SPSS: Linear Mixed Effects Model
(Mehrebenenmodell mit Längsschnittdaten)
Arndt Regorz, Dipl. Kfm. & MSc. Psychologie, 30.10.2025
Sie wollen Längsschnittdaten mit einem Linear Mixed Effects Model (LMEM, Mehrebenenmodell, Hierarchisches lineares Modell, Linear growth model - es gibt viele Namen dafür) auswerten? Dieses Tutorial zeigt Ihnen, wie Sie longitudinale Daten mit SPSS auswerten können.
Das hier vorgestellte Modell stammt aus dem Grundlagenwerk von Hox et a. (2017) zur Mehrebenanalyse, dort in Kapitel 5 vorgestellt. Die Daten dazu können Sie auf der Internetseite von Hox herunterladen (http://joophox.net/mlbook2/DataExchange.zip), so dass Sie alle Auswertungen selbst nachvollziehen können.
Es handelt sich hier um Längsschnittdaten von 200 Studierenden. Die Kriteriumsvariable "gpa" (Grade Point Average, Durchschnittsnote; hoher Wert = gute Note) wurde in sechs aufeinanderfolgenden Semestern erhoben. Ebenfalls pro Semester wurde erhoben, wie viele Stunden die Studierenden neben dem Studium gearbeitet hattten (Variable "job"). Außerdem wurde das Geschlecht der Studierenden erfasst ("sex", 0 = männlich, 1 = weiblich) und die Durchschnittsnote während der Oberschule ("highgpa" = high school GPA).
INHALT
- Grundlagen
- Nullmodell
- Zeit als Prädiktor
- Time varying und time invariant covariates
- Random Slope für die Zeit
- Cross-Level-Interaction
- Kovarianzstruktur für Level 1 Residuen
- Codierung der Variable Zeit
- Linear Mixed Effects Model für Experimente
- Modellierung nicht-linearer Effekte
- Video
- Literatur
1. Grundlagen
Um das Maximum aus diesem Tutorial mitzunehmen, ist ein gewisse Grundverständnis der Mehrebenenanalyse/HLM hilfreich. Falls Sie dazu noch keine Basiskenntnisse haben, empfehle ich das Buch von Hox et al. (2017), insbesondere die Kapitel 2-5, 12-13.
In Modellen für Querschnittsdaten gibt es in der Regel die Annahme, dass die Level 1 Residuen nicht miteinander korreliert sind (Ausnahme im Querschnitt: Spatial Autocorrelation, wenn man im Raum benachbarte Objekte analysieren möchte, was in den Sozialwissenschaften selten vorkommt). Diese Annahme ist jedoch für Längsschnittdaten problematisch, insbesondere für intensive longitudinal data , wie sie z.B. in Tagebuchstudien (diary studies) vorkommen. Dort muss man nämlich davon ausgehen, dass es durchaus eine Korrelation zwischen benachbarten Messzeitpunkten gibt: Wenn z.B. drei Mal am Tag eine Messung erfolgt, dann kann ein Störeinfluss auf einen Messzeitpunkt (z.B. ein Konflikt im Büro) regelmäßig auch Auswirkungen auf benachbarte Messzeitpunkte (MZP) haben, was dann zu einer Autokorrelation der Residen führt.
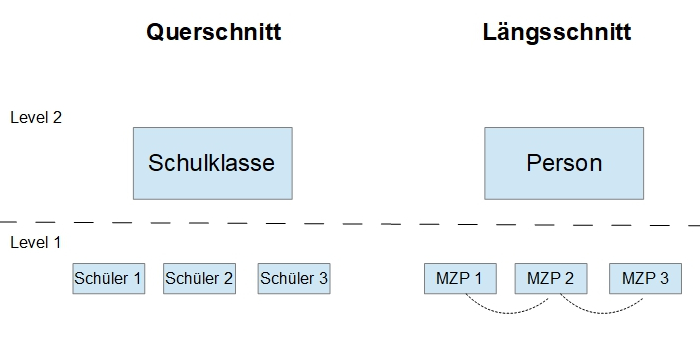
Für Längsschnittmodelle mit längeren Zeitintervallen ist das weniger ein Problem. Wenn Sie also beispielsweise für eine Entwicklungsstudie einmal pro Jahr die Daten messen, werden Sie häufig auch mit einem Modell ohne korrelierte Level 1 Residuen akzeptable Ergebnisse erzielen. Wenn Sie jedoch z.B. eine Tagebuchstudie (diary study) mit SPSS auswerten wollen, dann müssen Sie unbedingt darauf achten, dass Sie auch die Level 1 Korrelationen modellieren, um keine verzerrten Schätzungen zu bekommen. In SPSS haben Sie die Auswahl zwischen zahlreichen möglichen Korrelationsstrukturen für Level 1.
Zwar ist der hier verwendete Beispieldatensatz ein Datensatz mit längeren Messintervallen, so dass auch eine Modellierung ohne Level 1 Korrelationen möglich wäre. Damit Sie jedoch mit diesem Tutorial grundsätzlich in der Lage sind, Längsschnittdaten auszuwerten, werde ich am Ende zusätzlich zu den Analysen nach Kapitel 5 von Hox et al. (2017) auch noch ein Modell mit Korrelationsstruktur auf Level 1 schätzen.
Hinweis: Bei der folgenden Modellierung wurde aus didaktischen Gründen entsprechend dem Beispiel aus dem Buch von Hox et al. (2017) durchweg die ML-Schätzung statt der REML-Schätzung verwendet.
2. Nullmodell
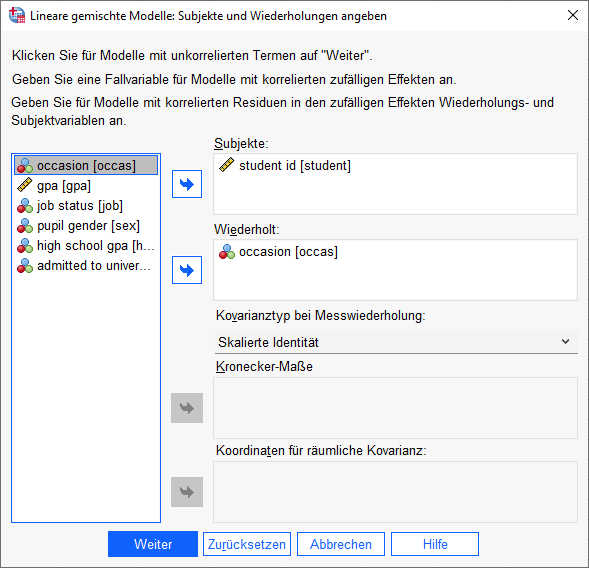
Wir finden den Aufruf zu Linear Mixed Effects Modellen unter Analysieren-Gemischte Modelle-Linear. Im Einstiegsbild habe ich folgende Einstellungen vorgenommen:
- Das ID-Feld der Versuchspersonen in das Feld "Subjekte" gezogen
- Die Messwiederholungsvariable (Messzeitpunkt bzw. Zeit) in das Feld "Wiederholt" gezogen
- Den "Kovarianztyp bei Messwiederholung" habe ich zunächst auf Skalierte Identität gestellt.
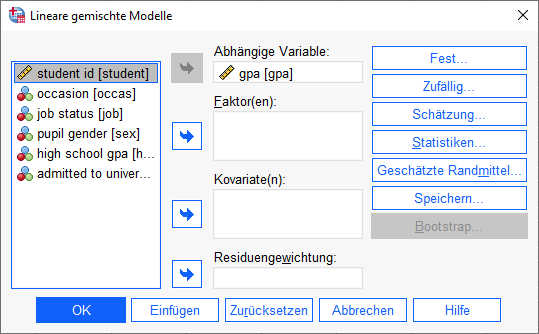
Im folgenden Dialog habe ich dann die abhängige Variable gpa in das Feld "Abhängige Variable" gezogen.
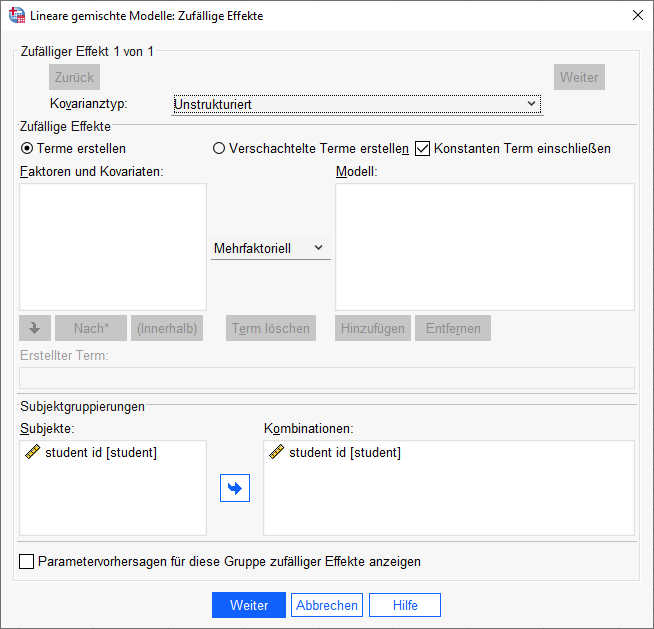
Unter der Schaltfläche "Zufällige Effekte" habe ich zunächst oben den Kovarianztyp auf "Unstrukturiert" geändert. Das ist zwar jetzt noch nicht erforderlich, aber wenn man es später beim Modell mit der Random Slope vergisst, bekommt man falsche Ergebnisse - nachdem mir das schon häufiger passiert ist, ändere ich das inzwischen lieber gleich am Anfang.
Außerdem setze ich den Haken bei "Konstanten Term einschließen" sowie ziehe unten bei Subjektgruppierungen die student id nach rechts in das Feld "Kombinationen".
Unter der Schaltfläche "Schätzung" habe ich die Methode auf "Maximum Likelihood" geändert, da Hox et al. (2017) in ihrem Buch auch damit geschätzt haben.
Schließlich unter der Schaltfläche "Statistiken" habe ich ausgewählt die Parameterschätzungen und Tests auf Kovarianzparameter.
Bei den Ergebnissen bekommen wir unter "Informationskriterien" zunächst einige Angaben zum Modell-Fit.
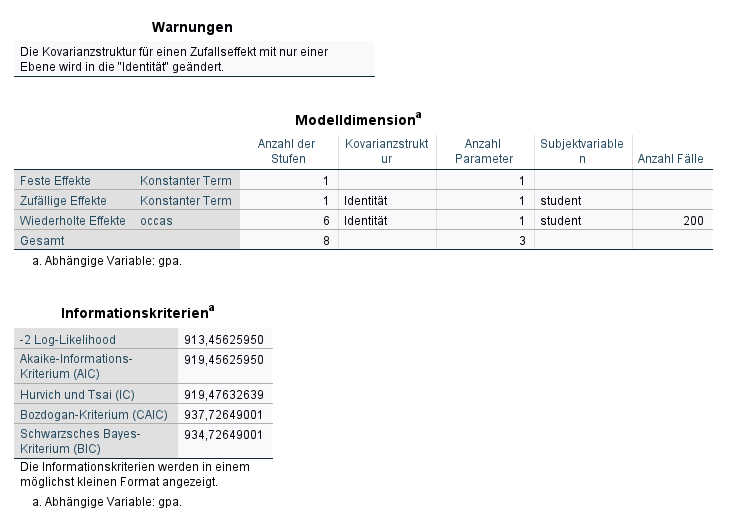
Neben mehreren Fit-Indizes, insbesonder AIC und BIC (hier sind jeweils kleinere Werte besser), wird die - 2 LogLikelihood ausgewiesen, die ein Maß für die Passungsgüte des gewählten Modells ist. Ein anderer Name für diese Größe ist Deviance. Eine kleinere Deviance ist besser - wir könnte im Folgenden noch sehen, in welchem Maß mit der Aufnahme von Prädiktoren sich die Modellgüte und damit die - 2 LogLikelihood verbessert; aus Platzgründen habe ich jedoch darauf verzichtet, für jeden Modellschritt diese Tabelle hier zu wiederholen.
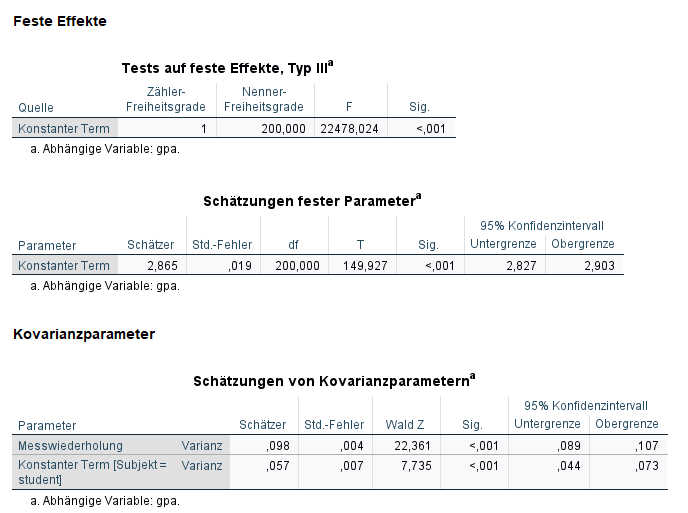
Da wir noch keine Prädiktoren im Modell aufgenommen haben, bestehen die Fixed Effects ("Schätzung fester Parameter") nur aus der Schätzung des Intercepts (="Konstanter Term").
Bei den Random Effects werden zwei aufgeführt: Der Random Intercept ("Konstanter Term"), also das Ausmaß der Schwankung des Intercepts (und hier ohne Prädiktoren daher des Mittelwerts) der Uninote zwischen den Studierenden, und das Level 1 Residuum ("Messwiederholung"), also die Notenschwankung innerhalb einer Person.
Aus diesen beiden Werten könnte man jetzt die Intraklassenkorrelation berechnen, ICC = 0.057 / (0.098 + 0.057) = .37
3. Zeit als Prädiktor
Jetzt ergänzen wir unser Modell um Zeit (occas) als ersten Prädiktor. Dazu ziehen wir im zweiten Bild diesen Prädiktor in das Feld "Kovariaten".
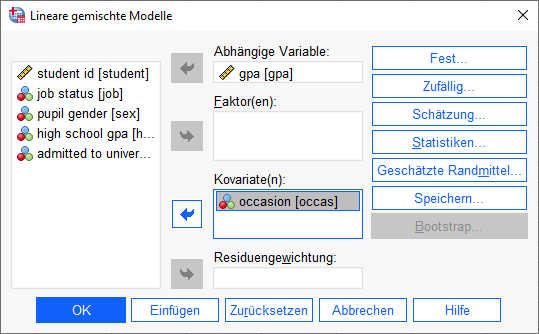
Das reicht aber noch nicht aus. Anschließend müssen wir noch im Dialog "Feste Effekte" diesen mit in das Modell aufnehmen, erst dann wird dieser Prädiktor berücksichtigt.
Der Modellfit hat sich deutlich verbessert (hier nicht abgedruckt). Und jetzt ist bei den festen Effekten der Effekt des Messzeitpunkts hinzugekommen.
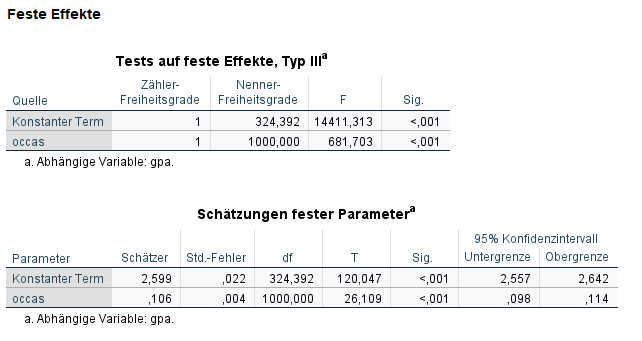
Für die Zeit (occas) zeigt sich jetzt bei den Schätzungen fester Parameter ein signifikant positiver Effekt - mit längerem Studium werden die Noten besser.
4. Time varying und time invariant covariates
Neben der Zeit möchten wir in der Regel noch weitere Prädiktoren in unser Modell aufnehmen, sog. covariates (Kovariaten). Beim Linear Mixed Effects Model unterscheidet man dabei zwei Arten von Kovariaten: time varying und time invariant. Time varying Kovariaten sind Prädiktoren auf Level 1, die also zu jedem Messzeitpunkt einen anderen Wert annehmen können. In unserem Beispiel ist das die Variable Job Status (job).
Im gleichen Schritt ergänzen wir das Modell auch noch um time invariant covariates (hier abweichend von Hox et al., die das in zwei getrennten Schritten gemacht haben). Das sind Prädiktoren auf Level 2, also Variablen, die für alle Messzeitpunkte gleich sind. Im Beispiel sind das die Abschlussnote der Schule (highgpa) und das Geschlecht (sex).
Das Vorgehen ist wie beim vorherigen Modell. Zunächst werden auf dem zweiten Bild die zusätzlichen Prädiktoren (job, sex, highgpa) in das Feld Kovariaten gezogen.
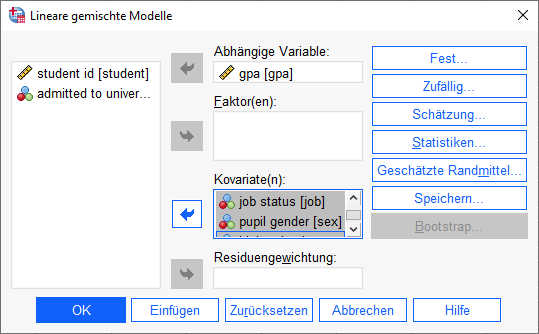
Anschließend wird im Dialog "Feste Effekte" das Modell um diese drei Variablen ergänzt.
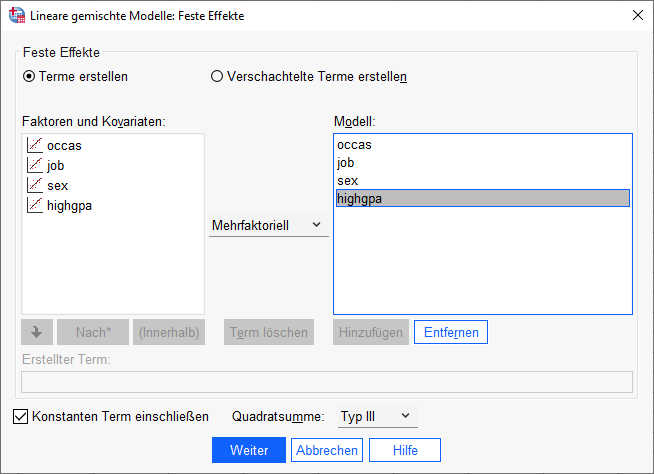
Sie sollten darauf achten, dass Sie die Variablen einzeln nach rechts hinzufügen. Wenn Sie nämlich mehrere gleichzeitig markieren und dann auf "hinzufügen" klicken, würde bei der aktuellen Einstellung (in der Mitte: "Mehrfaktoriell") auch noch die Erstellung aller möglichen Interaktionsterme erfolgen, die wir jetzt noch nicht einschließen möchten.
Als Ergebnis dieses Modells erhalten wir für die Fixed Effects:
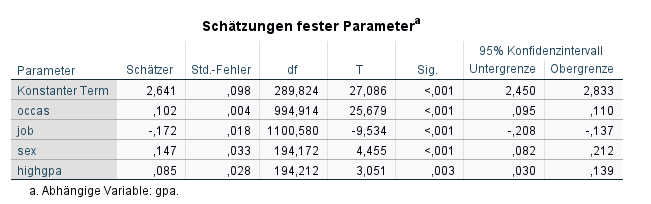
Der Nebenjob (job) hat einen signifikant negativen Effekt auf die Noten - je mehr Stunden zu einem Messzeitpunkt jemand neben dem Studium arbeitete, desto schlechter die Noten.
Bei den time invariant covariates sehen wir, dass Studierende mit besserer Schulnote dann auch später im Studium bessere Noten haben. Außerdem sehen wir einen signifikanten Geschlechtseffekt - die Studentinnen (sex = 1) haben bessere Noten als die Studenten (sex = 0).
5. Random Slope für die Zeit
In einem weiteren Schritt nehme wir jetzt eine Random Slope in das Modell auf, und zwar für den Messzeitpunkt. Das bedeutet wir lassen jetzt zu, dass der Effekt der Zeit sich zwischen verschiedenen Versuchspersonen unterscheiden kann.
Dazu nehmen wir im Dialog "Zufällige Effekte" jetzt die Variable occas in das Modell auf.
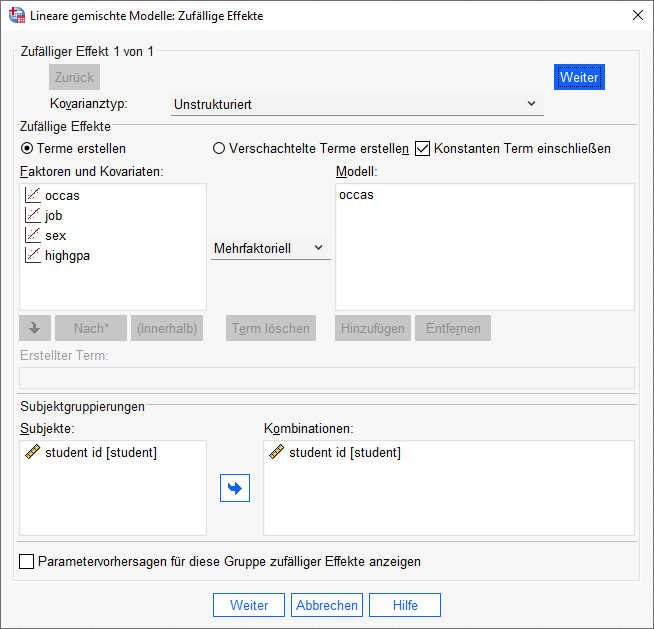
Als Ergebnis erhalten wir jetzt für die Zufallseffekte:
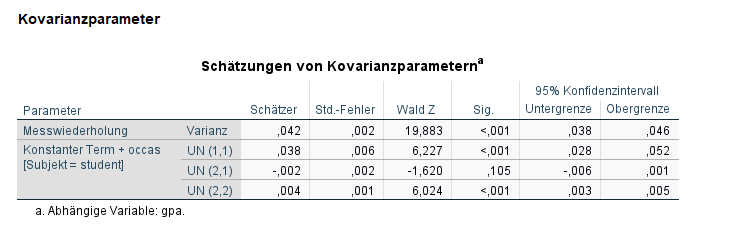
Jetzt sehen wir, dass bei den Random Effects zwei Effekte dazu gekommen sind. Zum einen gibt es jetzt einen signifikanten Random Effect für occasion, hier UN (2,2) - das ist die Schwankung des Zeiteffektes zwischen den verschiedenen Studierenden. Und da wir mehr als einen Random Effect haben (Random Intercept und Random Slope für occasion) wird auch noch eine Korrelation dieser beiden Zufallseffekte ausgewiesen, UN (2,1), die in diesem Beispiel aber nicht signifikant ist.
6. Cross Level Interaction
Da wir im vorherigen Schritt eine signifikante Varianz in der Slope für die Zeit hatten, stellt sich die Frage, wodurch das u.U. zu erklären ist. Dafür kommen Cross-Level-Interaktionen in Frage, also hier Interaktionen von time invariant covariates mit der Zeit. In diesem Modell wollen wir prüfen, ob der Effekt der Zeit sich vielleicht zwischen den Geschlechtern unterscheidet. Dazu ergänzen wir die Fixed Effects im Dialog "Feste Effekte", in dem wir occas und sex anklicken und dann (bei Option "Mehrfaktoriell" in der Mitte) ins Modell hinzufügen.
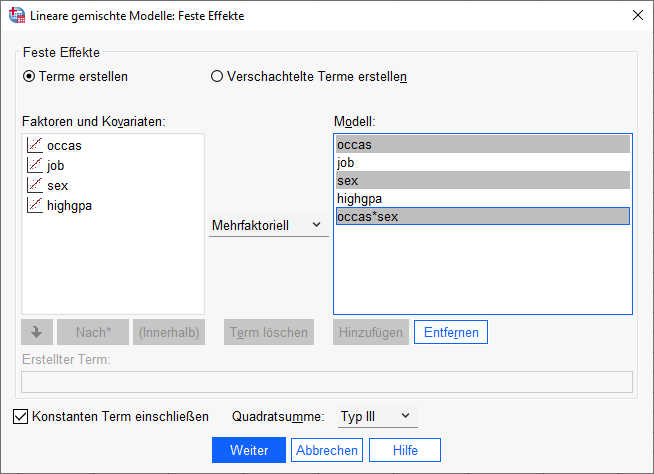
Als feste Effekte erhalten wir dann:
Die Cross-Level-Interaktion wird hier signifikant. Aufgrund des positiven Vorzeichens sehen wir, dass bei Studentinnen (sex = 1) der Zeiteffekt signifikant stärker ist als bei Studenten (sex = 0).
7. Kovarianzstruktur für Level 1 Residuen
Bisher hatten wir keine Kovarianzstruktur auf Level 1 vorgegeben. Die implizite Annahme war also, dass die Level 1 Residuen der Messzeitpunkte einer Person voneinander unabhängig sind.
Wenn man diese Annahme nicht aufrecht erhält (insbesondere bei intensiven Längsschnittdaten, ILD), kann man mit SPSS auch verschiedene Kovarianzstrukturen der Level 1 Residuen schätzen - wenn man das nicht tut, wird diese vom Programm als unkorreliert angenommen. Hier im Beispiel werden wir eine der häufigsten Korrelationsstrukturen für Level 1 ausprobieren, die Autokorrelation ersten Grades.
Autokorrelation ersten Grades bezieht sich auf die Korrelation zwischen einer Zeitreihe und ihrer eigenen um einen Lag (Zeitversatz) von einem Schritt verschobenen Version. Mit anderen Worten, es misst die Stärke der Beziehung zwischen einem Wert und dem vorherigen Wert in einer Zeitreihe.
Die Korrelationsstruktur können wir spezifizieren im ersten Dialogfeld unter "Kovarianztyp bei Messwiederholung". Dort können Sie auch zahlreiche andere mögliche Kovarianzstrukturen einstellen.
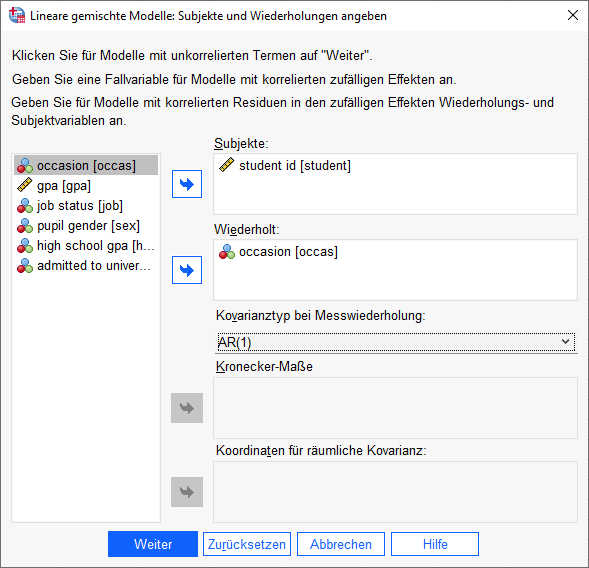
Als Ergebnis erhalten wir:
Beim Modellfit hat sich nicht stark verbessert (hier nicht abgedruckt). Das ist insoweit nicht erstaunlich, da der Zeitabstand zwischen den Messungen (ein Semester) relativ groß ist, so dass keine große Korrelation zwischen einzelnen Beobachtungen bzw. deren Residuen zu erwarten war. Auch bei den Parameterschätzungen sehen wir kaum Unterschiede zum vorherigen Modell.
Neu aufgenommen in den Output der Kovarianzparameter wurde jetzt die Parameterschätzung für die Korrelationsstruktur, hier die Schätzung für die Autokorrelation (AR1, Rho).
8. Kodierung der Variable Zeit
Eine Schlüssefrage für ein Längsschnittmodell ist die Kodierung der Variable Zeit (bzw. der Variable Messzeitpunkt).
Zum einen kann man hinsichtlich der Zeit zwischen zwei verschiedenen Designs unterscheiden: Fixed Occasions und Varying Occasions.
Bei Fixed Occasions werden bei den verschiedenen Untersuchungseinheiten / Versuchspersonen die Messungen zum gleichen Zeitpunkt durchgeführt. Das o.g. Beispiel ist ein Modell mit Fixed Occasions (alle zum 1., 2., 3. usw. Semester).
Bei Varying Occasions ist der Zeitpunkt der Messung zwischen den Untersuchungseinheiten / Versuchspersonen unterschiedlich. Ein Beispiel dafür wäre eine Entwicklungsstudie, die im Klassenkontext erhoben wird. Wenn zu Beginn der 5. Klasse Daten erhoben werden, sind einige Schülerinnen und Schüler vielleicht 10.4 Jahre alt und andere 10.9 Jahre. In diesem Fall würde man das, variable, Alter als Zeitvariable nutzen und nicht die Klassenstufe, weil in der Kindheitsentwicklung ein halbe Jahr schon einen sehr deutlichen Effekt haben kann.Eine zweite Frage im Zusammenhang mit der Zeit ist der Nullpunkt der Variable. Die Schätzung von Intercepts ergibt jeweils den vorhergesagten Wert der Kriteriumsvariable, wenn die Prädiktoren eine Ausprägung von Null haben. Daraus ergibt sich, dass es beispielsweise nicht sinnvoll ist, Jahreszahlen für die Variable Zeit zu verwenden. Wenn Sie eine Untersuchung der Jahre 2018-2022 vorgenommen haben und die Jahreszahl als Variable verwenden, dann würde der Intercept die Schätzung der Kriteriumsvariable zum Jahre 0, also vor 2000 Jahren, angeben. Das ist relativ selten ein für uns relevanter Wert.
Daher bietet es sich häufig an, die Zeit so umzucodieren, dass der erste Messzeitpunkt den Wert von 0 bekommt. Statt 2018-2022 würde man die Zeit also als 0-4 codieren und der Intercept gibt dann die Verhältnisse zu Beginn der Messung (im Jahr 2018) wieder.
Wenn hingegen das Alter als Zeitvariable verwendet wird, ist es meistens sinnvoll, das Alter zu zentrieren. Denn die unzentrierte Altersvariable würde dazu führen, dass der Intercept den Effekt bei einem Alter von Null Jahren ausweist.
9. Linear Mixed Effects Model für Experimente
Linear Mixed Effects Modelle können auch gut für die Auswertung von Verlaufsdaten im Rahmen eines Experiments genutzt werden. Dabei ist die Zugehörigkeit zur Experimental- oder Kontrollgruppe eine zeitinvariante Kovariate auf Level 2 (wenn die Versuchtspersonen entweder der Experimentalgruppe oder der Kontrollgruppe zugeordnet werden).
Der für ein Experiment entscheidene Effekt ist dann die Cross-Level-Interaktion zwischen der Zeit (Level 1) und der Gruppenzugehörigkeit (Level 2). Wenn diese signifikant wird, weiß man, dass sich der Zeitverlauf der abhängigen Variable zwischen den beiden Gruppen unterscheidet - und genau das möchte man bei einem Experiment in der Regel wissen.
Wenn Sie in einem Experiment mehr als zwei Gruppen haben (z.B. Interventionsgruppe 1, Interventionsgruppe 2, Kontrollgruppe), dann müssen Sie entsprechend mehrere Dummy-Variablen für die Gruppenzugehörigkeit auf Level 2 einschließen (immer eine weniger als die Anzahl der Gruppen).
10. Modellierung nicht-linearer Effekte
Mit einem derartigen Modell können Sie auch relativ einfach nicht-lineare Effekte der Zeit modellieren. Vielleicht ist es für Ihre Daten keine realistische Annahme, dass die Kriteriumsvariable sich im Zeitverlauf linear verändert? Sie können auch u-förmige, umgekehrt u-förmige oder sonstig gebogene Zeitverläufe der Daten modellieren.
Dazu schließen Sie einfach neben der Zeit auch noch zusätzlich das Quadrat der Zeit in Ihr Modell als Fixed Effekt ein. In unserem Beispiel hier würden wir also eine neue Variable anlegen (im Beispiel mit dem Quadrat von occas) und diese zusätzlich in das Modell einschließen.
Grundsätzlich ist es auch möglich, Diskontinuitäten im Zeitverlauf zu modellieren, z.B. bei mehreren Pre-Test-Werten und mehreren Post-Test-Werten. In so einem Fall ist es nämlich zu erwarten, dass zum Zeitpunkt der Intervention (bei einer experimentellen Studie) für die Interventionsgruppe ein "Knick" im Geradenverlauf zu finden ist.
11. Video zum Tutorial
Wenn Sie sich zu dem Thema zusätzlich noch ein Videotutorial ansehen möchten (Youtube):
Linear Mixed Effects Model (Längsschnitt) mit SPSS
12. Literatur
Hox, J. J., Moerbeek, M., & Van de Schoot, R. (2017). Multilevel analysis: Techniques and applications (3rd edition). Routledge.
Snijders, T. A., & Bosker, R. (2011).Multilevel analysis: An introduction to basic and advanced multilevel modeling. Sage.