Mehrebenenanalyse mit R (HLM mit R)
– nlme Package
Arndt Regorz, Dipl. Kfm. & MSc. Psychologie, 19.05.2022
Dieses Tutorial zeigt Ihnen die Syntax zum Schätzen eines Mehrebenenmodells mit dem nlme Package (mit der lme Funktion) und die Interpretation der wesentlichen Ergebnisse. Das hier vorgestellte Modell ist aus dem Grundlagenwerk von Hox et a. (2017) zur Mehrebenanalyse, dort in Kapitel 2 vorgestellt. Die Daten dazu können Sie auf der Internetseite von Hox herunterladen (http://joophox.net/mlbook2/DataExchange.zip), so dass Sie alle Auswertungen selbst nachvollziehen können.
INHALT
- Nullmodell
- Fixed Slopes (Random Intercept)
- Random Slopes
- Cross-Level-Interaction
- Vollständiger R-Code
- Ausblick
- Literatur
Um das Maximum aus diesem Tutorial mitzunehmen, ist ein gewisse Grundverständnis der Mehrebenenanalyse/HLM notwendig. Falls Sie dazu noch keine Basiskenntnisse haben, empfehle ich das Buch von Hox et al. (2017), insbesondere die Kapitel 2-4, 12-13.
Es gibt in R verschiedene Packages, um Mehrebenenmodelle zu schätzen. Am bekanntesten sind die beiden Packages lme4 und nlme. Für Einsteiger würde ich insbesondere bei Querschnittsmodellen eher das Package lme4 empfehlen, hier finden Sie mein Tutorial dazu.
Das Modul nlme hat Vorteile insbesondere in Längsschnittmodellen, da es auch korrelierte Fehlerterme abbilden kann. Wenn Sie also kurz- bis mittelfristig solche Modelle schätzen möchten, lohnt sich die Beschäftigung mit nlme.
Doch zum Einsteig empfiehlt es sich, auch beim Erlernen von nlme erst einmal mit einem einfachen Querschnittsmodell anzufangen, hier dem o.g. Modell von Hox. Dabei wird die Popularität von Schülerinnen und Schülern (genestet in Schulklassen, daher Mehrebenenmodell) vorhergesagt durch deren Extraversion und deren Geschlecht (Level 1 Prädiktoren) sowie durch die Berufserfahrung der Lehrkraft (Level 2 Prädiktor). Zum Schluss soll dabei auch geprüft werden, ob es eine Cross-Level-Interaktion gibt zwischen der Extraversion der Schülerinnen und Schüler und der Berufserfahrung der Lehrkraft.
Bei der Mehrebenenanalyse erfolgt die Modellierung typischerweise in mehreren Schritten. Man startet mit dem einfachsten möglichen Modell, dem Nullmodell, erweitert dieses um Fixed Slopes, später um Random Slopes und ggf. noch um Cross Level Interactions.
Hinweis: Bei der folgenden Modellierung wurde aus didaktischen Gründen entsprechend dem Beispiel aus dem Buch von Hox et al. (2017) keine Prädiktorvariable zentriert. Die Zentrierung von Prädiktoren ist im Rahmen von HLM ein wichtiges, aber auch komplexes Thema, so dass es zum Einstieg leichter ist, zunächst einmal ein Modell ohne Zentrierung zu schätzen. Zur Frage der verschiedenen Möglichkeiten der Zentrierung siehe das Tutorial Mehrebenenanalyse Zentrierung sowie bei Enders & Tofighi (2007).
1. Nullmodell
Die Schätzung beginnt mit den Laden der nötigen Module.
library(nlme)
library(performance) # Berechnung ICC
library(reghelper) # Graphische Darstellung der Interaktion
Falls Sie diese Packages noch nicht installiert haben, müssen Sie das vor der ersten Verwendung einmalig tun mit install.packages(...).
Der R-Code zum Schätzen eines Nullmodells mit der lme-Funktion aus dem nlme-Modul ist:
nullmodell <- lme(popular ~ 1, data=popular2,
random= ~1|class, method="ML")
summary(nullmodell)
Der Funktionsaufruf besteht aus vier Teilen:
- Fixed Effects: popular ~ 1
Links die abhängige Variable/Kriteriumsvariable, rechts die Prädiktoren (hier noch keine, nur Schätzung des Intercepts, dargestellt durch die 1), dieser Teil gleicht dem Aufruf einer gewöhnlichen Regression - Verwendete Daten: data=popular2
- Random Effects: random= ~1|class
random = und Tilde-Symbol, dann links vom senkrechten Strich die Random Effects (hier nur ein Random Intercept, dargestellt durch die 1), rechts die Gruppierungsvariable - Schätzmethode: method="ML"
Alternativ wäre hier auch "REML" möglich, also die Restricted Maximum Likelihood-Schätzung.
Als Output erhalten wir:
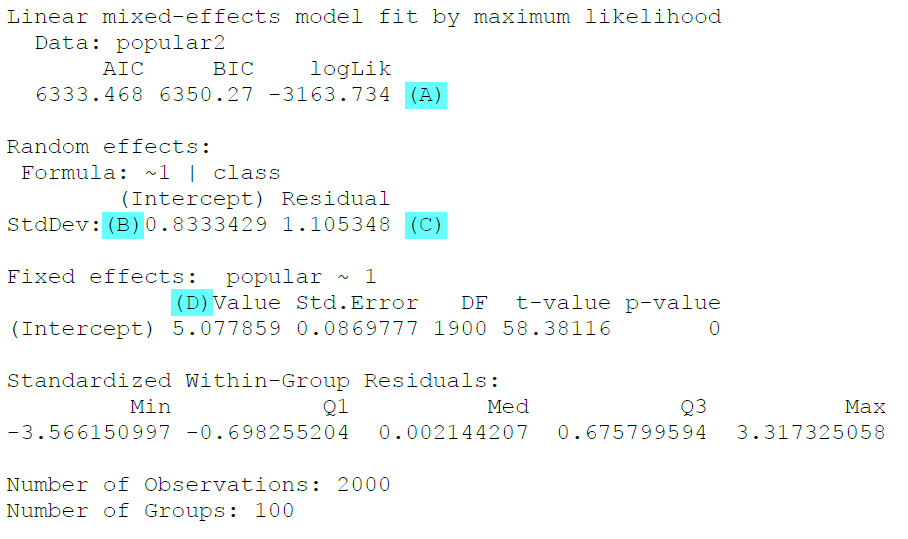
(A) Es wird hier keine Deviance ausgewiesen. Wenn wir diese haben möchten, können wir den Wert für logLik (logLikelihood) mit -2 multiplizieren, um die Deviance zu berechnen.
(B) Standardabweichung Random Intercept (wenn wir stattdessen die Varianz haben möchten, können wir den Wert einfach quadrieren)
(C) Standardabweichung Level 1 Residuen (für Varianz quadrieren)
Aus den beiden Varianzen können wir den Intraklassenkoeffizienten (ICC) berechnen, also den Anteil an der Varianz, der auf Schwankungen zwischen den Gruppen zurückgeht. Das geht am einfachsten mit folgendem Befehl (auf Basis des Moduls performance):
icc(nullmodell)
Das relevante Ergebnis ist die „Adjusted ICC“.
Alternativ kann man die ICC auch per Hand berechnen auf Basis der Varianzen (= quadrierten Standardabweichungen) für Random Intercept und für die Residuen.
ICC = Varianz Random Intercept / (Varianz Random Intercept + Varianz Level 1 Residuen)
ICC = 0.8333429 * 0.8333429 / (0.8333429 * 0.8333429 + 1.105348 * 1.105348) = .362
(D) Fixed Intercept und damit hier (im Nullmodell) die erwartete durchschnittliche Popularität von zufällig ausgewähltem Schüler/Schülerin aus einer zufällig ausgewählten Klasse. Dies ist signifikant von Null verschieden (p-Wert letzte Spalte).
2. Fixed Slopes (Random Intercept) mit nlme
Im nächsten Schritt wollen wir zwei Level 1 Prädiktoren hinzunehmen, Extraversion (extrav) und Geschlecht (sex) der Schülerinnen und Schüler, sowie einen Level 2 Prädiktor, Berufserfahrung der Lehrkraft (texp).
Dies ist der R-Code für das Modell:
fixed_slopes <- lme(popular ~ sex + extrav + texp,
data=popular2, random= ~1|class, method="ML")
summary(fixed_slopes)
Beim Vergleich mit dem Aufruf für das Nullmodell sieht man, dass sich nur an einer Stelle etwas geändert hat, bei den Fixed Effects:
popular ~ sex + extrav + texp
Der Aufruf für die Fixed Effects ist so, wie wir ihn schon von der gewöhnlichen Regression her kennen, zunächst die abhängige Variable bzw. Kriteriumsvariable, dann die Tilde und dann mit Pluszeichen getrennt die verschiedenen Prädiktoren.
Als Output erhalten wir:
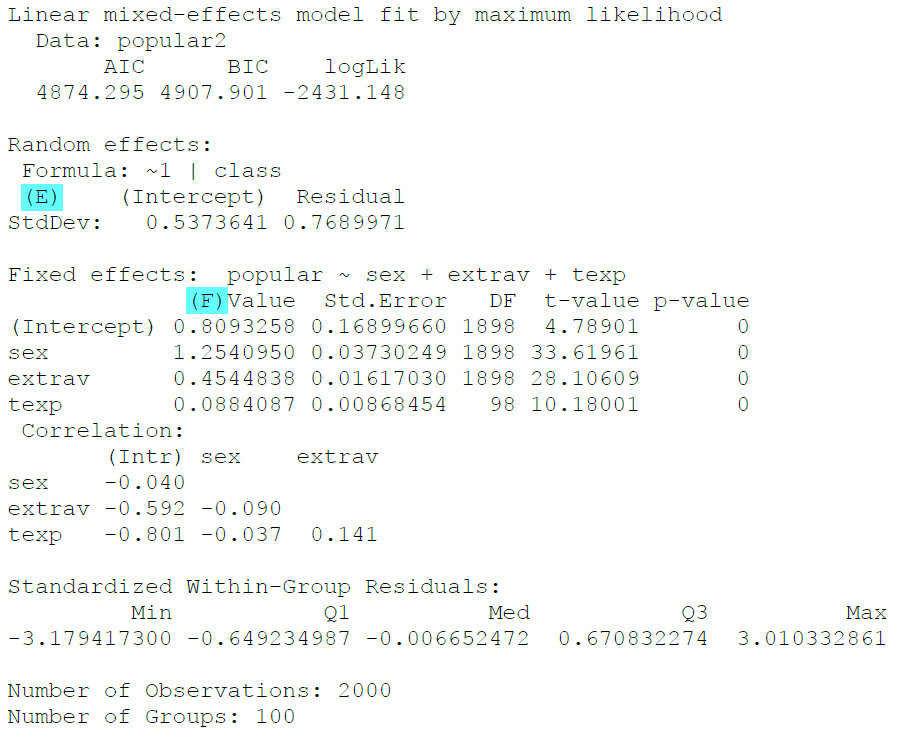
(E) Die Random Effects haben sich verringert, da durch die drei Fixed Effects Prädiktoren zusätzliche Varianz erklärt werden konnte, so dass weniger Schwankung (=Random Effects) übrig geblieben ist.
(F) Hier sind die Regressionsergebnisse für die drei Prädiktoren abzulesen. Und in der letzten Spalte die p-Werte für den Signifikanztest der verschiedenen Prädiktoren.
3. Random Slope Model mit nlme
Als nächstes wollen wir für die beiden Level 1 Prädiktoren, Extraversion und Geschlecht, zusätzlich Random Effects anfordern.
Dies ist der R-Code für das Modell:
random_slopes_b <- lme(popular ~ sex + extrav + texp,
data=popular2, random= ~ extrav + sex|class, method="ML")
summary(random_slopes_b)
Beim Vergleich mit dem vorherigen (Random Intercept-)Modellaufruf sehen wir, dass sich jetzt bei den Random Effects etwas geändert hat:
random= ~ extrav + sex|class
Dieser Aufruf ist so zu verstehen, dass der Effekt beider Level 1 Prädiktoren extrav und sex jetzt zwischen den verschiedenen Schulklassen schwanken kann. Die 1 aus den vorherigen Modellen zur Schätzung des Random Intercept wird hier nicht mehr aufgeführt, aber es wird dennoch ein Random Intercept geschätzt; wir hätten genauso schreiben können:
random= ~ 1 + extrav + sex|class
Als Output erhalten wir eine Fehlermeldung:

Das kann daraufhin deuten, dass für mindestens einen der zusätzlichen Random Effects die Varianz sehr klein ist, was dann zu Schätzproblemen führt. Daher werden wir jetzt zwei weitere Modelle schätzen, bei denen jeweils nur einer der beiden Level 1 Prädiktoren, sex oder extrav, einen Random Effect erhält. Damit wollen wir identifizieren, wo genau das Schätzproblem liegt.
Wenn wir nur für Geschlecht (und nicht Extraversion) eine Random Slope zulassen, ist das der R-Code:
random_slope_s <- lme(popular ~ sex + extrav + texp, data=popular2,
random= ~ sex|class, method="ML")
summary(random_slope_s)
Der Aufruf der Random Effects hat sich geändert, es fehlt jetzt die Extraversion:
random= ~ sex|class
Als Output erhalten wir wieder eine Fehlermeldung:

Wenn wir stattdessen nur für Extraversion (und nicht Geschlecht) eine Random Slope zulassen, ist das der R-Code:
random_slope_e <- lme(popular ~ sex + extrav + texp, data=popular2,
random= ~extrav|class, method="ML")
summary(random_slope_e)
Als Output erhalten wir:
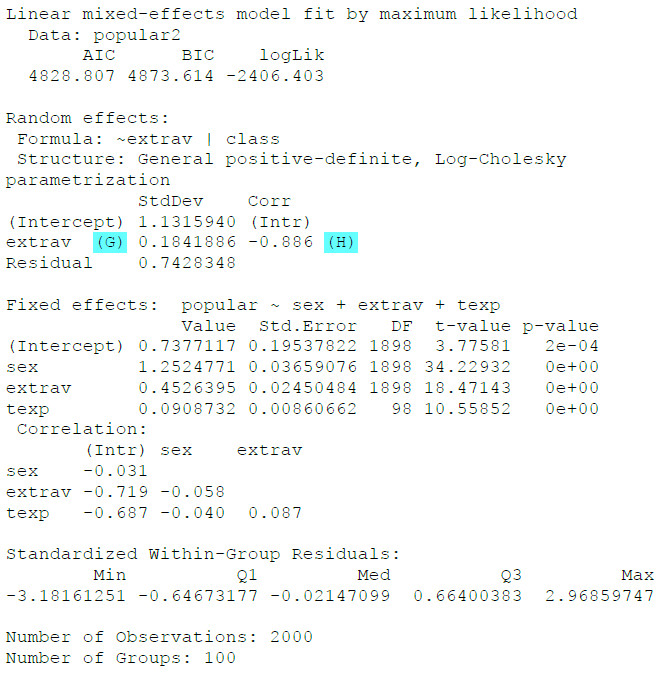
Jetzt haben wir keine Fehlermeldung mehr, also war vermutlich der Random Effect für das Geschlecht das Problem bei der obigen Schätzung. Daher werden wir im Folgenden auf einen Random Effect für Geschlecht verzichten.
(G) Hier ist der Random Effect für die Extraversion, der anzeigt, wie stark der Effekt der Extraversion zwischen den verschiedenen Schulklassen schwankt.
(H) Hier ist die Korrelation der beiden Random Effects, also die Korrelation zwischen dem Random Intercept und der Random Slope für Extraversion.
4. Cross Level Interaction mit nlme
Schließlich wollen wir noch testen, ob die Effekte von Extraversion der Schülerinnen und Schüler (auf Level 1) und Berufserfahrung der Lehrkraft (auf Level 2) miteinander interagieren, ob also der Effekt der Extraversion unterschiedlich ausfällt je nach Berufserfahrung der Lehrkraft (Cross-Level-Interaktion).
Das ist der R-Code dafür:
cross_level <- lme(popular ~ sex + extrav + texp +
extrav:texp, data=popular2,
random= ~extrav|class, method="ML")
summary(cross_level)
Gegenüber dem vorherigen Modell hat sich der Aufruf der Fixed Effects geändert, jetzt ist eine Interaktion hinzugekommen:
popular ~ sex + extrav + texp + extrav:texp
Alternativ hätten wir das auch so aufrufen können (wie wir es auch von der gewöhnlichen Regression mit lm() für eine Moderatoranalyse kennen):
popular ~ sex + extrav * texp
Als Output erhalten wir:

(I) Dies ist die Cross-Level-Interaktion. Mit jedem Jahr an Berufserfahrung der Lehrkraft sinkt der Effekt von Extraversion auf die Popularität der Schülerinnen und Schüler um 0.025 Einheiten.
Wenn man eine signifikante Interaktion hat, bietet es sich an, diese auch graphisch darzustellen. Dafür kann man u.a. die Funktion graph_model aus dem Modul reghelper verwenden, um die Simple Slopes zu plotten:
graph_model(cross_level, y = popular, x = extrav, lines = texp)
Es wird hier zunächst der Name des Ergebnisobjekts der Mehrebenenanalyse angegeben, hier cross_level. Und dann mit y = die AV, mit x = die UV und mit lines = der Moderator.
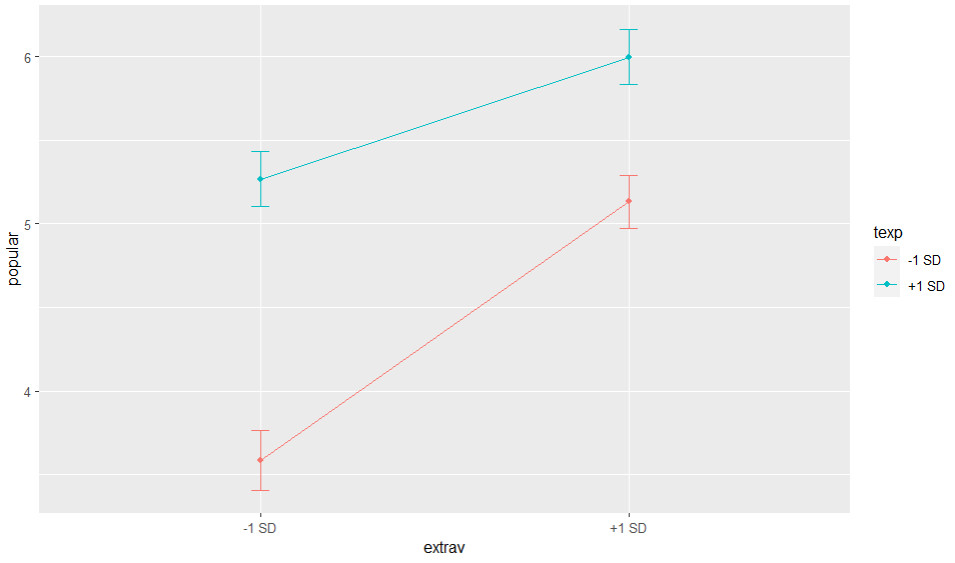
Man sieht hier deutlich, dass in Klassen mit einer Lehrkraft mit langer Berufserfahrung (+ 1 SD) der Effekt der Extraversion auf die Popularität geringer ist (= der Anstieg der Regressionsgerade ist weniger steil).
Neben einer graphischen Darstellung der Simple Slopes könnte man diese auch rechnerisch ermitteln.
simple_slopes(cross_level)
Als Output erhalten wir:

Die ersten drei Simple Slopes stellen eine Moderation des Effekts der Berufserfahrung auf die Popularität durch den Moderator Extraversion dar (Darstellung für drei verschiedene Ausprägungen des Moderators Extraversion). Die zweiten drei Simple Slopes drehen das um und stellen eine Moderation des Effekts von Extraversion auf Popularität durch den Moderator Berufserfahrung der Lehrkraft dar. Für unsere formulierte Fragestellung wären die zweiten Simple Slopes relevant, diese entsprechen auch der Grafik oben.
Damit haben wir die Analyse der Daten abgeschlossen. Informationen zum Bericht eines HLM-Modells finden Sie u.a. im Tutorial Mehrebenenanalyse Ergebnisse berichten sowie bei Dedrick et al. (2009).
5. Vollständiger R-Code
library(nlme)
library(performance) # Berechnung ICC
library(reghelper) # Graphische Darstellung Interaktion
head(popular2, 5)
# 1. Nullmodell
nullmodell <- lme(popular ~ 1, data=popular2,
random= ~1|class, method="ML")
summary(nullmodell)
icc(nullmodell)
# 2. Fixed Slopes (Random intercept)
fixed_slopes <- lme(popular ~ sex + extrav
+ texp, data=popular2,
random= ~1|class, method="ML")
summary(fixed_slopes)
# 3.a Random Slopes
random_slopes <- lme(popular ~ sex + extrav
+ texp, data=popular2,
random= ~ extrav + sex|class, method="ML")
summary(random_slopes)
# 3.b Random Slopes nur Sex
random_slope_s <- lme(popular ~ sex + extrav
+ texp, data=popular2,
random= ~ sex|class, method="ML")
summary(random_slope_s)
# 3.c Random Slopes nur Extraversion
random_slope_e <- lme(popular ~ sex + extrav
+ texp, data=popular2,
random= ~extrav|class, method="ML")
summary(random_slope_e)
# 4. Cross-Level-Interaktion Extraversion und Teacher Experience
cross_level <- lme(popular ~ sex + extrav
+ texp + extrav:texp, data=popular2,
random= ~extrav|class, method="ML")
summary(cross_level)
# Darstellung der Interaktion - Simple Slopes (mit package reghelper)
graph_model(cross_level, y = popular, x = extrav, lines = texp)
simple_slopes(cross_level)
6. Ausblick
Mit diesem Tutorial haben Sie einen ersten Überblick darüber, wie Sie mit R und dem nlme Modul eine Mehrebenenanalyse durchführen können. Um jedoch so ein Modell z.B. für Ihre Abschlussarbeit zu schätzen, benötigen Sie noch eine Reihe weiterer Kompetenzen. für die es mehrere Folgetutorials gibt:
- Mehrebenenanalyse (mit R) 1: Grundlagen mit lme4 (Alternative zu nlme Package)
- Mehrebenenanalyse (mit R) 2: Voraussetzungen prüfen
- Mehrebenenanalyse (mit R) 3: Zentrierung
- Mehrebenenanalyse (mit R) 4: p-Values Random Effects ermitteln
- Mehrebenenanalyse (mit R) 5: Ergebnisse berichten
- Mehrebenenanalyse (mit R) 6: Robuste Schätzung
- Formeln Mehrebenenanalyse verstehen: Videotutorial mit graphischer Erklärung der Formeln einer Mehrebenenanalyse (nicht R-spezifisch)
7. Literatur
Dedrick, R. F., Ferron, J. M., Hess, M. R., Hogarty, K. Y., Kromrey, J. D., Lang, T. R., Niles, J. D., & Lee, R. S. (2009). Multilevel modeling: A review of methodological issues and applications. Review of Educational Research, 79(1), 69-102. https://doi.org/10.3102/0034654308325581
Enders, C. K., & Tofighi, D. (2007). Centering predictor variables in cross-sectional multilevel models: a new look at an old issue. Psychological Methods, 12(2), 121-138. https://doi.org/10.1037/1082-989X.12.2.121
Hox, J. J., Moerbeek, M., & Van de Schoot, R. (2017). Multilevel analysis: Techniques and applications (3rd edition). Routledge.