Binär logistische Regression mit SPSS
Arndt Regorz, Dipl. Kfm. & M.Sc. Psychologie, Stand: 31.05.2020
Sie möchten eine binäre (dichotome) Variable mit einer Regression vorhersagen? Dann bietet sich die binär logistische Regression an. Dieses Tutorial zeigt Ihnen den Aufruf und die Interpretation des SPSS-Output am Beispiel einer hierarchischen logistischen Regression, also mit Einschluss der Prädiktoren in mehreren Schritten (z.B. im ersten Schritt die Kontrollvariablen und im zweiten Schritt den oder die inhaltlich interessanten Prädiktoren). Das Tutorial basiert auf SPSS Version 26.
Inhalt
1. YouTube-Video-Tutorial
(Hinweis: Mit Anklicken des Videos wird ein Angebot des Anbieters YouTube genutzt.)
2. Aufruf aus dem Menü
Sie finden den Aufruf in SPSS unter dem Pfad: Analysieren - Regression - binär logistische
Hier finden Sie die Parameter in der Hauptdialogbox:
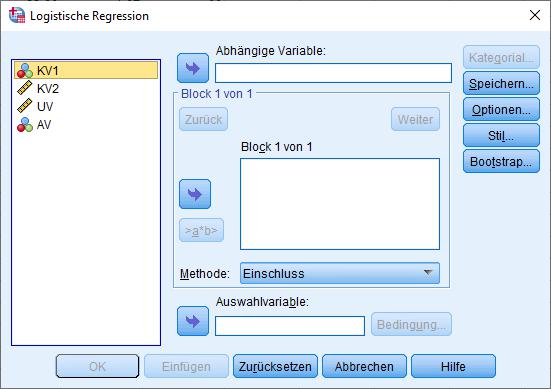
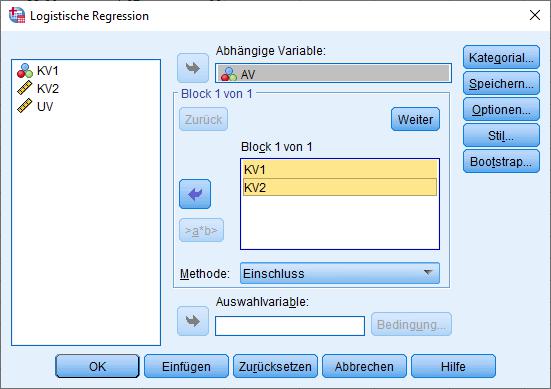
Bei einer hierarchischen logistischen Regression (=Einschluss der Prädiktoren in mehreren Schritten) klicken Sie dann auf „Weiter“ und bekommen das Fenster für die Prädiktoren des nächsten Schritts:
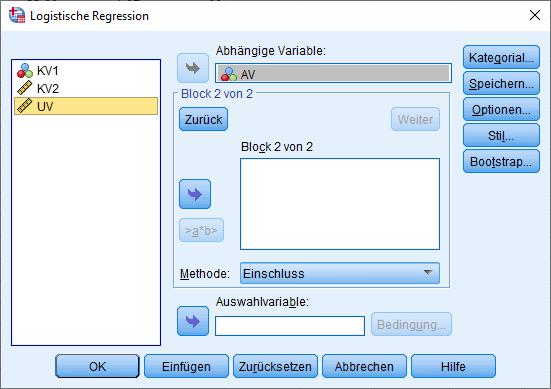
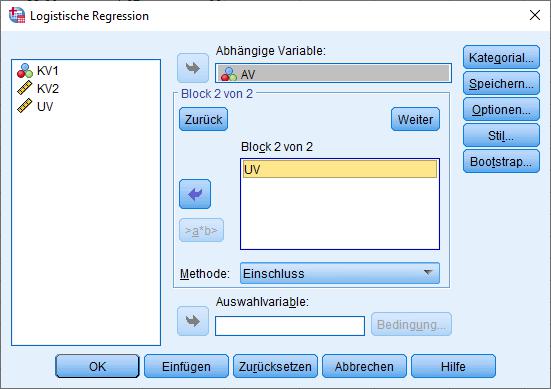
Anschließend wechseln Sie zu den Optionen und wählen z.B.:
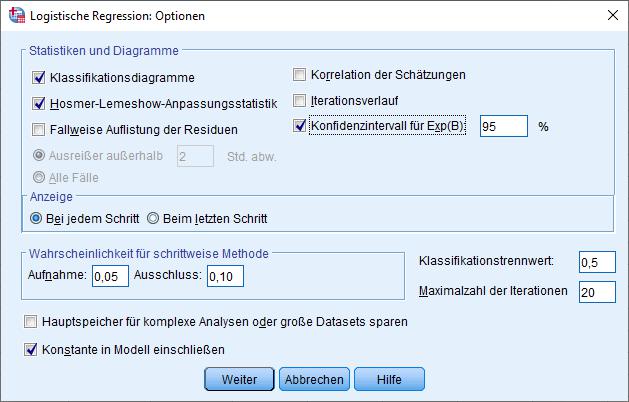
Wenn Sie noch diagnostische Informationen über Residuen und Ausreißer möchten, sollten Sie sich dazu das gute Skript von der Uni Trier durchlesen (Baltes-Götz, 2012).
3. Aufruf mit Syntax
Die gleiche Auswertung wie im vorherigen Abschnitt können Sie auch mit der folgenden Syntax aufrufen:
(für AV, KV1, KV2, UV müssten Sie dann Ihre eigenen Variablennamen einsetzen)
LOGISTIC REGRESSION VARIABLES AV
/METHOD=ENTER KV1 KV2
/METHOD=ENTER UV
/CLASSPLOT
/PRINT=GOODFIT CI(95)
/CRITERIA=PIN(0.05) POUT(0.10) ITERATE(20) CUT(0.5).
4. Interpretation logistische Regression
Nachfolgend sehen Sie kommentierte Auszüge aus dem SPSS-Output zur hierarchischen logistischen Regression, erstellt mit den o.g. Aufrufen aus Menü oder Syntax. Es handelt sich also um eine binäre logistische Regression, in der im ersten Schritt zwei Kontrollvariablen (KV1, KV2) eingeschlossen worden sind, im zweiten Schritt dann die eigentliche unabhängige Variable (UV). Hinsichtlich der abhängigen Variable spreche ich im Folgenden etwas vereinfachend davon, ob das Ereignis eintritt (AV=1) oder nicht (AV=0); man kann aber natürlich die logistische Regression auch für andere Zwecke einsetzen, z.B. zur Vorhersage des Vorliegens einer Eigenschaft (AV=1) oder nicht (AV=0) u.ä.
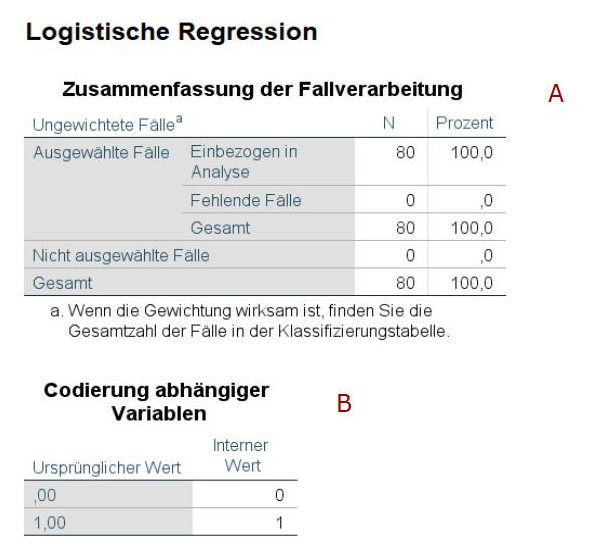
Der Output beginnt mit einer Tabelle „Zusammenfassung der Fallverarbeitung“ (A). Dort sehen Sie, wie viele Fälle am Ende in der Berechnung zur logistischen Regression berücksichtigt worden sind.
Darunter folgt eine Tabelle „Codierung abhängiger Variablen“ (B). Da im vorliegenden Beispiel bereits im Datensatz die abhängige Variable mit 0 und 1 codiert war, unterscheiden sich hier der ursprüngliche Wert und der interne Wert nicht voneinander.
Block 0

Darauf folgen im Output die Ergebnisse für Block 0 (C). Das ist ein Modell, in dem noch gar keine Prädiktoren berücksichtigt worden sind. Daher ist es für mich relativ wenig interessant.
Block 1
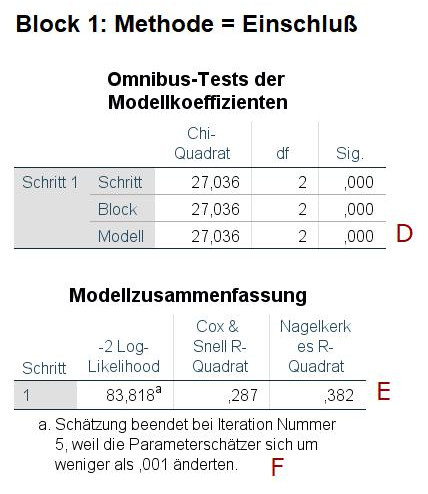
Die interessanten Ergebnisse beginnen mit Block 1. Das ist in unserem Beispiel der Block, in dem lediglich die beiden Kontrollvariablen in das Modell eingeschlossen worden sind.
Im Block 1 sind alle drei Zeilen der Tabelle „Omnibus-Test der Modellkoeffizienten“ gleich. Der Test bei Modell (D) prüft, ob sich dieses Modell signifikant von gar keinem Modell unterscheidet. Das ist hier der Fall, also erklären die beiden Kontrollvariablen zusammen signifikant die abhängige Variable.
Bei der Tabelle zur Modellzusammenfassung gibt es mehrere interessante Informationen. Als Effektstärke für das Modell insgesamt (später kommen wir noch zu einem weiteren Effektstärkemaß) ist aus meiner Sicht am besten zu interpretieren Nagelkerkes R-Quadrat (E). Damit wurde versucht, für die logistische Regression das R2 der multiplen Regression ungefähr nachzubauen. Im Gegensatz zu Cox&Snell weist Nagelkerkes R-Quadrat den gleichen Wertebereich auf wie das klassische R2. Jedoch ist die Interpretation nicht identisch – man darf also hier aus einem Wert von .382 für Nagelkerke nicht schließen, dass die beiden Kontrollvariablen 38.2% der Varianz der abhängigen Variable erklären (wie es bei der gewöhnlichen multiplen Regression für das R2 wäre).
Sehr wichtig ist noch die Fußnote zu dieser Tabelle (F). Nur wenn da steht, dass die Schätzung beendet wurde, weil sich die Schätzungen bei weiteren Iterationen nur noch sehr wenig änderten, kann man die Ergebnisse zuverlässig interpretieren. Es kann auch der Fall eintreten, dass das Modell nicht konvergiert, es also zu keiner stabilen Schätzung kommt. Dann wäre es gefährlich, die anderen Daten des Output inhaltlich zu interpretieren.
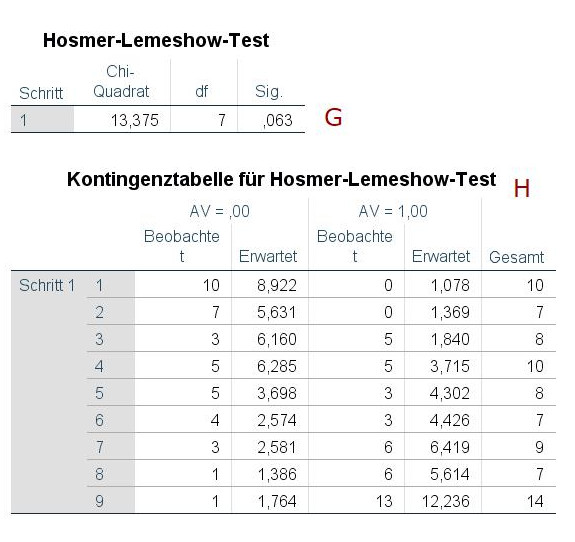
Als nächstes folgen zwei Tabellen zum Test nach Hosmer und Lemeshow. Damit wird getestet, wie gut (bzw. genauer wie schlecht) die Daten zum geschätzten Modell passen. Die obere Tabelle (G) zeigt den eigentlichen Test, die untere Tabelle (H) die Daten, mit denen dieser Test durchgeführt wird. Dieser Test teilt die Beobachtungen in eine Reihe von Gruppen auf und vergleicht für jede dieser Gruppen die vorhergesagten Beobachtungen mit den tatsächlichen Beobachtungen. Auf Basis dieses Vergleichs wird dann ein Chi-Quadrat-Test durchgeführt, dessen Ergebnisse in (G) berichtet werden. Entscheidend ist hier: Wenn es signifikant wird, gibt es eine signifikante Abweichung zwischen Modell und Daten. Wir wünschen uns hier also ein nicht-signifikantes Ergebnis. (Im Beispiel ist es gerade eben nicht signifikant.)
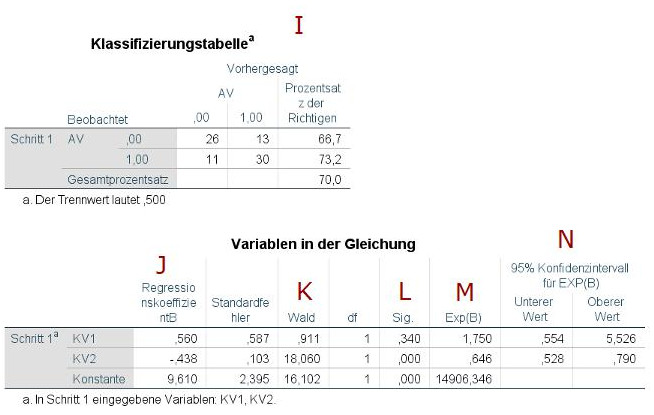
Die Klassifizierungstabelle (I) zeigt an, wie viele der Beobachtungen richtig klassifiziert worden sind. Im Beispiel wurden 26 korrekt der Gruppe 0 zugeordnet und 30 korrekt der Gruppe 1. Es wurden 13 fälschlicherweise der Gruppe 1 zugeordnet (die tatsächlich zu Gruppe 0 gehörten) und 11 fälschlicherweise der Gruppe 0 (obwohl sie zu Gruppe 1 gehören). Rechts wird jeweils der Prozentsatz der richtig zugeordneten Beobachtungen angegeben.
Die darauf folgende Tabelle „Variablen in der Gleichung“ ist im Grunde das Herzstück des Output. Hier werden für die verschiedenen Prädiktoren eines Regressionsschritts die Einzelergebnisse ausgegeben. Sie entspricht ungefähr der „Koeffizienten“-Tabelle der gewöhnlichen multiplen Regression.
In der ersten Spalte (J) sind die Regressionskoeffizienten dargestellt. Die Interpretation ist hier leider deutlich schwieriger als bei der gewöhnlichen multiplen Regression. Bei der logistischen Regression zeigt das Regressionsgewicht an, um wie viele Logit-Einheiten sich das Kriterium ändert, wenn sich der Prädiktor um eine Einheit erhöht. Was aber schon vergleichbar ist, ist die Bedeutung des Vorzeichens. Bei positivem Vorzeichen besteht ein positiver Zusammenhang zwischen dem Prädiktor und der Wahrscheinlichkeit, dass das untersuchte Ereignis (Kriterium = 1) eintritt, bei negativem Vorzeichen ein negativer Zusammenhang. Ob das jedoch auch signifikant ist, sehen wir in der fünften Spalte (L).
Die Wald-Statistik (K) testet, ob der Prädiktor das Ereignis signifikant vorhersagt. Berechnet wird sie nach der Literatur in der Regel dadurch, dass das Regressionsgewicht durch den Standardfehler dividiert wird. SPSS weicht davon etwas ab, indem dieses Quotient noch quadriert wird. Auf Basis dieser Wald-Statistik wird dann der p-Wert (L) berechnet. Für die Wald-Statistik ist noch wichtig zu wissen, dass diese manchmal verzerrt sein kann – der Chi-Quadrat-Test für den Omnibus-Test der Modellkoeffizienten hat dieses Problem jedoch nicht.
Die Effektstärke für einen einzelnen Prädiktor bei der logistischen Regression findet sich unter Exp(B) (M), diese wird auch Odds-Ratio (OR) genannt. Positive Effekte sind hier größer als 1, negative Effekte kleiner als 1. Wenn Sie mehr über die genaue Interpretation von Odds-Ratios lesen wollen, empfehle ich das Tutorial der UZH (Universität Zürich, n.d.).
Bei Effektstärken stellt sich meistens noch die Frage, ob es sich ggf. um einen schwachen, mittleren oder großen Effekt handelt. Das ist bei Odds-Ratios gar nicht so einfach zu beantworten, da dies hier nicht nur von der Odds-Ratio selbst abhängt, sondern auch von der Baserate, also von der Häufigkeit des Ereignisses unter Gültigkeit der Nullhypothese. Aus der Literatur (Chen, Cohen, & Chen, 2010; Ferguson, 2009; Wuensch, 2019) kann man jedoch zumindest einige grobe Bandbreiten für Effekte ableiten:
- Schwacher Effekt: Ab einer OR von ca. 1.5 - 2
- Mittlerer Effekt: Ab einer OR von ca. 3.0 – 3.5
- Großer Effekt: Ab einer OR von ca. 4.0 – 7.0
Bei Odds-Ratios von unter 1 (also bei negativen Effekten) muss man noch die äquivalente Effektstärke für einen positiven Effekt bestimmen, um die o.g. Bandbreiten darauf anwenden zu können. Das tut man, indem man den Kehrwert bildet.
Beispiel:
OR = 0.50
Durch Bilden des Kehrwerts 1 / 0.50 = 2.00 bekommt man eine Effektgröße, die man mit den o.g. Werten vergleichen kann. Hier handelt es sich also im Beispiel um einen schwachen Effekt.
Zuletzt betrachten wir noch die Konfidenzintervalle (N). Hier ist die Besonderheit, dass gar kein Effekt bei Odds-Ratios anders als sonst von der Regression gewohnt nicht einem Wert von 0 sondern einem Wert von 1 entspricht. Ein Konfidenzintervall zeigt also dann ein signifikantes Ergebnis an, wenn es die 1 nicht einschließt, wie in der Beispieltabelle für die KV2. Bei der KV1 hingegen ist die 1 im Konfidenzintervall enthalten, so dass KV1 kein signifikanter Prädiktor ist – was jeweils den Ergebnissen des Signifikanztests (L) entspricht.
Das sich im Output anschließende Klassifizierungsdiagramm ist hier noch nicht abgedruckt, das betrachten wir bei Schritt 2 für das vollständige Modell.
Block 2
Damit kommen wir zum Block 2, also dem Schritt nach Einschluss der eigentlich interessierenden unabhängigen Variable.

Ab dem zweiten Block wird die Tabelle zum Omnibus-Test interessanter. Jetzt sind nicht mehr alle Zeilen gleich. Relevant sind für unseren Fall die beiden Zeilen Block und Modell.
Zunächst zu Modell (P). Dies ist der Test, ob alle Prädiktoren des vorliegenden Modells aus diesem Regressionsschritt zusammen signifikant die Gruppenzugehörigkeit erklären, in unserem Beispiel also beide Kontrollvariablen und die unabhängige Variable zusammen. Das entspricht ein wenig dem, was Sie bei der gewöhnlichen multiplen Regression bei SPSS in der Tabelle ANOVA finden.
Für uns bei der hierarchischen Regression noch interessanter ist jedoch die Angabe zu Block (O) . Das ist der Test, ob der (oder die) in diesem Block zusätzlich aufgenommene Prädiktor einen signifikanten zusätzlichen Erklärungsbeitrag leistet. Und genau das ist es, was wir in der Regel bei einer hierarchischen Regression wissen möchten. Das entspricht ein wenig dem, was Sie bei der gewöhnlichen multiplen Regression in der Tabelle Modellzusammenfassung finden (also dem dortigen F-Test für die Änderung in R2).
In unserem Beispiel sehen wir, dass die zusätzliche Aufnahme der unabhängigen Variable in das Modell einen signifikanten Erklärungsbeitrag leistet, X2 = 27.63, p < .001. Und dieser Test hat gegenüber dem Test des einzelnen Regressionsgewicht den Vorteil, dass er anders als der dortige Wald-Test nicht so sehr unter möglichen Verzerrungen leidet. Insofern ist dieser Test für unsere vorliegendes Beispiel die entscheidende Information.
Die Tabelle Modellzusammenfassung ist hier ebenso zu interpretieren wie in Block 1.
Die Klassifizierungstabelle ist hier im Tutorial nicht noch einmal abgebildet, auch dort ist die Interpretationslogik die gleiche wie im Block 1.
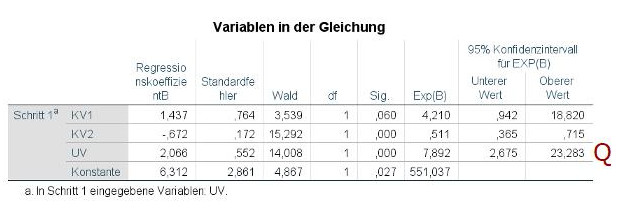
In der Tabelle Variablen in der Gleichung ist jetzt eine Zeile für den zusätzlich hinzugefügten Prädiktor hinzugekommen, in diesem Fall die UV (Q). Diese weist einen signifikant positiven Effekt auf, die Odds-Ratio von 7.89 deutet auf einen starken Effekt hin.
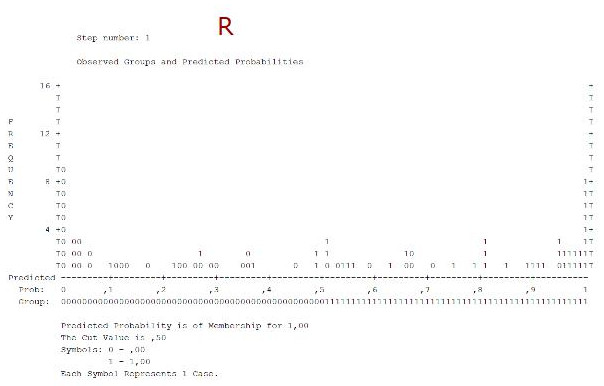
Jetzt betrachten wir auch das Klassifikationsdiagramm (R). Es stellt ein Histogramm der vorhergesagten Wahrscheinlichkeiten für das Ereignis (AV =1) dar.
Wir sehen, dass in der Mitte relativ wenig Beobachtungen liegen. Das ist gut, denn anderenfalls würde es bedeuten, dass das Modell für viele Beobachtungen nicht wirklich entscheiden kann, in welche der beiden Gruppen bezüglich der AV es sie kategorisieren soll.
Außerdem kann man durch Betrachtung der einzelnen Säulen im Histogramm feststellen in welchem Maße Beobachtungen falsch kategorisiert werden. Wenn in einer Säule eine 0 steht, ist dies eine Beobachtung mit dem wahren Wert von 0, wenn eine 1 steht mit einem wahren Wert von 1. In unserem Beispiel sind links (=Vorhersage einer sehr geringen Wahrscheinlichkeit für das Ereignis) nur sehr wenige fehlklassifizierte Elemente mit wahrem Wert von 1 zu sehen, und rechts (=Vorhersage einer sehr hohen Wahrscheinlichkeit für das Ereignis) nur sehr wenige fehlklassifizierte Elemente mit wahrem Wert von 0.
5. Quellen
Baltes-Götz, B. (2012). Logistische Regressionsanalyse mit SPSS. https://www.uni-trier.de/fileadmin/urt/doku/logist/logist.pdf
Chen, H., Cohen, P., & Chen, S.(2010). How big is a big odds ratio? Interpreting the magnitudes of odds ratios in epidemiological studies. Communications in Statistics -Simulation and Computation, 39, 860-864. https://doi.org/10.1080/03610911003650383
Ferguson, C. J. (2009). An effect size primer: A guide for clinicians and researchers. Professional Psychology: Research and Practice, 40, 532-538. https://doi.org/10.1037/a0015808
Universität Zürich, Methodenberatung (n.d.). Logistische Regressionsanalyse. https://www.methodenberatung.uzh.ch/de/datenanalyse_spss/zusammenhaenge/lreg.html
Wuensch, K. (2019). Cohen’s Conventions for Small, Medium, and Large Effects. http://core.ecu.edu/psyc/wuenschk/docs30/EffectSizeConventions.pdf