Datenaufbereitung Mehrebenenanalyse mit SPSS:
Daten vom wide-Format ins long-Format transformieren
Arndt Regorz, Dipl. Kfm. & MSc. Psychologie, 17.09.2023
Eine Voraussetzung für eine Mehrebenenanalyse (linear mixed effects model, hiearchisches lineares Modell) in SPSS ist, dass die Daten im long-Format vorliegen. Gerade Längsschnittdaten werden aber häufiger zunächst im wide-Format gespeichert und müssen entsprechend transformiert werden, bevor sie ausgewertet werden können. Dieses Tutorial zeigt, wie das in SPSS funktioniert.
1. Was sind wide-Format und long-Format?
In diesem kleinen Beispiel liegen die Daten für eine Längsschnitt-Untersuchung mit zwei messwiederholten Variablen (UV, AV) und drei Messzeitpunkten vor. Beispiel für das wide-Format:

Man sieht, dass es pro untersuchter Person eine Zeile gibt und alle messwiederholten Daten nebeneinander in dieser Zeile stehen.
Für das von der Mehrebenenanalyse benötigte long-Format brauchen wir jedoch eine Zeile pro Messzeitpunkt. In unserem Beispiel mit drei Messzeitpunkten müssen jetzt also pro Person drei Zeilen erstellt werden, in denen jeweils die Personenvariablen stehen (im Beispiel: fallnr, alter, geschlecht) und die Werte der messwiederholten Variablen für den konkreten Messzeitpunkt. Und zusätzlich wird noch eine Variable benötigt, die den Messzeitpunkt codiert.
2. Umstrukturieren vom wide-Format in das long-Format
Die Umstrukturierung vom wide-Format in das long-Format kann man in SPSS über das Menü oder über Syntax vornehmen.
Den entsprechenden Menüpunkt finden Sie in SPSS unter:
Daten-Umstrukturieren
Man muss dort jedoch eine Vielzahl von Einzelentscheidungen treffen und das ist m.E. recht fehlerträchtig. Daher empfehle ich, die Umstrukturierung stattdessen über SPSS-Syntax vorzunehmen. Die dazu gehörige Syntax ist relativ klar strukturiert.
Auf Basis vom o.g. Beispiel:
VARSTOCASES
/MAKE UV FROM uv_t1 uv_t2 uv_t3
/MAKE AV FROM av_t1 av_t2 av_t3
/INDEX=MZP "Messzeitpunkt"(3)
/KEEP=fallnr alter geschlecht
/NULL=KEEP.
Erklärung der einzelnen Syntaxzeilen:
VARSTOCASES
Den Funktionsnamen kann man sich leicht merken, VARS TO CASES, also „Variablen zu Fällen“ - denn genau das bedeutet die Transformation wide- zu long-Format.
/MAKE UV FROM uv_t1 uv_t2 uv_t3
Damit wird angegeben, in welche neue Variable die Werte der bisherigen Variablen uv_t1, uv_t2 und uv_t3 geschrieben werden. Der Name „UV“ ist hier frei von mir vergeben, da hätte man auch irgendeinen anderen Namen nehmen können. Die Namen „uv_t1“, „uv_t2“, „uv_t3“ sind Variablen aus dem bisherigen Datensatz.
Analog auch in der Folgezeile für AV. Und wenn Sie noch mehr Variablen haben, die zu verschiedenen Messzeitpunkten gemessen werden, ergänzen Sie einfach weitere Zeilen mit /MAKE... nach dem gleichen Schema.
/INDEX=MZP "Messzeitpunkt"(3)
Mit /INDEX wird eine Indexvariable angelegt, die jetzt die verschiedenen Messzeitpunkte kennzeichnet. Den Namen MZP habe ich frei gewählt, ebenso die Variablenbeschreibung "Messzeitpunkt", da könnten Sie auch einen anderen Namen wählen (z.B. „Woche“, wenn es eine Wochenbuchstudie mit einer Messung pro Woche wäre, u.ä.)
Die (3) gibt an, dass es pro Person drei Messzeitpunkte gibt.
/KEEP=fallnr alter geschlecht
Hiermit wird angegeben, dass die Variablen fallnr, alter und geschlecht im neuen Datensatz erhalten bleiben sollen
/NULL=KEEP.
Diese Zeile steuert, was passiert, wenn für einen Messzeitpunkt alle Variablenwerte missings sind (wenn also die Person zu diesem Zeitpunkt nicht geantwortet hat). Mit /NULL=KEEP. wird dafür gesorgt, dass trotzdem eine Zeile im neuen Datensatz erzeugt wird, eine Zeile mit lauter fehlenden Werten. Alternativ könnte man auch /NULL = DROP. angeben, dann würden für Messzeitpunkte ohne Daten gar keine Zeilen erstellt.
Bitte beachten Sie den Punkt ganz am Ende des Befehls (nur in dieser letzten Zeile darf und muss am Ende der Zeile ein Punkt stehen, nicht bei einer der vorherigen Zeilen).
Wenn wir diese Syntax auf den o.g. Beispieldatensatz anwenden, dann erhalten wir:
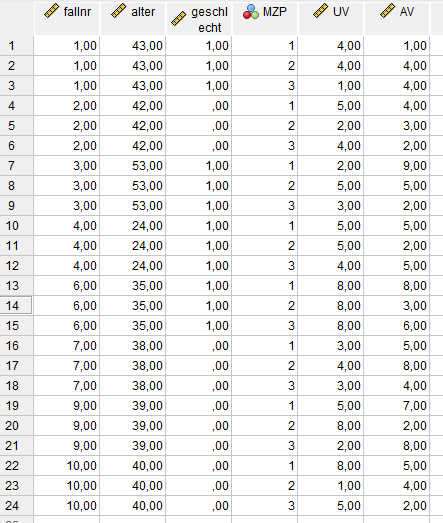
Und mit dieser Datenstruktur kann man Mehrebenenanalysen in SPSS durchführen (ggf. könnte man noch das Datenformat vom Messzeitpunkt auf metrisch umstellen, wenn die Abstände zwischen den Messzeitpunkten gleich sind).