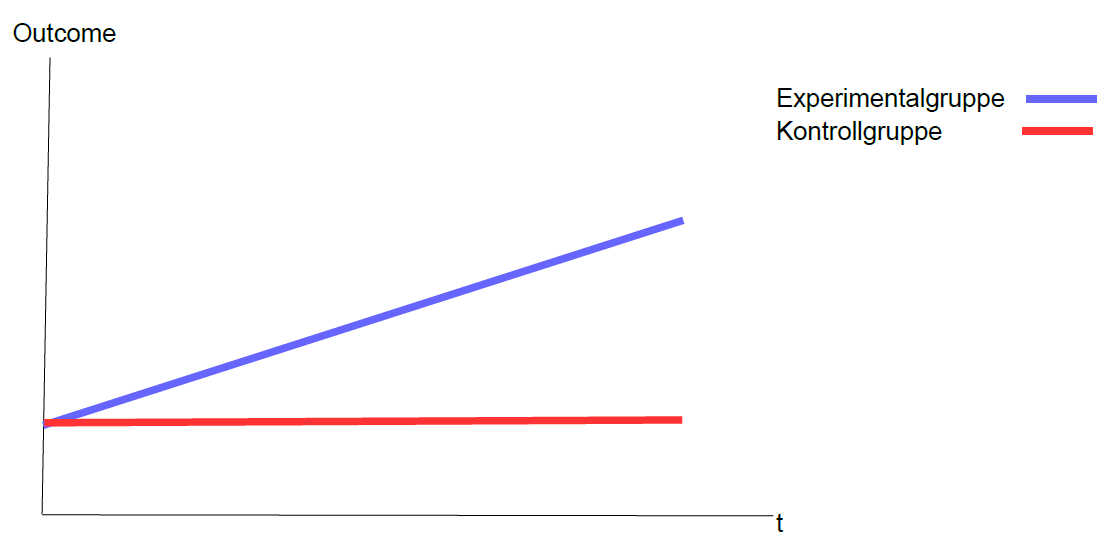
Dabei kommt neben einem linearen Verlauf auch ein nicht linearer Verlauf des Outcomes über die Zeit in Frage. Dies kann man über eine polynomiale Modellierung des Effektes der Zeit analysieren, bei der man zusätzlich zur Zeit auch noch das Quadrat der Zeit als Level 1 Prädiktor in das Modell einschließt.
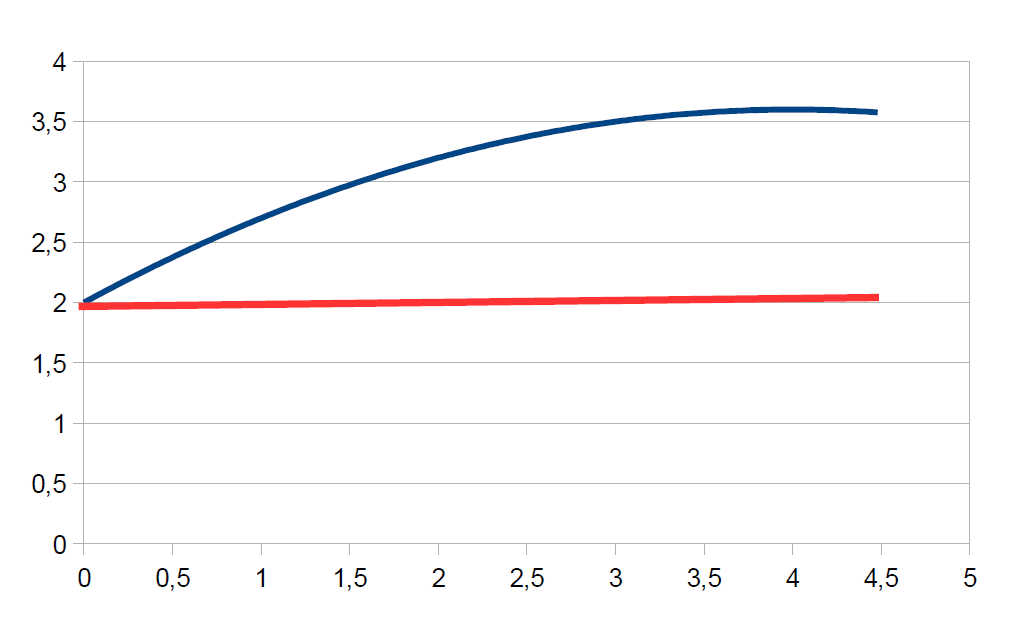
Manchmal möchte man auch bereits vor der Intervention mehrere Messungen durchführen, um eine stabilere Schätzung der Baseline für das Experiment zu bekommen. Das führt jedoch zu der Komplikation, dass – wenn das Experiment wirkt – ein Strukturbruch zum Zeitpunkt der Intervention in den Daten auftreten kann.
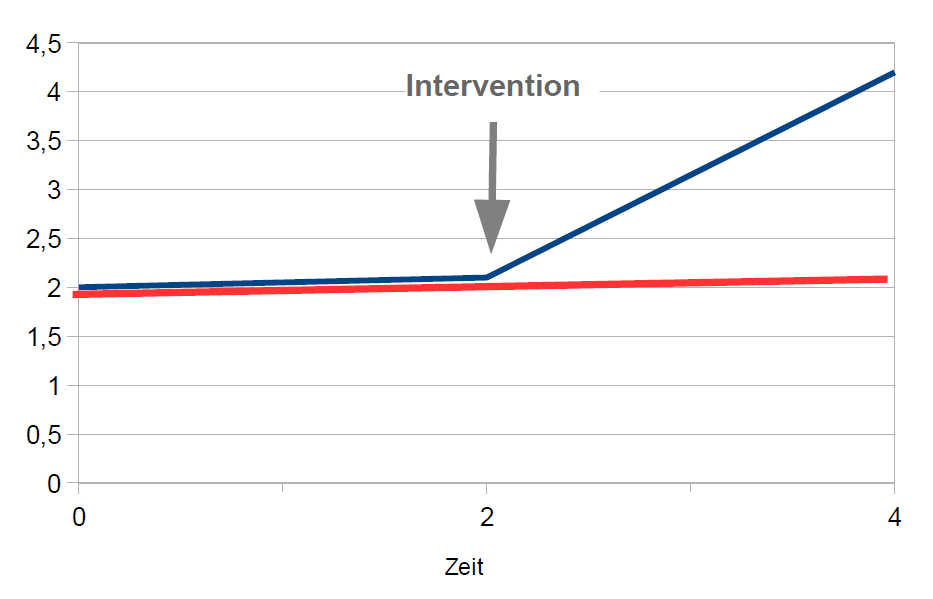
Auch derartige Diskontinuitäten kann man im Rahmen der Mehrebenenanalyse modellieren, mit Verfahren der piecewise regression (segmented regression, broken-stick regression).
5. Andere Verfahren für Tagebuchstudien
Für intensive longitudinal data sind Mehrebenenmodelle das Standardauswertungsverfahren. Das hat zudem den Vorteil, dass es mit vielen Softwareprogrammen einsetzbar ist und dass Mehrebenenanalysen in den Sozialwissenschaften häufiger auch zumindest im Masterstudiengang schon Thema waren.
Jedoch gibt es noch weitere Verfahren, die auch für die Auswertung von Tagebuchstudien und allgemeiner intensiven Längsschnittdaten einsetzbar sind. Hier kommt als Alternative zu linear mixed effects models insbesondere der Einsatz dynamischer Strukturgleichungsmodelle (SEM) in Frage.
Dynamische SEM sind vor allem für die Analyse stabiler Prozesse geeignet. Es geht beim Einsatz dieser Technik also nicht um Zeittrends, sondern um die stabil angenommene Wechselwirkung zwischen verschiedenen Variablen über die Zeit (also unter der Annahme der Stationärität / stationarity). Allerdings kann man solche Fragestellung durchaus auch mit Mehrebenenmodellen untersuchen (dort allerdings ohne latente Messmodelle für die Konstrukte).
Beispiel:
Sagt der negative Affekt heute den Alkoholkonsum, kontrolliert für den Alkoholkonsum des Vortages?
Sagt der Alkoholkonsum heute den negativen Affekt für den Folgetag voraus, kontrolliert für den negativen Affekt heute?
(Bauer & Curran, 2022b)
Im Gegensatz zur Analyse von Tagebuchstudien mit Mehrebenenmodellen kann man beim dynamischen SEM auch Messmodelle integrieren und damit für Messfehler / Reliabilitätseinschränkungen kontrollieren.
Allerdings ist dieses Verfahren deutlich anspruchsvoller und auch hinsichtlich der dafür geeigneten Software weniger zugänglich als die Verwendung von Mehrebenenanalysen für Tagebuchstudien.
(Ich biete aktuell für Tagebuchstudien nur Beratung für Mehrebenenanalysen an, nicht für dynamic SEM).
6. Literatur
Barrett, L. F., & Russell, J. A. (1999). The structure of current affect: Controversies and emerging consensus. Current Directions in Psychological Science, 8(1), 10-14.
Bauer, D. J., & Curran, P. J. (2022a). Intensive longitudinal data: A multilevel modeling perspective [slides]. Centerstat. https://centerstat.org/wp-content/uploads/2022/09/ILD-Day-2.pdf
Bauer, D. J., & Curran, P. J. (2022b). Intensive longitudinal data: A dynamic structural equation modeling perspective [slides]. Centerstat. https://centerstat.org/wp-content/uploads/2022/10/ILD-Day-3.pdf
Bolger, N., Davis, A., & Rafaeli, E. (2003). Diary methods: Capturing life as it is lived. Annual Review of Psychology, 54, 579-616.
Nezlek, J. (2020). Diary studies in social and personality psychology: An introduction with some recommendations and suggestions. Social Psychological Bulletin, 15(2), 1-19.
Segmented regression. (2021, June 24). In Wikipedia. https://en.wikipedia.org/w/index.php?title=Segmented_regression&oldid=1030201444
Singer, J. D., & Willett, J. B. (2003). Change and event occurrence. Oxford University Press.
Taylor, D. J., Lichstein, K. L., Durrence, H. H., Reidel, B. W., & Bush, A. J. (2005). Epidemiology of insomnia, depression, and anxiety. Sleep, 28(11), 1457-1464.