Grundlagen der Pfadanalyse mit AMOS
Arndt Regorz, Dipl. Kfm. & MSc. Psychologie, 16.12.2024
Dieses Tutorial zeigt die Grundlagen der Pfadanalyse mit AMOS, dem SEM-Modul zu SPSS.
Video zum Tutorial
(Hinweis: Mit Anklicken des Videos wird ein Angebot des Anbieters YouTube genutzt.)
1. Modell spezifizieren (model specification)
Der erste Schritt bei einer Pfadanalyse ist es, das Modell aufzustellen.
Unser Beispielmodell hat zwei UVs, einen Mediator und zwei AVs:
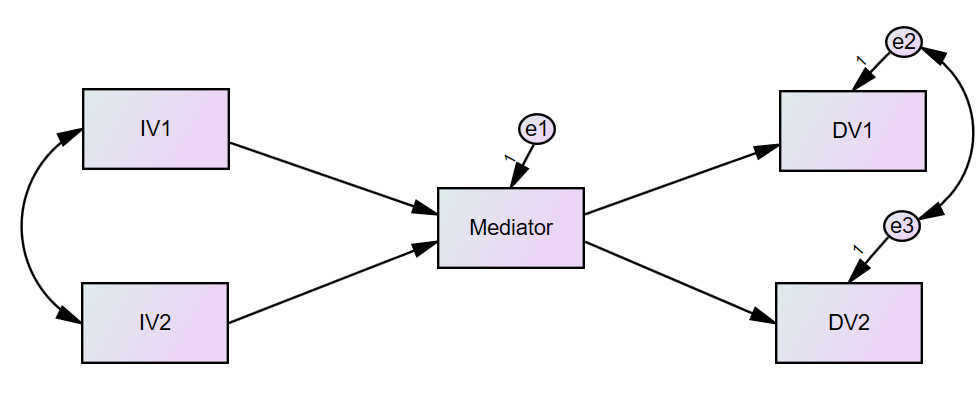
Zu Beginn laden Sie die Daten (SPSS-Datei) nach AMOS. Dafür klicken Sie auf "Select Data file(s)", das ist das Symbol in der 8. Zeile und 1. Spalte (im folgenden für weitere Symbole abgekürzt als "Z8S1").

Wenn Sie dort auf "File names" klicken, können Sie Ihre Datei auswählen. Als nächstes empfehle ich, die AMOS Datei schon einmal zu speichern (File-Save As).
Für die Anlage des Modells kann es hilfreich sein, das Eingabeformat auf Querformat umzustellen ("Landscape Din A4"), diese Einstellung finden Sie im Menü "View-Interface Properties".
Jetzt beginnt die eigentliche Modellspezifizierung. Sie zeichnen fünf Kästchen für die fünf Variablen (Symbol Z1S1). Anschließend gehen Sie auf "List variables in data set" (Z3S3) und ziehen die Variablen in die dazu gehörigen Kästchen. Als nächstes zeichnen Sie die gerichteten Pfeile zwischen UVs und Mediator sowie zwischen Mediator und AVs (Z2S1).
Für die drei endogenen Variablen, also die aus dem Modell heraus erklärten Variablen (Mediator und AVs) benötigen Sie noch Fehlerterme (=Disturbances). Dazu verwenden Sie die Funktion "Add a unique variable to an existing variable" (Z2S3) und klicken anschließend auf die jeweilige endogene Variable (Mediator oder AV). Sie sehen, dass dabei der Pfeil von der Disturbance auf die Variable mit einer 1 versehen ist (falls das mal nicht der Fall sein sollte, können Sie auf den Pfeil klicken und dann unter "Parameters-Regression Weights" eine 1 eingeben - das ist zur Modellidentifizierung notwendig). Zuletzt müssen Sie den Disturbances noch Namen geben. Dazu können Sie entweder auf diese Doppelklicken (also auf die kleinen kreisförmigen Formen) und unter "Text - Variable Name" den Variablennamen eingeben. Alternativ können Sie auch über "Plugins - Name Unobserved Variables" automatisch Namen für alle Disturbances vergeben.
Schließlich legen Sie noch die Korrelationen zwischen den beiden UVs an sowie zwischen den beiden Disturbances der AVs, mit dem Doppelpfeil-Symbol (Z2S2).
Weitere nützliche Funktionen sind das Verschieben von Variablen (Z5S2) und das Löschen von Variablen oder Pfeilen (Z5S3). Mit dem Zauberstab (Z7S3) können Sie die Variablen anklicken und damit die Pfeile ggf. etwas schöner gestalten.
Wenn Sie einen Pfad mit einem Label versehen möchten, was später z.B. für Mediationsmodelle oder generell benutzerdefinierte Effekte hilfreich sein kann, doppelklicken Sie auf den entsprechenden Pfeil und geben bei "Parameters-Regression Weights" den gewünschten Namen ein. Wichtig: Wenn Sie mehrere Pfeile mit den gleichen Namen versehen, werden diese auch exakt gleich geschätzt - damit hätten Sie also eine sog. Gleichheitsrestriktion angelegt.
2. Modelidentifizierung (model identification)
Bei der Modellidentifzierung geht es darum sicherzustellen, dass das Modell überhaupt theoretisch schätzbar ist. Das ist bei Pfadanalysen zum Glück i.d.R. ein kleineres Problem als bei CFAs und vollen SEM-Modellen.
Zum einen benötigen alle latenten Variablen eine Metrik. Im Pfadmodell sind nur die Fehlerterme/Disturbances latente Variablen und wenn jeweils deren Pfeil auf die dazugehörige gemessene endogene Variable eine 1 trägt, haben diese ihre Metrik.
Außerdem würde ich am Anfang noch zwei Grundregeln bei der Modellbildung beachten, die Identifizierungsprobleme vermeiden helfen: Ich würde keine Zyklen ins Modell einbauen (also z.B. nicht gerichtete Pfeile: Var 1 -> Var 2 -> Var 3 -> Var 1) und ich würde zwischen zwei Variablen nur eine einzige Verbindung einzeichnen (entweder Var 1 -> Var 2, oder Var 2 - Var 1, oder Korrelation zwischen den Variablen bzw. deren Disturbances).
3. Modell schätzen (model estimation)
Vor der Modellschätzung sollten Sie noch einige Voreinstellungen in den "Analysis Properties" (Z8S2) vornehmen.
Wenn Sie fehlende Werte haben, dann können Sie im Reiter "Estimation" durch auswählen von "Estimate means and intercepts" eine Schätzung mit fehlenden Werten ermöglichen (Full information maximum likelihood-Methode - hier im Beispiel nicht angeklickt, weil mein Datensatz keine fehlende Werte enthält.).

Im Reiter Output können Sie u.a. anfordern "Standardized estimates" (= betas), "Tests for normality and outliers" (Voraussetzungstests) sowie unbedingt "Modification indices" (Modifikationsindizes, also Verbesserungsvorschläge, wenn das Modell noch nicht so gut passt), wobei ich dort als "Threshold" einen Wert von 10 oder 15 einstellen würde, um nur substantielle Veränderungen vorgeschlagen zu bekommen. Ggf. können Sie auch noch Schätzungen für indirekte Effekte anfordern ("Indirect, direct & total effects").

Beim fertigen Modell (wenn der Modellfit also schon passt, nicht vorher), würde ich noch im Reiter "Bootstrap" die Haken setzen für "Perform bootstrap" und "Bias-corrected confidence intervals" sowie den Konfidenzgrad auf 95% ändern.
Über den Menüpunkt "Plugins - Standardized RMR" können Sie noch den Fit-Index SRMR anfordern, was ich empfehlen würde.
Jetzt klicken Sie auf "Calculate Estimates" (Z8S3), um das Modell zu schätzen.
4. Modelevaluation (model evaluation)
Bevor Sie die Ergebnisse der Modellschätzung interpretieren können, müssen Sie zunächst prüfen, ob Ihr Modell überhaupt zu den Daten passt. Wenn Sie auf "View Text" (Z9S2) klicken, öffnet sich ein Fenster mit dem Output.
Zunächst einmal ist es wichtig, dass der Computer überhaupt eine eindeutige Lösung für die Analyse hat finden können. Das sehen wir unter "Notes for Model (Default model)" im Unterpunkt "Result (Default model)" in der ersten Zeile:
Minimum was achieved
Chi-square = 553,000
Degrees of freedom = 4
Probability level = ,000
Die weiteren Zeilen sind die Ergebnisse des Modelltests (Chi-Quadrat-Test). Dieser Test prüft, ob das Modell exakt zu den Daten passt - was es fast nie tut. Hier zeigt sich eine signifikante Abweichung zwischen dem aufgestellten Modell und den tatsächlichen Zusammenhängen im Datensatz.
Da Modelle fast nie exakt passen, wurden im Laufe der Zeit eine Reihe sog. Fit-Indizes entwickelt, die nicht mehr den Anspruch einer exakten Modellpassung haben. Die wohl am häufigsten berichteten sind der CFI, der RMSEA und der SRMR.
Die ersten beiden finden Sie unter dem Punkt "Model Fit". Der CFI steht ganz rechts unter "Baseline Comparisons" und ist hier mit einem Wert von .721 nicht akzeptabel (nach Hu&Bentler, 1999, sollte er bei .95 oder höher liegen).
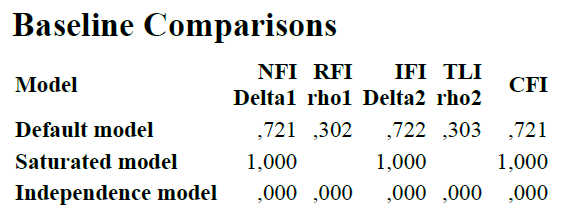
Weiter unten finden Sie den RMSEA. Dieser sollte bei unter .06 liegen (wobei es dort in der Literatur unterschiedliche Cut-Offs gibt) und liegt hier mit .812 viel zu hoch. Allerdings ist der RMSEA bei einem Modell mit nur wenigen Freiheitsgraden nicht zuverlässig interpretierbar, siehe Tutorial Probleme mit dem RMSEA .
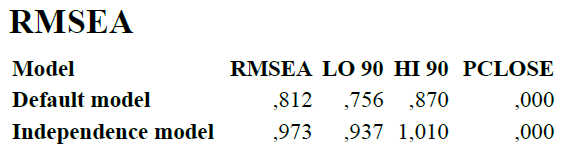
Den SRMR findet man unter "Plugins - Standardized RMR", wenn man ihn dort vor der Modellschätzung angefordert hat. Der Wert von .1278 liegt deutlich über dem Cut-Off von .08.
Insgesamt haben wir also einen schlechten Modell-Fit. Sowohl der Modelltest war signifikant als auch alle Fit-Indizes schlechter als gefordert. Daher können wir die Ergebnisse dieses Modells nicht interpretieren und müssen sie uns daher nicht ansehen.
Neben dem Global Fit, also ob das Modell insgesamt passt, ist auch der Local Fit relevant: In welchen Teilen passt das Modell (nicht) zu den Daten? Das gibt uns gleichzeitig Hinweise dafür, wo man das Modell u.U. verbessern könnte.
Dafür betrachten wir die von uns in AMOS angeforderten Modifikationsindizes (MI) - im Output unter "Modification Indices".
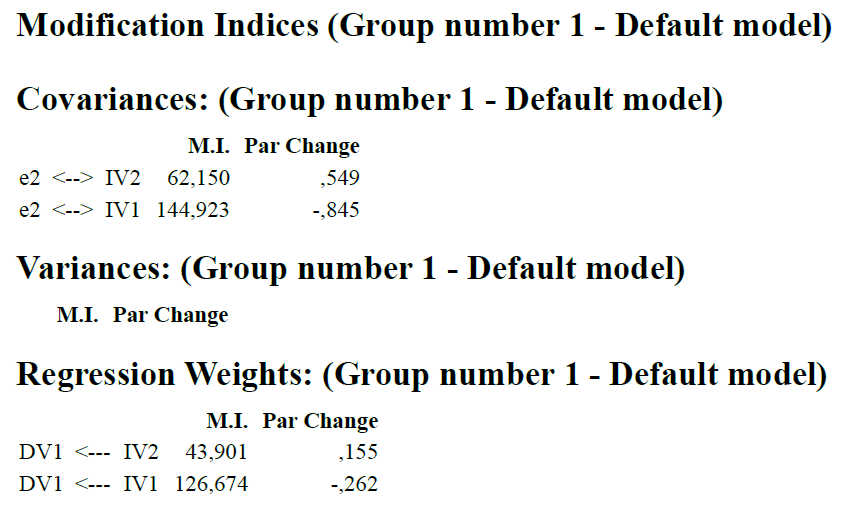
In unserem Beispiel gibt es zwei Arten von möglichen Verbesserungen: Kovarianzen (Doppelpfeile) und Regressionsgewichte (gerichtete Pfeile). Allerdings sind die Kovarianzen zwischen UVs und Fehlertermen theoretisch kaum begründbar. Die beiden vorgeschlagenen zusätzlichen Regressionspfade hingegen sind theoretisch durchaus sinnvoll, weil beide je einen direkten Effekt von einer UV auf eine AV vorschlagen - in Mediationen ist es häufig der Fall, dass man neben einem indirekten Effekt auch einen direkten Effekt von UV auf AV hat.
Neben der theoretischen Begründbarkeit der Modelländerung ist noch ein zweiter Punkt bei der Modellanpassung wichtig: Man nimmt i.d.R. nur einen Änderung zur Zeit vor, da häufig ein einziges Datenproblem sich an mehreren Stellen im Modell zeigt und daher auch eine einzige Änderung mehrere Modifikationsindizes zum Verschwinden bringen kann. Hier ist der vorgeschlagene Pfad von IV1 auf DV1 mit einem deutlich größeren MI versehen, 126.674. Daher würden Sie im nächsten Schritt jetzt diesen Pfad zusätzlich zulassen.
5. Modellrespezifikation (model respecification)
Nun ergänzen Sie einfach noch Ihr Modell um einen Pfeil von IV1 auf DV1 und speichern das neue Modell am besten unter einem neuen Namen. Bevor Sie einen neuen Pfeil einzeichnen können, müssen Sie vom Output-Pfaddiagramm (mit den Schätzergebnissen) umstellen auf das Input-Pfadiagramm (Symbole unterhalb der Menüleiste, unterhalb von "Analyze").
Hier ist jetzt unser neues Modell:
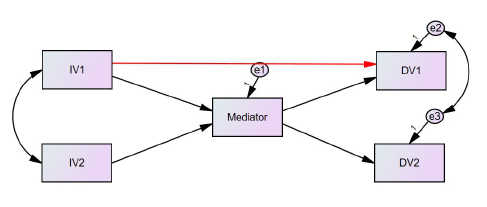
Jetzt klicken Sie auf die Modellschätzung in AMOS und lassen sich anschließend den Output anzeigen.
Minimum was achieved
Chi-square = 37,168
Degrees of freedom = 3
Probability level = ,000
Der Modelltest ist zwar immer noch signifikant, hat sich aber deutlich verbessert (im vorherigen Modell war der Chi-Quadrat-Wert bei 4 Freiheitsgraden noch 553.0).
Als CFI erhalten Sie jetzt einen guten Wert von .983, als SRMR einen sehr guten Wert von .01. Der RMSEA (.234) ist bei so wenigen Freiheitsgraden nicht sinnvoll interpretierbar. Insofern haben Sie jetzt auf Basis der Fit-Indizes einen guten Modellfit und können uns im nächsten Schritt die Ergebnisse ansehen.
Bevor wir das tun, sollten Sie sich noch kurz den Test der Voraussetzungen ansehen ("Assessment of normality").
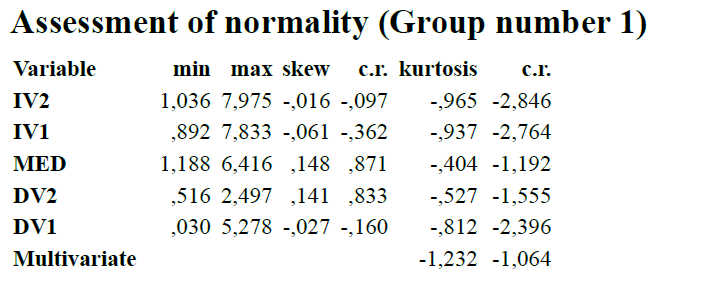
Hierbei sind c.r.-Werte (Critical Ratios = Kritische Werte) über 1.96 als signifikant anzusehen. Sie sehen, dass die Schiefe (skew) unproblematisch ist, und auch die multivariate Kurtosis. Jedoch haben wir mehrere Variablen, bei denen univariat die Kurtosis signifikant geworden ist. Insofern könnte man zur Absicherung noch eine Schätzung mit Bootstrapping anfordern (was ich bei indirekten Effekten auf jeden Fall empfehlen würde).
Bei den "Analysis properties" (Z8S2) setzen Sie im Reiter "Bootstrap" die Haken für "Perform bootstrap" und für "Bias corrected confidence intervals". Außerdem würde ich für einen zweiseitigen Test den "BC confidence level" noch auf 95 anpassen (hier noch nicht umgesetzt).

6. Modellinterpretation (model interpretation)
Wenn Sie einen guten Modellfit erzielt haben, können Sie jetzt die Ergebnisse interpretieren. In der graphischen Darstellung finden Sie zunächst die unstandardisierten Pfadkoeffizienten:
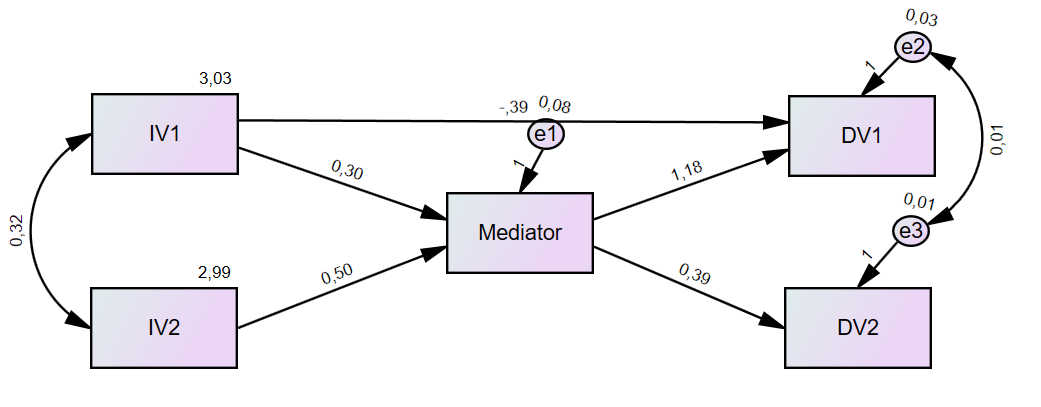
Man kann jedoch auch umschalten auf die Anzeige der standardisierten Pfadkoeffizienten:
Im Output unter "Estimates" finden Sie jetzt die Schätzergebnisse, getrennt für unstandardisierte und standardisierte. C.R. ist hier wieder die Critical Ratio, also die Z-Statistik. Entscheidend für unser Pfadmodell sind die Regression Weights.
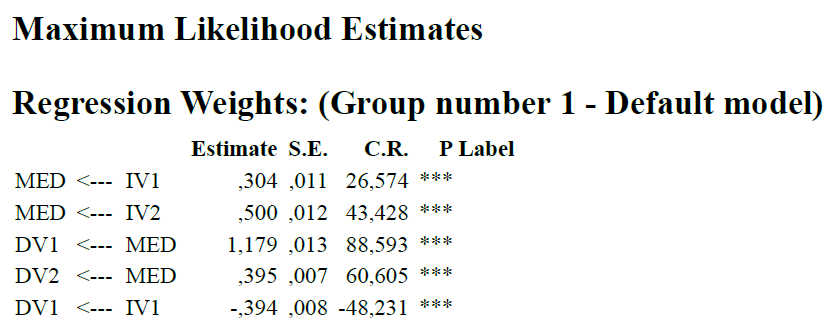

Um zu den Bootstrap-Ergebnissen zu kommen, die nicht auf die Voraussetzung der Normalverteilung aufbauen, müssen Sie sich unter "Estimates" durchklicken bis zu den genauen Detailergebnissen, die Sie interessieren (z.B. "Regression Weights").
Dann können Sie anschließend unten links auf die Bootstrap-Ergebnisse klicken.

Wenn Sie dort auf "Bootstrap confidence" klicken, erhalten Sie eine Tabelle mit den Bootstrap-Konfidenzintervallen ("Lower" = Untergrenze, "Upper" = Obergrenze) für Ihre Schätzung, hier für die Pfadkoeffizienten. Signifikant ist ein Pfad, wenn das Konfidenzintervall die Null nicht einschließt (wenn also entweder beide Grenzen negativ oder beide Grenzen positiv sind).
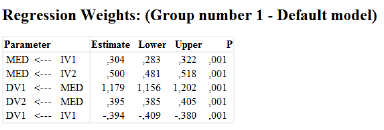
Und damit können Sie die Ergebnisse Ihres Pfadmodells berichten.
Als weiterführende Literatur empfehle ich Ihnen das Standardwerk von B. Byrne (2016) zur SEM-Modellierung mit AMOS.
Literatur
Byrne, B. M. (2016). Structural equation modeling with AMOS: Basic concepts, applications, and programming. Routledge.
Hu, L. T., & Bentler, P. M. (1999). Cutoff criteria for fit indexes in covariance structure analysis: Conventional criteria versus new alternatives. Structural Equation Modeling, 6(1), 1-55. https://doi.org/10.1080/10705519909540118
Kline, R. B. (2023). Principles and practice of structural equation modeling (5th ed.). Guilford publications.