Ausreißer in einem Lavaan-Modell:
Einflussreiche Fälle identifizieren
Arndt Regorz, Dipl. Kfm. & M.Sc. Psychologie, 07.05.2026
Wenn Sie eine konfirmatorische Faktorenanalyse (CFA) oder ein Strukturgleichungsmodell (SEM) durchführen, sollten Sie auf Ausreißer bzw. einflussreiche Fälle prüfen, da diese die Ergebnisse Ihrer Analyse erheblich beeinflussen können. Dieses Tutorial zeigt Ihnen, wie Sie das für ein Lavaan-Modell mit dem Paket semfindr machen können.
Einflussreiche Fälle
Um das weitere Vorgehen zu verstehen, ist ein Blick auf den Umgang mit einflussreichen Fällen in der Regressionsanalyse hilfreich. Dort gibt es viele verschiedene Ansätze, um Ausreißer bzw. einflussreiche Fälle zu identifizieren.
Ein verbreiteter Ansatz zur Identifikation einflussreicher Fälle im Regressionskontext ist DFBETA. Damit werden Fälle identifiziert, die einen großen Einfluss auf die resultierenden Regressionssteigungen haben.
DFBETA basiert auf dem Leaving-One-Out-Ansatz (LOO). Das Modell wird einmal für jede Beobachtung neu geschätzt, wobei jeweils dieser Fall aus den Daten ausgelassen wird. Auf diese Weise kann der Einfluss einer einzelnen Beobachtung beurteilt werden: Wie verändert sich die Regressionssteigung ohne diese Beobachtung?
Das R-Paket semfindr hat diesen Ansatz auch für SEM, CFA und Pfadanalysen mit Lavaan verfügbar gemacht.
Einflussreiche Fälle mit dem Paket semfindr identifizieren
Zunächst müssen wir das Paket semfindr installieren (einmalig) und laden (in jeder Sitzung, in der wir es verwenden möchten).
#install.packages("semfindr")
library(semfindr)
Dann führen wir unser Lavaan-Modell aus, in diesem Beispiel eine Drei-Faktoren-CFA.
library(lavaan)
head(HolzingerSwineford1939_influential_case_introduced, 5)
cfa_model <- '
visual =~ x1 + x2 + x3
language =~ x4 + x5 + x6
speed =~ x7 + x8 + x9
'
model_fit <- cfa(model = cfa_model,
data = HolzingerSwineford1939_influential_case_introduced,
std.lv = T)
summary(model_fit,
standardized = T)
standardizedsolution(model_fit, level=.95) # Confidence interval for beta
Anschließend können wir mit der Identifikation einflussreicher Fälle beginnen.
# INFLUENTIAL CASES
Dies beginnt damit, dass das Lavaan-Modell so oft neu geschätzt wird, wie wir Beobachtungen in unserer Stichprobe haben (= LOO-Ansatz).
# 0 Rerun this model (leaving one out - LOO)
fit_rerun <- lavaan_rerun(model_fit)
Bei einem einfachen Modell und einem kleinen Datensatz dauert das nur wenige Sekunden. Bei einem komplexeren Modell und einem größeren Datensatz kann das jedoch einige Zeit in Anspruch nehmen.
In diesem Fall ist es hilfreich, die parallele Verarbeitung zu nutzen. Die meisten modernen Computer haben mehr als einen Kern. Diese Information finden Sie in den Systeminformationen Ihres Computers. Im Falle von Windows öffnen Sie den Task-Manager, gehen zum Reiter „Leistung" und schauen sich die Spezifikationen für die CPU an.
Mein Computer hat 4 Kerne; daher verwende ich den folgenden Code, um die Berechnung parallel auf allen vier Kernen durchführen:
fit_rerun <- lavaan_rerun(model_fit,
parallel = T,
ncores = 4) # faster with parallel processing
Es gibt verschiedene Maße für die Parameteränderung. DFTHETAS ist ein standardisiertes Änderungsmaß, d. h. eine Änderung, die mit dem Standardfehler des Parameters standardisiert wurde. Leider ist dieses Maß recht schwer zu interpretieren. Die Ergebnisse sind nach der generalisierten Cook-Distanz sortiert.
# 1 Standardized change (DFTHETAS)
change_est <- est_change(fit_rerun)
change_est
--- visual~~language visual~~speed language~~speed gcd 100 -1.130 0.531 -0.537 3.191 85 0.184 0.026 0.000 2.190 87 -0.897 0.079 -0.120 1.612 32 0.369 0.243 0.176 1.209 40 -0.181 0.203 0.352 1.119 1 0.131 -0.018 0.019 1.098 19 0.308 0.264 0.264 1.089 36 0.196 0.076 0.057 0.985 26 0.350 0.070 0.072 0.757 2 -0.031 0.058 -0.051 0.734
Einfacher zu interpretieren ist die Parameteränderung der standardisierten Parameterschätzungen, DFZTHETA. Dies sagt Ihnen, wie stark der standardisierte Parameter (Beta) durch eine Beobachtung beeinflusst wurde.
# 2 Raw parameter change standardized (DFZTHETA)
change_est_raw_s <- est_change_raw(fit_rerun,
standardized = T)
change_est_raw_s
Sie können die Ausgabe auf einen bestimmten Parametertyp beschränken. Hier betrachten wir zum Beispiel nur die Varianzen und Kovarianzen:
change_est_raw_vk <- est_change_raw(fit_rerun,
parameters = ("~~"),
standardized = T)
change_est_raw_vk
Sie können die Ausgabe weiter eingrenzen, indem Sie sie auf bestimmte Parameter beschränken. Hier zum Beispiel auf drei Faktorkorrelationen:
change_est_raw_k <- est_change_raw(fit_rerun,
parameters = c("visual~~language", "visual~~speed", "language~~speed"),
standardized = T)
change_est_raw_k
-- id visual~~language id visual~~speed id language~~speed
1 100 -0.132 100 0.075 100 -0.066
2 87 -0.105 7 -0.066 43 0.044
3 32 0.046 83 -0.060 40 0.043
4 26 0.042 19 0.035 70 0.042
5 90 -0.040 32 0.033 19 0.031
6 19 0.038 99 0.032 50 0.030
7 11 0.037 25 -0.029 32 0.021
8 76 -0.034 40 0.028 3 -0.020
9 72 -0.031 37 0.025 67 -0.020
10 86 -0.030 9 0.023 7 -0.020
Der erste Wert für visual~~language kann folgendermaßen interpretiert werden: Der Fall mit der id=100 hat zu einer Korrelation zwischen visual und language geführt, die um .132 niedriger ist als in einer Stichprobe ohne diesen Fall. Ohne Fall 100 wäre diese Korrelation also höher.
Ein möglicher Schwellenwert für einflussreiche Fälle ist .10. Die Begründung dafür ist, dass für standardisierte Parameter (Korrelationen) .20 die Differenz zwischen klein (.10) und mittel (.30) bzw. zwischen mittel und groß (.50) ist. Somit entsprechen .10 also 50 % einer solchen Differenz.
Sie können sich auch die Veränderung der Modellanpassung ansehen, die auf eine einzelne Beobachtung zurückgeht.
# 3 Change in model fit
change_fit <- fit_measures_change(fit_rerun)
print(change_fit,
sort_by = "cfi")
--- chisq cfi rmsea tli
100 -3.694 0.017 -0.013 0.026
99 3.481 -0.014 0.016 -0.020
85 2.973 -0.012 0.013 -0.018
14 -2.586 0.010 -0.010 0.015
8 -2.172 0.009 -0.008 0.013
1 1.836 -0.008 0.008 -0.012
13 -1.890 0.008 -0.007 0.012
23 -1.829 0.008 -0.007 0.011
26 1.975 -0.008 0.008 -0.011
79 -1.855 0.007 -0.007 0.011
Note:
- Only the first 10 case(s) is/are displayed. Set ‘first’ to NULL to display all cases.
- Cases sorted by cfi in decreasing order on absolute values.
Ein möglicher Schwellenwert ist eine Chi-Quadrat-Änderung von 10 (oft bei Modifikationsindizes verwendet) oder eine CFI-Änderung von .01 (oft bei der Prüfung der Messäquivalenz verwendet).
Und schließlich können Sie einflussreiche Fälle anhand der generalisierten Cook-Distanz (gcd) plotten.
# 4 Plot influence cooks distance
gcd_plot(influence_stat(fit_rerun),
largest_gcd = 5)
Ein möglicher Schwellenwert ist eine gcd größer als 1.
Sie können dies auf jene Parameter beschränken, die für Sie von theoretischem Wert sind, zum Beispiel die Faktorkorrelationen in unserem Beispiel.
gcd_plot(influence_stat(fit_rerun,
parameters = c("visual~~language", "visual~~speed", "language~~speed")),
largest_gcd = 5)
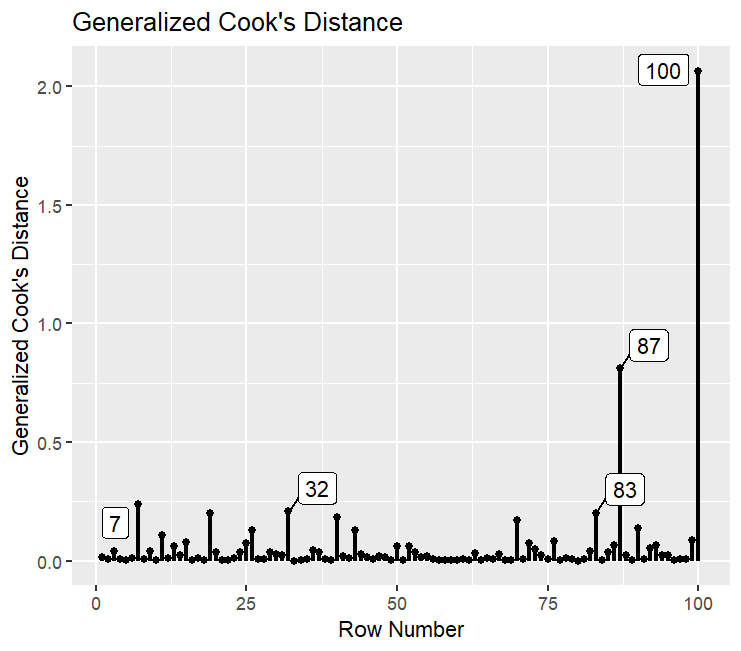
Hier sehen wir, dass nur ein Fall, Nr. 100, eine größere gcd als 1 hat, wenn wir nur die für uns theoretisch relevanten Parameter betrachten.
Was tun mit einflussreichen Fällen?
Wenn Sie einen oder mehrere einflussreiche Fälle identifiziert haben, bleibt die Frage: Was tun mit diesen Fällen? Darauf gibt es verschiedene mögliche Antworten.
Ein möglicher Ansatz ist, diese extremen Beobachtungen manuell zu inspizieren und zu entscheiden, ob sie eine legitime (aber extreme) Antwort darstellen oder ob sie das Ergebnis von Fehlern oder von Teilnehmern sind, die nicht ernsthaft geantwortet haben (z. B. dieselbe Antwort auf jede Frage gegeben haben). In diesem Fall würde man lediglich die legitimen Fälle beibehalten.
Ein zweiter möglicher Ansatz ist, eine Sensitivitätsanalyse durchzuführen. Sie analysieren Ihre CFA oder Ihr SEM zunächst mit allen Fällen und dann ein zweites Mal ohne die extremen Fälle. Wenn die zentralen Ergebnisse Ihrer Analyse gleich bleiben, dann wissen Sie, dass die extremen Fälle keinen starken Einfluss auf die Gesamtergebnisse für Ihre Hypothesen haben.
Literatur
Cheung, S. F., & Lai, M. H. (2026). semfindr: An R package for identifying influential cases in structural equation modeling. Multivariate Behavioral Research. Advance online publication. https://doi.org/10.1080/00273171.2026.2634293