Konfirmatorische Faktorenanalyse (CFA) mit R lavaan
1. Grundlagen
Arndt Regorz, Dipl. Kfm. & MSc. Psychologie, 30.10.2025
In diesem Tutorial lernen Sie die Grundlagen einer Confirmatory factor analysis (CFA, konfirmatorische Faktorenanalyse) mit lavaan, dem SEM-Modul von R.
Eine CFA besteht, wie auch ein SEM oder eine Pfadanalyse, aus sechs Schritten:
- Modellspezifikation (model specification)
- Modellidentifzierung (model identification)
- Modellschätzung (model estimation)
- Modellevaluation (model evaluation)
- Modellrespezifikation (model respecification)
- Modellinterpretation (model interpretation)
In diesem Tutorial werde ich auf alle sechs Schritte eingehen. Alternativ können Sie sich den Inhalt dieses Tutorials auch als Video ansehen.
Video zum Tutorial
(Hinweis: Mit Anklicken des Videos wird ein Angebot des Anbieters YouTube genutzt.)
1. Modellspezifikation (model specification)
Der erste Schritt zur Durchführung einer konfirmatorischen Faktorenanalyse mit R ist das Aufstellen des Modells.
Als Beispieldatensatz verwenden wir einen in lavaan eingebauten klassischen Datensatz zur Faktorenanalyse, HolzingerSwineford1939. Das ist ein Datensatz mit den Ergebnissen neun kognitiver Leistungstests, die theoretisch drei Faktoren zugeordnet werden können. Hier ist eine konzeptionelle Modellgrafik des theoretischen Modells:
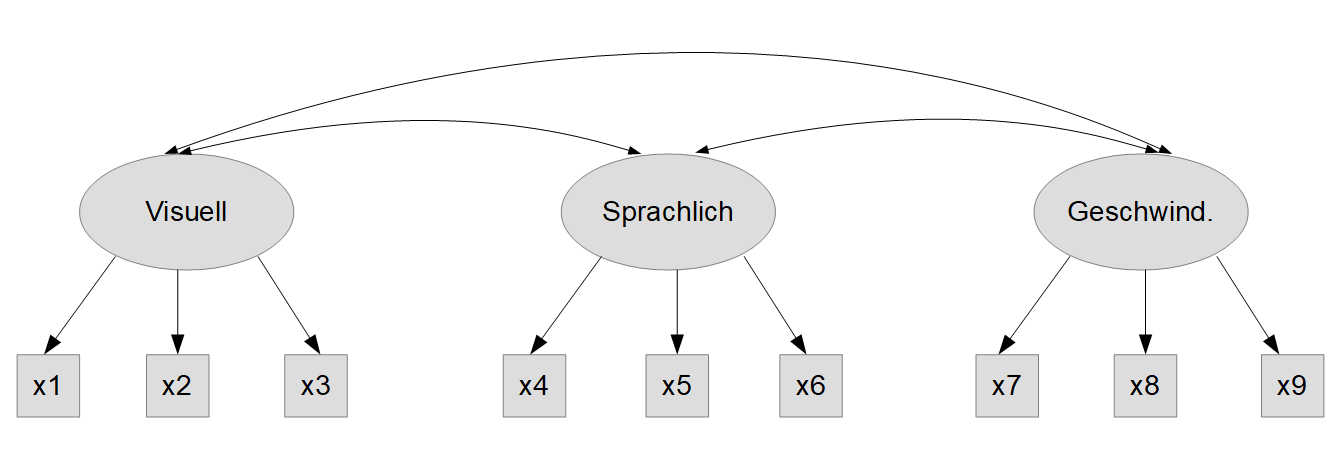
Die Subtests haben dabei folgenden Inhalt:
a) Visuell
x1 Visual perception
x2 Cubes
x3 Lozenges
b) Sprachlich
x4 Paragraph comprehension
x5 Sentence completion
x6 Word meaning
c) Geschwindigkeit
x7 Speeded addition
x8 Speeded counting of dots
x9 Speeded discrimination straight and curved capitals
Für die Spezifikation eines CFA-Modells benötigen wir vor allem zwei verschiedene Befehle:
Einen Befehl, um Faktorladungen zu spezifizieren. Das tut man mit dem "=~"-Operator.
Einen Befehl, um Kovarianzen/Korrelationen zu spezifizieren. Das tut man mit dem "~~"-Operator (jeweils ohne Anführungszeichen).
In unserem Beispiel brauchen wir zunächst nur die Faktorladungen, da die Kovarianz der drei Faktoren automatisch geschätzt wird von lavaan.
library(lavaan)
head(HolzingerSwineford1939, 10)
# Modell 1: Grundmodell
model1 <- '
# Messmodell
visuell =~ x1 + x2 + x3
sprachlich =~ x4 + x5 + x6
geschwindigkeit =~ x7 + x8 + x9
'
2. Modellidentifzierung (model identification)
Bei der Modellidentifizierung geht es darum, ob unser Modell überhaupt theoretisch schätzbar ist. Das bedeutet, dass man mindestens so viele Informationen haben muss, wie man Parameter schätzen möchte. Bei der Identifizierung sind zwei Perspektiven zu unterscheiden: global und lokal. Global bedeutet, dass es insgesamt genug Informationen gibt, um alle Parameter schätzen zu können. Lokal bedeutet, dass das auch für jeden Teil des Modells gilt - es ist durchaus möglich, dass man zwar insgesamt genug Informationen hat, aber in Teilen des Modells zu wenig. Auch das kann dazu führen, dass ein Modell nicht schätzbar ist.
Bei der Identifizierung unterscheidet man drei verschiedene Status: Overidentified (überidentifiziert), just identified (gerade identifiziert) und underidentified (unteridentifiziert).
Overidentified bedeutet, dass man mehr empirische Informationen (einzigartige Einträge in der Varianz-Kovarianzmatrix; nicht: Anzahl an Versuchspersonen) hat als zu schätzende Parameter. Dann kann das Modell geschätzt werden und man hat eine positive Anzahl an Freiheitsgraden. Das hat zur Konsequenz, dass man einen Modelltest durchführen kann und auch Fit-Indizes berechnen kann.
Just identified bedeutet, dass man genau so viele Informationen hat wie zu schätzende Parameter. Dann kann man das Modell schätzen und man hat genau 0 Freiheitsgrade. Das hat zur Konsequenz, dass das Modell immer perfekt zu den Daten passt. Man kann also nicht prüfen, ob das Modell gut ist, weil es immer genau passen muss. In so einem Fall sind Modelltest und Fit-Indizes ohne Aussagekraft. Trotzdem kann man die aus einem so geschätzten Modell gewonnenen Parameter interpretieren. Man kann aber nicht sinnvoll prüfen, ob das Modell zu den Daten passt.
Underidentified (oder not identified) bedeutet, dass man weniger Informationen als zu schätzende Paramter hat. Damit ist das Modell nicht schätzbar und man muss durch geeignete Restriktionen dafür sorgen, dass man wenigstens ein just identfied Modell bekommt.
In einfachen CFA-Modellen ist die globale Identifikation in einem CFA-Modell selten ein Problem. Die lokale kann jedoch u.U. problematisch sein. Hier gibt es drei wichtige Faustregeln:
- Ein Messmodell mit drei Indikatorvariablen ist lokal just identified (wenn man keine Fehlerkovarianzen zwischen Indikatoren spezifiziert hat)
- Ein Messmodell mit nur zwei Indikatorvariablen ist lokal underidentified.
- Ein Messmodell mit zwei korrelierten Faktoren, die jeweils zwei Indikatorvariablen haben, ist overidentified und kann also geschätzt werden
In unserem Beispiel haben wir korrelierte Faktoren mit je drei Indikatoren und insofern keine Identifikationsprobleme.
Ein weiterer wichtiger Punkt, der mit der Modellidentifizierung zusammenhängt, ist die Metrik. Für latente Variablen, die ja nicht direkt gemessen werden können, muss eine Maßeinheit vorgegeben werden, eine Metrik.
Dafür gibt es verschiedene Optionen, die beiden wichtigsten sind:
1. Die Ladung des jeweils ersten Indikators eines Faktors wird auf 1 fixiert. Das ist die Default-Vorgabe von lavaan und wird automatisch so gemacht, wenn man keine andere Vorgabe macht. Insbesondere bei SEM-Modellen entscheidet man sich häufig für diese Variante
2. Die Varianz der Faktoren wird auf 1 fixiert. Für CFA ist das vermutlich die am Häufigsten verwendete Option. In lavaan kann man das im Rahmen der Modellschätzung vorgeben, wie wir weiter unten sehen werden.
3. Modellschätzung (model estimation)
Für die Modellschätzung verwenden wir die cfa-Funktion von lavaan. Wie im vorherigen Punkt angesprochen, möchten wir als Metrik die Varianzen der latenten Faktoren auf 1 fixieren. Das erreichen wir mit std.lv = TRUE.
model.fit1 <- cfa(model=model1, data=HolzingerSwineford1939, std.lv = TRUE)
4. Modellevaluation (model evaluation)
Wenn die Schätzung erfolgreich war, prüfen wir jetzt, ob das Modell einen hinreichend guten Fit zu den Daten aufweist. Dabei sind zwei Komponenten zu unterscheiden, Global fit und Local fit. Beim Global fit geht es darum, ob das Modell insgesamt (im Durchschnitt) gut zu den Daten passt. Aber auch wenn das so ist, ist es möglich, dass in Teilen das Modell sehr gut passt und in Teilen schlecht. Daher sollte man zusätzlich noch den Local fit betrachten, ob es also irgendwo areas of strain gibt, also Bereiche, in denen das Modell nicht so gut zu den Daten passt.
summary(model.fit1, fit.measures = TRUE, standardized=TRUE)
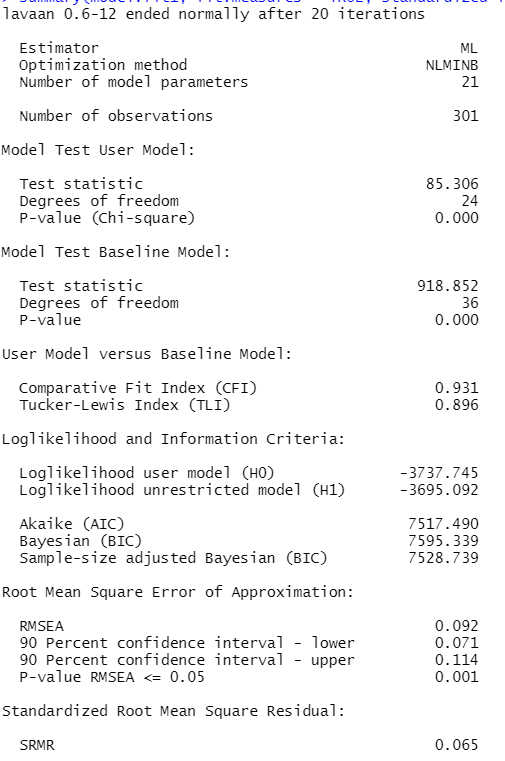
Zunächst sehen wir, dass die Modellschätzung erfolgreich war ("ended normally..."). Wenn das nicht der Fall wäre, könnten wir die nachfolgenden Ergebnisse nicht sinnvoll interpretieren.
Wir haben einen signifikanten Modelltest ("Model Test User Model"), also passt unser Modell nicht perfekt zu den Daten. Von den wesentlichen Fit-Indizes liegt der CFI mit .931 etwas unter dem Cut-off von .95. Auch der RMSEA liegt mit .092 über dem empfohlenen Wert von .06. Lediglich der SRMR liegt mit .065 unter dem Wert von .08 und wäre akzeptabel. (Eine Quelle zu den Cut-off-Werten finden Sie am Ende des Tutorials.) Insgesamt passt dieses Modell also noch nicht gut zu den Daten. Die Frage des local fit werden wir im Zusammenhang mit dem nächsten Schritt betrachten, der jetzt nötigen Respezifikation des Modells.
5. Modellrespezifikation (model respecification)
Um zu prüfen, wo im Modell die Ursachen für die Fit-Probleme liegen, fordern wir Modifikationsindizes an. Das sind automatisch erzeugte Verbesserungsvorschläge, wie der Model-Fit der CFA besser werden kann.
mi <- modindices(model.fit1)
mi[mi$mi > 10,]

Wir finden hier vier mögliche Verbesserungsvorschläge. Die beiden größten (Spalte "mi"):
visuell =~ x9: Das ist der Vorschlag einer Cross-Loading des Items 9 zusätzlich auch auf den ersten Faktor
x7~~x8: Das ist der Vorschlag einer Fehlerkovarianz zwischen den Items 7 und 8.
Beim Umgang mit Modifikationsindizes ist es wichtig, nicht blind den zahlenmäßig größten Vorschlägen zu folgen, sondern nur inhaltlich sinnvolle Änderungen vorzunehmen.
Hier sind tatsächlich beide o.g. Vorschläge inhaltlich sinnvoll, denn:
Das Item 9, "Speeded discrimination straight and curved capitals" beschreibt eine visuelle Aufgabe auf Zeit. Daher ist es höchst plausibel, dass dieses Item auch auf den visuellen Faktor zusätzlich zum Geschwindigkeits-Faktor lädt.
Items 7 und 8, "Speeded addition" und "Speeded counting of dots" beschreiben beide Rechenoperationen, anders als das eher visuelle Item 9. Daher ist es ebenfalls logisch, dass diese beiden Items zusätzliche geteilte Varianz aufweisen.
Auch wenn hier beide Vorschläge inhaltlich sinnvoll sind, sollte man keinesfalls jetzt beide Änderungen gleichzeitig vornehmen. Eine einzige Änderung führt häufig an verschiedenen Stellen des Modells zu Verbesserungen, so dass man i.d.R. nur eine Änderung zur Zeit vornehmen sollte. (Es gibt Ausnahmen von der Regel, aber die sprengen den Rahmen dieses Einführungstutorials.) Da im Beispiel beide Vorschläge ähnlich große Modifikationsindizes aufweisen und beide sinnvoll sind, werden im Folgenden in zwei getrennten Modellen beide mögliche Respezifikationen durchgeführt - zunächst das Beispiel mit der zusätzlichen Fehlerkovarianz zwischen Items 7 und 8.
# Modell 2: Angepasstes Modell
model2 <- '
# Messmodell
visuell =~ x1 + x2 + x3
sprachlich =~ x4 + x5 + x6
geschwindigkeit =~ x7 + x8 + x9
# Fehlerkovarianz
x7 ~~ x8
'
model.fit2 <- cfa(model=model2, data=HolzingerSwineford1939, std.lv = TRUE)
summary(model.fit2, fit.measures = TRUE, standardized=TRUE)
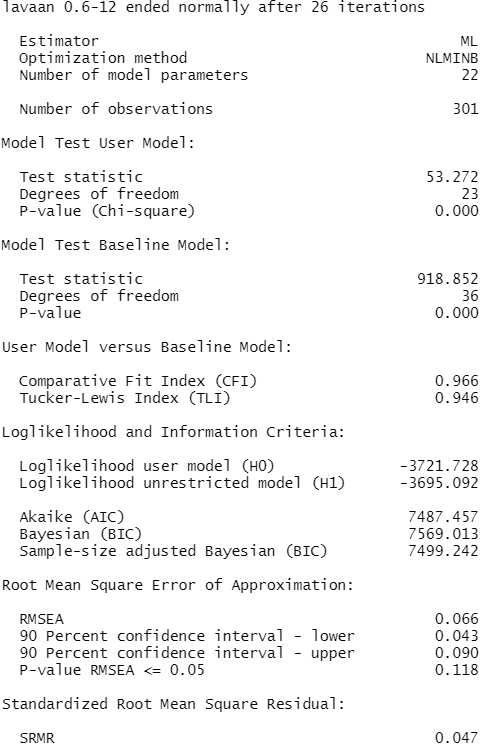
Der globale Modelltest ist immer noch signifikant, aber die Fit-Indizes haben sich deutlich verbessert. CFI .966, RMSEA .066 und nicht mehr signifikant größer als .05, und SRMR .047. Mit diesem globalen Fit können wir gut leben.
# Local Fit
mi <- modindices(model.fit2)
mi[mi$mi > 10,]
Wir erhalten bei diesem Modell keinen Modifikationsindex von größer als 10 mehr, also ist auch der local Fit gegeben.
Zusätzlich sollte man noch prüfen, ob es problematische Parameterschätzungen gibt. Das wären negative Varianzen oder sehr kleine und ggf. nicht signifikante standardisierte Faktorladungen. Das ist im Beispiel nicht der Fall.
Wenn man eine derartige Modellmodifikation durchführt, prüft man mit einem Likelihood-Ratio-Test (LR-Test, Likelihood-Quotienten-Test), ob sich das Modell signifikant verbessert hat.
# Vergleich beider Modelle
lavTestLRT(model.fit1, model.fit2)

Das Modell hat sich gegenüber dem vorherigen Modell signfikant verbessert.
6. Modellinterpretation (model interpretation)
Jetzt erst können wir die Ergebnisse der Schätzung inhaltlich interpretieren.
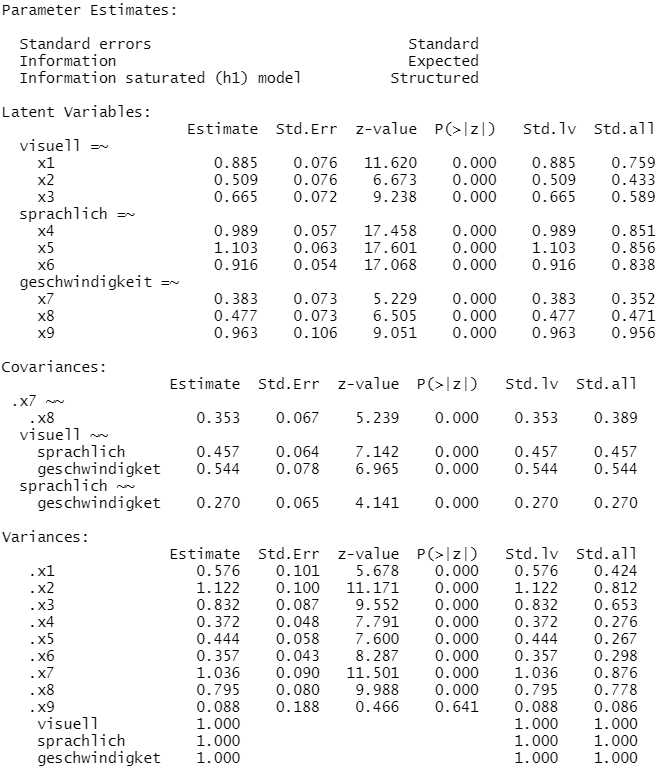
Besonders interessant sind für uns die Kovarianzen zwischen den Faktoren. Die standardisierten Kovarianzen sind Korrelationen und als solche interpretierbar. Zwischen Visuell und Sprachlich gab es eine mittlere Korrelation, r = .46, zwischen Visuell und Geschwindigkeit eine große Korrelation, r = .54, und zwischen Sprachlich und Geschwindigkeit eine kleine Korrelation, r = .27.
Was außerdem noch interessant ist, sind die standardisierten Faktorladungen, weil diese bei der inhaltlichen Interpretation der Faktoren helfen können. Beim Faktor Geschwindigkeit fällt nämlich auf, dass die Ladung für das Item 9 (visuelle Geschwindigkeit) viel höher ist (.956) als für die anderen beiden Geschwindigkeitsitems (.352 und .471). Das hat zur Konsequenz, dass in diesem Modell unser Faktor für Geschwindigkeit inhaltlich eine Geschwindigkeit mit Schwerpunkt visuelle Verarbeitung ist.
Alternativ hier noch der Code für die Modellanpassung per Cross-Loading:
# Modell 2b: Alternatives angepasstes Modell
model2b <- '
# Messmodell
visuell =~ x1 + x2 + x3 + x9
sprachlich =~ x4 + x5 + x6
geschwindigkeit =~ x7 + x8 + x9
'
model.fit2b <- cfa(model=model2b, data=HolzingerSwineford1939, std.lv = TRUE)
summary(model.fit2b, fit.measures = TRUE, standardized=TRUE)
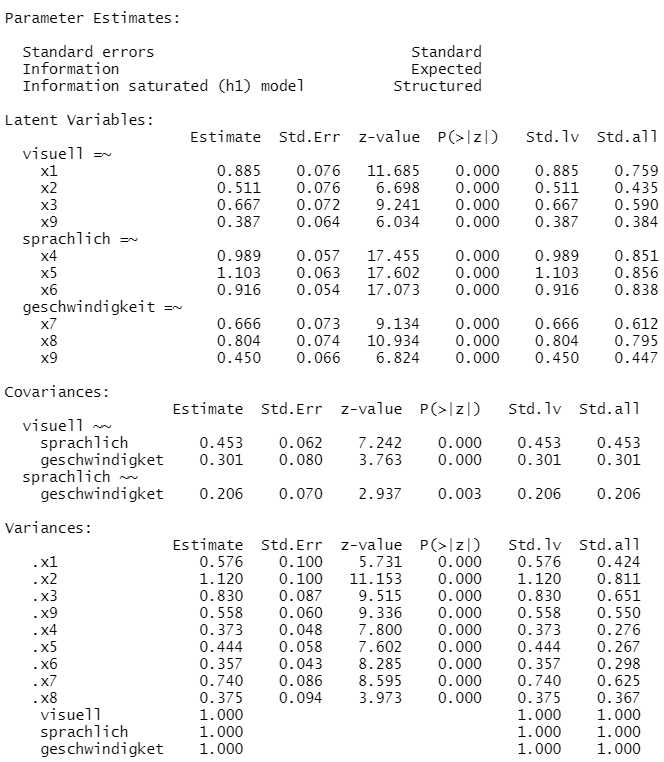
Der Modellfit ist ähnlich gut wie beim Modell mit der Fehlerkovarianz (hier nicht abgedruckt). Wenn man jetzt dieses Ergebnis mit dem vorherigen hinsichtlich der Schätzungen vergleicht, sieht man inhaltliche Unterschiede: Die Faktorkorrelationen haben sich teilweise deutlich geändert.
Die Ursache dafür ist eine geänderte Bedeutung des Geschwindigkeitsfaktors. Jetzt sind dort die Ladungen für die beiden Items zu Rechengeschwindigkeit deutlich höher als die des Items für visuelle Geschwindigkeit. In diesem Modell ist also die inhaltliche Bedeutung der Geschwindigkeit eher eine Geschwindigkeit mit Schwerpunkt Rechnen und Zählen.
Man sieht an diesem Beispiel, dass Modellmodifikationen über Cross-Loadings oder Fehlerkovarianzen auch inhaltliche Konsequenzen für die Interpretation der Modellschätzung haben können.
Literatur
Brown, T. A. (2015). Confirmatory factor analysis for applied research. Guilford publications.
Hu, L. T., & Bentler, P. M. (1999). Cutoff criteria for fit indexes in covariance structure analysis: Conventional criteria versus new alternatives. Structural Equation Modeling, 6(1), 1-55. https://doi.org/10.1080/10705519909540118
Rosseel, Y. (n.d.). Lavaan tutorial. Retrieved December 16, 2024, from https://lavaan.ugent.be/tutorial/