Mann-Whitney U-Test (und Wilcoxon Rangsummentest)
Arndt Regorz, Dipl. Kfm. & M.Sc. Psychologie, Stand: 16.01.2020
Sie wollen die Mittelwerte aus zwei unabhängigen Stichproben vergleichen, aber die Voraussetzungen für den Zweistichproben t-Test sind nicht erfüllt? Dann ist der U-Test nach Mann und Whitney eine Alternative.
Mit diesem Test können Sie die sogenannte zentrale Tendenz (Mittelwert bzw. Median) zweier Gruppen auch dann vergleichen, wenn die abhängige Variable nur ordinalskaliert ist. Und als verteilungsfreies Verfahren muss auch die Voraussetzung der Normalverteilung in den beiden Gruppen nicht erfüllt sein.
Inhalt
- Video-Tutorial
- Zusatzmaterialien zum Video
- Wilcoxon-Rangsummentest – ein anderer Name für (fast) den gleichen Test
- Beispiele für den Anwendungsbereich
- Wie funktioniert der U-Test?
- Beispiel
- Ergebnisse des Tests
- Wie ermitteln Sie die Effektstärke?
- Welche Nullhypothese hat der Test?
- Was sind die Voraussetzungen des U-Tests?
- Wie prüfen Sie die Voraussetzungen?
- Und wenn die Voraussetzungen nicht erfüllt sind?
- U-Test für gerichtete Hypothesen
- Aufruf in SPSS
- Interpretation der SPSS Auswertung
- Testergebnisse berichten
- Median oder arithmetisches Mittel?
- Quellen
1. YouTube-Video-Tutorial
(Hinweis: Mit Anklicken des Videos wird ein Angebot des Anbieters YouTube genutzt.)
2. Zusatzmaterialien zum Video
Beispiele und Übungsaufgaben Interpretation SPSS Auswertung U-Test (pdf)
3. Wilcoxon-Rangsummentest – ein anderer Name für (fast) den gleichen Test
Der U-Test ist auch unter dem Namen "Wilcoxon-Rangsummentest" bekannt (nicht: Wilcoxon-Vorzeichen-Rangtest, der ist für verbundene Stichproben!). Das hat historische Gründe: U-Test und Wilcoxon-Rangsummentest sind fast zeitgleich entwickelt worden.
Beide Tests basieren auf genau den gleichen Prinzipien und führen jeweils zu dem gleichen Ergebnis. Insofern ist es Geschmackssache, welchen der beiden Tests Sie berichten. Beim Aufruf in SPSS werden beide gleichzeitig ausgeführt und die Teststatistiken von beiden Tests angezeigt.
Der Unterschied zwischen beiden Tests liegt darin, wie genau die Teststatistik berechnet wird. Aber auch die Prüfverteilung, mit der beim Signifikanztest der Wert der Teststatistik verglichen wird, weist den gleichen Unterschied auf. Also ändert sich deshalb am Ergebnis nichts.
Es ist ein wenig so, als wenn man Entfernungen in verschiedenen Einheiten misst. Die Entfernung in km sieht zwar zahlenmäßig anders aus als in m, aber inhaltlich ist es das Selbe.
4. Beispiele für den Anwendungsbereich
Beispiel 1 (Psychologie): Sie wollen untersuchen, ob sich die Deutschnote unterscheidet bei Schülern mit einem neuen lernpsychologisch fundierten Lernprogramm und Schülern aus einer Kontrollgruppe. Schulnoten sind jedoch nicht intervallskaliert (Voraussetzung t-Test), sondern nur ordinalskaliert.
Beispiel 2 (BWL): Sie wollen die Wirkung eines neuen Anreizsystems für Verkäufer prüfen. Dazu wird ein Zusatzbonus für einige zufällig ausgewählte Verkäufer versprochen, wenn sie bestimmte Ziele erreichen. Sie möchten testen, ob die dann erreichten Verkaufszahlen der Verkäufer mit Zusatzbonus höher sind als die der übrigen Verkäufer. Allerdings stellt sich heraus, dass die Verkaufsleistungen der Verkäufer nicht normalverteilt (Voraussetzung t-Test) sind.
Beispiel 3 (VWL): Sie wollen untersuchen, ob sich die Häufigkeit vergangener Arbeitslosigkeiten pro Person unterscheidet zwischen Ländern mit umfassender Arbeitslosenversicherung und Ländern ohne entsprechende Absicherung. Die Häufigkeit von Arbeitslosigkeit einer Person sei jedoch nicht normalverteilt (Voraussetzung t-Test).
5. Wie funktioniert der U-Test?
Der Mann-Whitney-Test ist ein sogenanntes nicht-parametrisches Verfahren. Es müssen also keine Parameter (Mittelwert, Varianz) geschätzt werden, um diesen Test durchzuführen. Stattdessen werden die Ränge der einzelnen Messwerte miteinander verglichen.
Dazu werden alle Werte der abhängigen Variable der Größe nach geordnet, beginnend mit dem kleinsten Wert. Diese Rangfolge wird gemeinsam für beide Gruppen aufgestellt.
Anschließend werden für jede der beiden Gruppen getrennt die Ränge in der Gruppe aufsummiert.
Wenn die beiden Gruppen im Wesentlichen gleich sind, dann sollten in beiden Gruppen ungefähr gleich viele hohe und niedrige Ränge auftreten und damit auch ungefähr gleich hohe Rangsummen.
Wenn aber die zentrale Tendenz (Mittelwert, Median) der beiden Gruppen unterschiedlich ist, dann wird in der Regel die Gruppe mit dem kleineren Mittelwert mehr niedrige Ränge haben und die Gruppe mit dem größeren Mittelwert mehr hohe Ränge. Und damit werden sich in diesem Fall auch die Rangsummen deutlich unterscheiden.
Bei der o.g. Bildung der Rangreihe kann noch ein Problem auftreten: Sogenannte verbundene Ränge. Es kann sein, dass ein Wert der abhängigen Variable mehr als einmal vorkommt, das nennt man Rangbindung. Dieses Problem wird beim U-Test meistens mit der Zuweisung von mittleren Rängen gelöst.
Beispiel: Der niedrigste Wert der abhängigen Variable tritt doppelt auf. Dann bekommt nicht eine Untersuchungseinheit den Rang 1 und die andere den Rang 2, sondern beide den Rang 1.5. Wenn es zu viele Rangbindungen gibt, reduziert das jedoch die Aussagekraft des Tests.
6. Beispiel U-Test
Der Lehrer Herr Mustermann teilt sein Klasse zufällig in zwei Gruppen auf. Die eine Gruppe lernt ein neues Thema auf Basis von Wikipedia, die andere Gruppe mit dem üblichen Lehrbuch. Nach der Lernphase prüft Lehrer Mustermann das Gelernte in einem Test mit Noten, die nur ordinalskaliert sind.
Noten Gruppe A: 2.3 2.0 1.7 2.3 2.7 3.0 2.3 2.3
Noten Gruppe B: 2.3 3.0 3.7 3.0 2.7 3.3 3.0 3.0
Arbeitsschritte, wenn Sie per Hand den U-Test berechnen:
- Sortierung aller Werte gruppenübergreifend in aufsteigender Folge (Spalte Wert)
- Zuweisung von Rängen für beide Gruppen gemeinsam– bei mehreren gleichen Werten (Rangbindung) durchschnittliche Ränge (Spalte Rang)
- Summierung der Ränge je nach Gruppe
| Wert | Gruppe | Rang | (Ränge aus A) | (Ränge aus B) |
|---|---|---|---|---|
| 1.7 | A | 1 | 1 | |
| 2.0 | A | 2 | 2 | |
| 2.3 | A | 5 | 5 | |
| 2.3 | A | 5 | 5 | |
| 2.3 | A | 5 | 5 | |
| 2.3 | A | 5 | 5 | |
| 2.3 | B | 5 | 5 | |
| 2.7 | A | 8.5 | 8.5 | |
| 2.7 | B | 8.5 | 8.5 | |
| 3.0 | A | 12 | 12 | |
| 3.0 | B | 12 | 12 | |
| 3.0 | B | 12 | 12 | |
| 3.0 | B | 12 | 12 | |
| 3.0 | B | 12 | 12 | |
| 3.3 | B | 15 | 15 | |
| 3.7 | B | 16 | 16 |
Rangsumme Gruppe A: 43.5
Rangsumme Gruppe B: 92.5
Sie sehen, dass die Rangsummen in diesem Beispiel recht unterschiedlich ausfallen. Das spricht dafür, dass sich die zentrale Tendenz der beiden Gruppen deutlich unterscheidet. Ist dieser Unterschied signifikant? Für diese Frage benötigt man die Teststatistik, die im nächsten Abschnitt dargestellt wird.
7. Ergebnisse des Tests
Normalerweise überlässt man die Berechnung statistischer Tests einem Statistikprogramm, z.B. SPSS. Wenn Sie ausnahmsweise aber dennoch per Hand das Testergebnis berechnen müssen, gibt es einen wesentlichen Tipp zur Vereinfachung: Berechnen Sie den Wilcoxon-Rangsummentest. Er führt zu exakt den gleichen Ergebnissen wie der U-Test, aber die Prüfgröße ist leichter zu berechnen.
Die Teststatistik beim Wilcoxon-Rangsummentest ist nämlich einfach die kleinere der Rangsummen der beiden Gruppen. Im Beispiel oben also Ws = 43.5. Wie stellt man auf Basis der berechneten Prüfstatistik fest, ob der Wert signifikant ist?
Für geringe Stichprobenumfänge gibt es exakte Verteilungswerte für die Prüfstatistik. Kritische Werte zum U-Test kann man in entsprechenden Tabellen nachsehen, z.B. in dieser Tabelle für den U-Test bzw. in dieser Tabelle für den Wilcoxon-Rangsummentest, der bei manueller Testung empfehlenswert ist.
Für größere Stichprobenumfänge ist die Prüfstatistik näherungsweise normalverteilt, so dass man sie in einen z-Wert umrechnet und dann mit den entsprechenden Werten der Normalverteilung vergleicht. Wie genau man diese Umrechnung vornimmt, können Sie z.B. im Beitrag von Nachar (2008) nachlesen, dort am inhaltlich äquivalenten Beispiel des U-Tests.
Sie können frühestens ab N = 12 von einer näherungsweisen (asymptotische) Normalverteilung ausgehen (Gibbons & Chakraborti, 2003, S. 273), wobei außerdem beide Gruppen jeweils mindestens 6 Einheiten aufweisen sollten. Andere Autoren empfehlen jedoch, erst ab einem wesentlich größeren N mit den asymptotischen Werten zu rechnen, Field (2013) beispielsweise ab N = 50.
In der Praxis machen Sie das alles normalerweise nicht per Hand, sondern lassen ein Statistikprogramm diese Arbeit für Sie ausführen. SPSS weist bei kleinen Stichproben beides aus: den exakten Wert und den asymptotischen Wert; bei großen Stichproben standardmäßig nur den asymptotischen Wert. Bei kleinen Stichproben sollten Sie den exakten Wert verwenden. Das gilt vor allem auch, wenn sich exakte Signifikanz und asymptotische Signifikanz deutlich unterscheiden.
Für das o.g. Beispiel berechnet SPSS folgende Werte:
Asymptotische Signifikanz p = .008
Exakte Signifikanz p = .007
Da beide Gruppen je mindestens 6 Einheiten aufweisen, können Sie die asymptotische Signifikanz heranziehen. Mit einem Wert von < .05 unterscheiden sich hier die Mediane signifikant.
8. Wie ermitteln Sie die Effektstärke?
Die Effektstärke des U-Tests berechnen Sie aus dem asymptotischen Wert, der auf der Normalverteilung basiert. Für die Berechnung der asymptotischen Signifikanz wird ein z-Wert berechnet, der im SPSS-Output auch standardmäßig mit ausgewiesen wird.
Und z-Werte können Sie leicht nach folgender Formel in das Effektstärkenmaß r umrechnen:
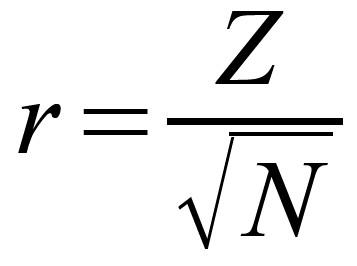
Dabei ist N die gesamte Stichprobengröße über beide Gruppen zusammen. Das Vorzeichen von Z ist hierbei inhaltlich wenig aussagefähig, so dass man normalerweise den positiven Wert berichtet, auch wenn Z negativ sein sollte.Um dieses Problem zu vermeiden, könnte man die Gruppennummern beim Vergleich so zuordnen, dass ein positiver z-Wert resultiert.
Beispiel von oben:
z-Wert = - 2.654
Daraus errechnet sich mit N = 16 eine Effektstärke von r = .66.
Diesen Wert können Sie dann in Relation zu den Effektstärkekonventionen nach Cohen (1992) setzen. Danach ist ein Wert von:
r = .50 ein starker Effekt,
r = .30 ein mittlerer Effekt,
r = .10 ein schwacher Effekt.
Im Beispiel lag also ein starker Effekt vor.
9. Welche Nullhypothese hat der Test?
Die Nullhypothese des Mann-Whitney U-Tests lautet: Beide Gruppen entstammen der gleichen Grundgesamtheit. Das bedeutet insbesondere: Die Nullhypothese lautet nicht: Beide Gruppen haben den gleichen Mittelwert oder Median!
Das sieht jetzt nach einem Widerspruch aus, denn oben wurde dieser Test als ein Test für zwei Mittelwerte bzw. Mediane vorgestellt. Wie kann das sein?
Man kann mit dem Test tatsächlich nur indirekt Unterschiede von Mittelwerten bzw. Medianen nachweisen. Denn was bedeutet es, dass zwei Gruppen aus der gleichen Grundgesamtheit stammen?
Dafür müssen vor allem drei Dinge zutreffen:
- Die Mittelwerte/Mediane sind in beiden Gruppen gleich.
- Die Streuungen sind in beiden Gruppen gleich.
- Die Verteilungen haben in beiden Gruppen die gleiche „Form“ (etwas unwissenschaftlich formuliert, trifft es aber inhaltlich ganz gut).
Nur wenn alle drei Bedingungen erfüllt sind, gilt die Nullhypothese. Wenn auch nur eine einzige dieser Bedingungen nicht erfüllt ist, kann die Nullhypothese vom Test verworfen werden. Folge: Der Test wird ggf. signifikant.
Damit kann man Unterschiede der Mittelwerte nur indirekt nachweisen:
Sie haben ein signifikantes Ergebnis beim U-Test. Damit wissen Sie, dass sich die Verteilung beider Gruppen unterscheidet. Um daraus auf unterschiedliche Mittelwerte zu schließen, brauchen Sie zwei zusätzliche Informationen: Dass die Streuungen in beiden Gruppen gleich sind und auch die Form der Verteilung gleich ist. Denn dann bleibt als Erklärung für die unterschiedliche Verteilung nur noch übrig, dass sich die Mittelwerte unterscheiden.
Und das führt uns direkt zu den Voraussetzungen dieses Tests.
10. Was sind die Voraussetzungen des U-Tests?
Auch nonparametrische Verfahren sind nicht völlig frei von Voraussetzungen. Die Voraussetzungen beim Mann-Whitney Test sind vor allem die drei folgenden:
Voraussetzung 1:
Beide Gruppen haben die gleiche Streuung (Varianzhomogenität im Fall von intervallskalierten Daten).
Voraussetzung 2:
Für beide Gruppen hat die Verteilung die gleiche Form. Man kann also beispielsweise mit dem U-Test schiefe Verteilungen testen, aber es muss dann die Verteilung in beiden Gruppen rechtsschief sein oder in beiden Gruppen linksschief.
Voraussetzung 3:
Alle Untersuchungseinheiten innerhalb einer Gruppe sind unabhängig voneinander. Das gilt eigentlich für alle Gruppenvergleiche, also auch für ANOVA, t-Test usw.
Insbesondere die ersten beiden Voraussetzungen müssen Sie gesondert vorab prüfen, wenn Sie den Test durchführen, sonst kann er zu falschen Ergebnissen führen. Je stärker die Voraussetzungen verletzt sind, desto eher wird der Test signifikant, auch wenn gar keine Mittelwertunterschiede vorliegen!
Außerdem müssen natürlich zwei unabhängige Stichproben vorliegen, denn nur dafür ist dieser Test gedacht. Für den nonparametrischen Vergleich von zwei abhängigen (verbundenen) Stichproben gibt es andere Tests, den Wilcoxon-Vorzeichen-Rangtest und den Vorzeichentest. Und die abhängige Variable muss mindestens ordinalskaliert und theoretisch kontinuierlich sein.
11. Wie prüfen Sie die Voraussetzungen?
Sie können die o.g. Voraussetzungen 1 und 2 für den Mann-Whitney Test in einem einzigen Schritt überprüfen. Dazu gibt es verschiedene Möglichkeiten.
Am besten erstellen Sie dazu einen Q-Q-Plot, mit dem die Verteilungen für beide Gruppen miteinander verglichen werden. Der Q-Q-Plot sollte möglichst nahe an der Diagonalen liegen; je weiter sich der Plot von der Diagonalen entfernt, desto stärker ist die Verletzung der Voraussetzungen.
Nur ist in SPSS leider ein Q-Q-Plot zwar zum Vergleich einer Verteilung mit der Normalverteilung implementiert, nicht jedoch so ohne weiteres zum Vergleich der Verteilung von zwei Gruppen miteinander. Um dennoch dort einen Q-Q-Plot erstellen zu können, gibt es als Ergänzung für SPSS in der SPSS-Entwicklungsumgebung ein kleines Zusatzprogramm zum Q-Q-Plot zum Download, für das man allerdings auch noch weitere Plug-Ins benötigt. Wirklich lohnen tut sich dieser Aufwand aus meiner Sicht nur, wenn man häufiger derartige Auswertungen erstellt.
Sie können die Voraussetzungen des Tests aber auch „per Hand“ prüfen, indem Sie für beide Gruppen je ein Histogramm erstellen, was standardmäßig in SPSS möglich ist. Und diese beiden Histogramme vergleichen Sie dann miteinander hinsichtlich Form der Verteilung und Streuung.
Beispiel unterschiedliche Form der Verteilung:
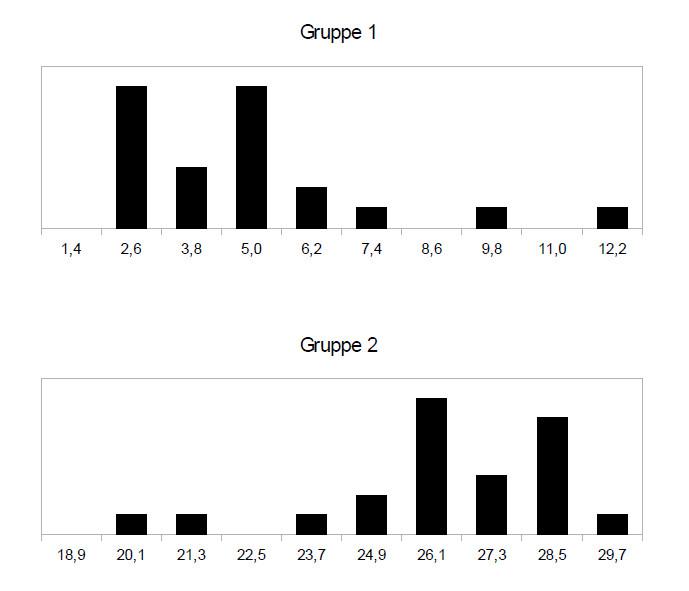
In diesem Beispiel können Sie am Maßstab auf der x-Achse sehen, dass die Streuung beider Gruppen ähnlich ist (Spannweite zwischen kleinsten und größten Wert jeweils ca. 10) – die Verteilungen sind vergleichbar „breit“. Aber die Form beider Verteilungen unterscheidet sich deutlich, Gruppe 1 ist rechtsschief (=links-steil), Gruppe 2 ist linksschief (rechts-steil). Damit ist hier eine notwendige Voraussetzung für den Test nicht erfüllt und Sie dürften den U-Test nicht anwenden, um die Mittelwerte zu vergleichen.
Die anderen o.g. Voraussetzungen (insbesondere: unabhängige Stichproben) prüfen Sie natürlich, bevor Sie überhaupt anfangen mit den Datenauswertungen. Denn sonst kommt der Test grundsätzlich nicht in Frage.
12. Und wenn die Voraussetzungen nicht erfüllt sind?
Wenn das Problem in sehr ungleichen Varianzen liegt, könnte eine Datentransformation der abhängigen Variable weiter helfen. Eine Transformation hat das Ziel, die Verteilung der abhängigen Variable an die Normalverteilung anzunähern. Und diese transformierten Daten erfüllen dann möglicherweise die Voraussetzungen für den t-Test. Und anders als beim U-Test gibt es für den Zwei-Stichproben t-Test auch eine Variante für unterschiedliche Varianzen zwischen den Gruppen. Mehr zu diesem Vorgehen können Sie im Beitrag von Osborne (2010) nachlesen.
Wenn ein t-Test aber keinesfalls in Frage kommt, weil die Daten nur ordinalskaliert sind, gibt es zum einen die Möglichkeit einer Transformation und der anschließenden Durchführung des U-Tests mit den transformierten Daten. Zum anderen können Sie einen Median-Test durchführen, der nicht von der Form der Verteilungen abhängig ist. Allerdings weist er eine sehr niedrige Teststärke auf: Es ist also sehr schwierig, dort signifikante Ergebnisse zu erzielen.
13. U-Test für gerichtete Hypothesen
Standardmäßig werden von SPSS beim U-Test zweiseitige Tests berichtet. Wenn Sie mit dem U-Test einseitig testen wollen, geht das aber auch. Wenn Sie den Test mit der Option „exakter Test“ aufrufen, werden auch einseitige p-Werte ausgewiesen, siehe Aufruf in SPSS.
14. Aufruf in SPSS
Mit folgender SPSS-Syntax prüfen Sie die Voraussetzungen und rufen den Test auf:
/*Vorauswertungen: Median, Histogramm je Gruppe */
SORT CASES BY Gruppe.
SPLIT FILE SEPARATE BY Gruppe.
FREQUENCIES VARIABLES=Wert
/STATISTICS=MEDIAN
/HISTOGRAM
/ORDER=ANALYSIS.
SPLIT FILE OFF.
/*eigentlicher U-Test:*/
NPAR TESTS
/M-W= Wert BY Gruppe(1 2)
/MISSING ANALYSIS.
Wenn Sie eine gerichtete Hypothese haben und daher den einseitigen Test aufrufen wollen, dann tun Sie das so:
/*eigentlicher U-Test (einseitig bzw. exakte Werte):*/
NPAR TESTS
/M-W= Wert BY Gruppe(1 2)
/MISSING ANALYSIS
/METHOD=EXACT TIMER(5).
Diesen zweiten Aufruf nutzen Sie auch dann, wenn Sie trotz größerem N den exakten Wert ausweisen wollen.
Den Aufruf des Tests aus dem Menü finden Sie in dieser pdf-Datei:
Aufruf Mann-Whitney U-Test SPSS (pdf)
Erklärt ist jeweils der klassische Aufruf („Alte Dialogfelder“), weil die neuere Variante zwar die gleichen p-Werte ergibt, jedoch bei den Teststatistiken einige nicht immer nachvollziehbare Werte ausgibt.
15. Interpretation der SPSS Auswertung
Beispiele und Übungsaufgaben zur Interpretation der SPSS Auswertung finden Sie in folgender pdf-Datei:
Übungen Interpretation SPSS-Output Mann-Whitney U-Test (pdf)
16. Testergebnisse berichten
Eine Ergebnisdarstellung für den U-Test könnte beispielsweise so aussehen:
„Die Werte in Gruppe B (Mdn = 20.0) waren signifikant größer als in Gruppe A (Mdn = 13.0), U = 13.50, z = 2.59, p = .009, r = .60. Nach Cohen (1992) lag damit ein starker Effekt vor.“
Genannt werden also die beiden Mediane (oder Mittelwerte – siehe unten), die Teststatistik (U oder Ws), der z-Wert und r als Effektstärke sowie die Einordnung der Effektstärke gemäß Cohen.
17. Median oder arithmetisches Mittel?
Welchen Wert für die zentrale Tendenz sollte man mit dem U-Test berichten: das arithmetische Mittel oder den Median?
Wenn die abhängige Variable nur ordinalskaliert ist, muss der Median berichtet werden. Das arithmetische Mittel ist dann nicht definiert.
Wenn Sie den Test aber durchführen, weil die Normalverteilungsannahme einer intervallskalierten Variable nicht erfüllt ist, dann gibt es für beide Varianten gute Argumente: Als Rangtest passt der Median eher zum durchgeführten U-Test (Field, 2013), aber für intervallskalierte Daten ist das arithmetische Mittel die passendere zentrale Tendenz.
Mit dem Median ist man aber vermutlich auf der sichereren Seite.
18. Quellen
Cohen, J. (1992). A power primer. Psychological bulletin, 112, 155-159. doi: 10.1037/0033-2909.112.1.155
Field, A. (2013). Discovering statistics using IBM SPSS statistics: And sex and drugs and rock 'n' roll (4th edition). Los Angeles, CA: SAGE.
Gibbons, J. D., & Chakraborti, S. (2003). Nonparametric statistical inference (4. ed.). New York, NY: Marcel Dekker.
Nachar, N. (2008). The Mann-Whitney U: A test for assessing whether two independent samples come from the same distribution. Tutorials in Quantitative Methods for Psychology, 4, 13–20. doi: 10.20982/tqmp.04.1.p013
Osborne, J. W. (2010). Improving your data transformations: Applying the Box-Cox transformation. Practical Assessment, Research & Evaluation, 15. Retrieved from: http://pareonline.net/getvn.asp?v=15&n=12